杂谈 什么是伪共享(false sharing)?
问题
(1)什么是 CPU 缓存行?
(2)什么是内存屏障?
(3)什么是伪共享?
(4)如何避免伪共享?
CPU缓存架构
CPU 是计算机的心脏,所有运算和程序最终都要由它来执行。
主内存(RAM)是数据存放的地方,CPU 和主内存之间有好几级缓存,因为即使直接访问主内存也是非常慢的。
如果对一块数据做相同的运算多次,那么在执行运算的时候把它加载到离 CPU 很近的地方就有意义了,比如一个循环计数,你不想每次循环都跑到主内存去取这个数据来增长它吧。
越靠近 CPU 的缓存越快也越小。
所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核。
L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。
L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。
最后,主存保存着程序运行的所有数据,它更大,更慢,由全部插槽上的所有 CPU 核共享。
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。
走得越远,运算耗费的时间就越长。
所以如果进行一些很频繁的运算,要确保数据在 L1 缓存中。
CPU缓存行
缓存是由缓存行组成的,通常是 64 字节(常用处理器的缓存行是 64 字节的,比较旧的处理器缓存行是 32 字节),并且它有效地引用主内存中的一块地址。
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
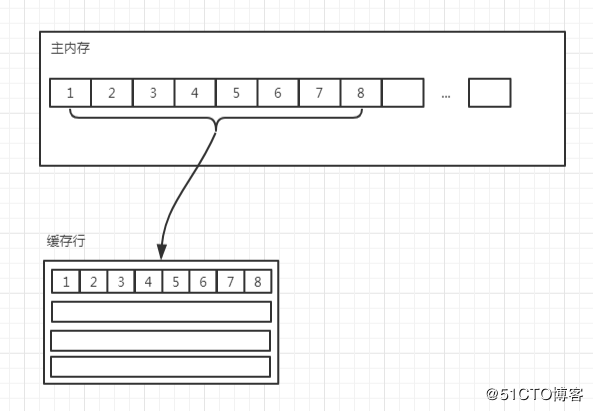
在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中。
但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
不过,这种免费加载也有一个坏处。设想如果我们有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。
看起来似乎没有什么毛病,但是如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取。
当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。
而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。
请记住,我们的缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。
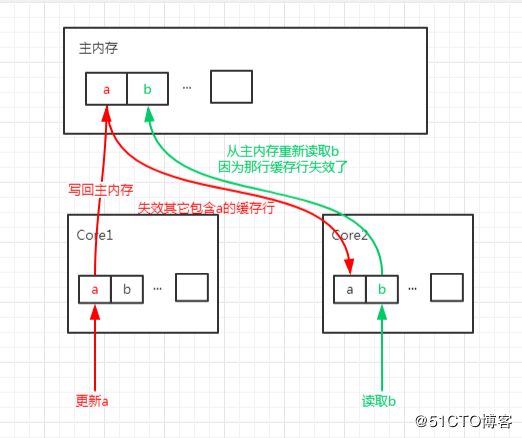
这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取,它被缓存未命中给拖慢了。
这就是传说中的伪共享。
伪共享
好了,上面介绍完CPU的缓存架构及缓存行机制,下面进入我们的正题——伪共享。
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
我们来看看下面这个例子,充分说明了伪共享是怎么回事。
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}}
class Pointer {
volatile long x;
volatile long y;
}
复制代码
这个例子中,我们声明了一个 Pointer 的类,它包含 x 和 y 两个变量(必须声明为volatile,保证可见性,关于内存屏障的东西我们后面再讲),一个线程对 x 进行自增1亿次,一个线程对 y 进行自增1亿次。
可以看到,x 和 y 完全没有任何关系,但是更新 x 的时候会把其它包含 x 的缓存行失效,同时也就失效了 y,运行这段程序输出的时间为3890ms。
避免伪共享
伪共享的原理我们知道了,一个缓存行是 64 个字节,一个 long 类型是 8 个字节,所以避免伪共享也很简单,笔者总结了下大概有以下三种方式:
(1)在两个 long 类型的变量之间再加 7 个 long 类型
我们把上面的Pointer改成下面这个结构:
class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
复制代码
再次运行程序,会发现输出时间神奇的缩短为了695ms。
(2)重新创建自己的 long 类型,而不是 java 自带的 long
修改Pointer如下:
class Pointer {
MyLong x = new MyLong();
MyLong y = new MyLong();
}
class MyLong {
volatile long value;
long p1, p2, p3, p4, p5, p6, p7;
}
复制代码
同时把 pointer.x++; 修改为 pointer.x.value++;,把 pointer.y++; 修改为 pointer.y.value++;,再次运行程序发现时间是724ms。
(3)使用 @sun.misc.Contended 注解(java8)
修改 MyLong 如下:
@sun.misc.Contended
class MyLong {
volatile long value;
}
复制代码
默认使用这个注解是无效的,需要在JVM启动参数加上-XX:-RestrictContended才会生效,,再次运行程序发现时间是718ms。
注意,以上三种方式中的前两种是通过加字段的形式实现的,加的字段又没有地方使用,可能会被jvm优化掉,所以建议使用第三种方式。
总结
(1)CPU具有多级缓存,越接近CPU的缓存越小也越快;
(2)CPU缓存中的数据是以缓存行为单位处理的;
(3)CPU缓存行能带来免费加载数据的好处,所以处理数组性能非常高;
(4)CPU缓存行也带来了弊端,多线程处理不相干的变量时会相互影响,也就是伪共享;
(5)避免伪共享的主要思路就是让不相干的变量不要出现在同一个缓存行中;
(6)一是每两个变量之间加七个 long 类型;
(7)二是创建自己的 long 类型,而不是用原生的;
(8)三是使用 java8 提供的注解;
彩蛋
java中有哪些类避免了伪共享的干扰呢?
还记得我们前面介绍过的 ConcurrentHashMap 的源码解析吗?
里面的 size() 方法使用的是分段的思想来构造的,每个段使用的类是 CounterCell,它的类上就有 @sun.misc.Contended 注解。
不知道的可以关注我的公众号“彤哥读源码”查看历史消息找到这篇文章看看。
除了这个类,java中还有个 LongAdder 也使用了这个注解避免伪共享,下一章我们将一起学习 LongAdder 的源码分析,敬请期待。
你还知道哪些避免伪共享的应用呢?
转载于 https://juejin.im/post/5cd644886fb9a032136fe6d7