小编说:视觉SLAM 是指用相机解决定位和建图问题。本文以一个小机器人为例形象地介绍了视觉SLAM的功能及特点。
SLAM 是Simultaneous Localization and Mapping 的缩写,中文译作“同时定位与地图构建”。它是指搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建立环境的模型,同时估计自己的运动。如果这里的传感器主要为相机,那就称为“视觉SLAM”。
为了方便大家理解,假设我们组装了一台叫作“小萝卜”的机器人,大概的样子如下所示。设备有相机、轮子、笔记本,手是装饰品。
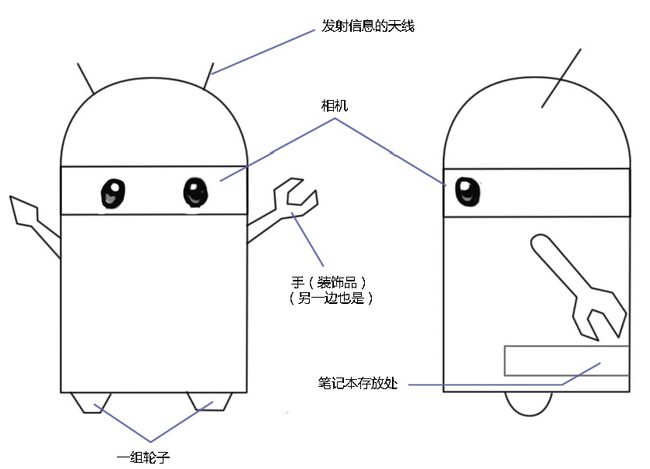
虽然有点像“安卓”,但它并不是靠安卓系统来计算的。我们把一台笔记本塞进了它的后备箱内(方便我们随时拿出来调试程序)。它能做点什么呢?
我们希望小萝卜具有自主运动能力。虽然世界上也有放在桌面像摆件一样的机器人,能够和人说话或播放音乐,不过一台平板电脑完全可以胜任这些事情。作为机器人,我们希望小萝卜能够在房间里自由移动。不管我们在哪里招呼一声,它都会滴溜溜地走过来。
要移动首先得有轮子和电机,所以我们在小萝卜的下方安装了轮子(足式机器人步态很复杂,我们暂时不考虑)。有了轮子,机器人就能够四处行动了,但不加控制的话,小萝卜不知道行动的目标,就只能四处乱走,更糟糕的情况下会撞上墙造成损毁。为了避免这种情况的发生,我们在它的脑袋上安装了一个相机。安装相机的主要动机,是考虑到这样一个机器人和人类非常相似——从画面上一眼就能看出。有眼睛、大脑和四肢的人类,能够在任意环境里轻松自在地行走、探索,我们(天真地)觉得机器人也能够完成这件事。为了使小萝卜能够探索一个房间,它至少需要知道两件事:
我在什么地方?——定位。
周围环境是什么样?——建图。
“定位”和“建图”,可以看成感知的“内外之分”。作为一个“内外兼修”的小萝卜,一方面要明白自身的状态(即位置),另一方面也要了解外在的环境(即地图)。当然,解决这两个问题的方法非常多。比方说,我们可以在房间地板上铺设导引线,在墙壁上贴识别二维码,在桌子上放置无线电定位设备。如果在室外,还可以在小萝卜脑袋上安装定位设备(像手机或汽车一样)。有了这些东西之后,定位问题是否已经解决了呢?我们不妨把这些传感器分为两类。
一类传感器是携带于机器人本体上的,例如机器人的轮式编码器、相机、激光传感器,等等。另一类是安装于环境中的,例如前面讲的导轨、二维码标志,等等。安装于环境中的传感设备,通常能够直接测量到机器人的位置信息,简单有效地解决定位问题。然而,由于它们必须在环境中设置,在一定程度上限制了机器人的使用范围。比方说,有些地方没有GPS信号,有些地方无法铺设导轨,这时该怎么做定位呢?

(a)利用二维码进行定位的增强现实软件;(b)GPS定位装置;(c)铺设导轨的小车;(d)激光雷达;(e)IMU单元;(f)双目相机。
我们看到,这类传感器约束了外部环境。只有在这些约束满足时,基于它们的定位方案才能工作。反之,当约束无法满足时,我们就没法进行定位了。所以说,虽然这类传感器简单可靠,但它们无法提供一个普遍的、通用的解决方案。相对地,那些携带于机器人本体上的传感器,比如激光传感器、相机、轮式编码器、惯性测量单元(Inertial Measurement Unit,IMU)等,它们测到的通常都是一些间接的物理量而不是直接的位置数据。例如,轮式编码器会测到轮子转动的角度,IMU测量运动的角速度和加速度,相机和激光传感器则读取外部环境的某种观测数据。我们只能通过一些间接的手段,从这些数据推算自己的位置。虽然这听上去是一种迂回战术,但更明显的好处是,它没有对环境提出任何要求,从而使得这种定位方案可适用于未知环境。
我们在SLAM中非常强调未知环境。在理论上,我们没法限制小萝卜的使用环境,这意味着我们没法假设像GPS这些外部传感器都能顺利工作。因此,使用携带式的传感器来完成SLAM是我们重点关心的问题。特别地,当谈论视觉SLAM时,我们主要是指如何用相机解决定位和建图问题。
那么小萝卜的眼睛能够做些什么事?SLAM中使用的相机与我们平时见到的单反摄像头并不是同一个东西。它往往更加简单,不携带昂贵的镜头,而是以一定速率拍摄周围的环境,形成一个连续的视频流。普通的摄像头能以每秒钟30张图片的速度采集图像,高速相机则更快一些。按照工作方式的不同,相机可以分为单目相机(Monocular)、双目相机(Stereo)和深度相机(RGB-D)三大类,如所示。直观看来,单目相机只有一个摄像头,双目有两个,而RGB-D原理较复杂,除了能够采集到彩色图片之外,还能读出每个像素与相机之间的距离。深度相机通常携带多个摄像头,工作原理和普通相机不尽相同,在第5讲会详细介绍其工作原理,此处读者只需有一个直观概念即可。此外,SLAM中还有全景相机、Event相机等特殊或新兴的种类。虽然偶尔能看到它们在SLAM中的应用,不过到目前为止还没有成为主流。从样子上看,小萝卜使用的似乎是双目相机(画成单目会比较吓人)。

我们来分别看一看各种相机用来做SLAM时有什么特点。
单目相机
只使用一个摄像头进行SLAM的做法称为单目SLAM(Monocular SLAM)。这种传感器结构特别简单,成本特别低,所以单目SLAM非常受研究者关注。你肯定见过单目相机的数据:照片。是的,作为一张照片,它有什么特点呢?
照片本质上是拍照时的场景(Scene)在相机的成像平面上留下的一个投影。它以二维的形式反映了三维的世界。显然,这个过程丢掉了场景的一个维度,也就是所谓的深度(或距离)。在单目相机中,我们无法通过单张图片来计算场景中物体与我们之间的距离(远近)。之后我们会看到,这个距离将是SLAM中非常关键的信息。由于我们人类见过大量的图像,形成了一种天生的直觉,对大部分场景都有一个直观的距离感(空间感),它可以帮助我们判断图像中物体的远近关系。比如说,我们能够辨认出图像中的物体,并且知道其大致的大小;比如,近处的物体会挡住远处的物体,而太阳、月亮等天体一般在很远的地方;再如,物体受光照后会留下影子,等等。这些信息都可以帮助我们判断物体的远近,但也存在一些情况会使这种距离感失效,这时我们就无法判断物体的远近及其真实大小了。 下图所示就是这样一个例子。在这张图像中,我们无法仅通过它来判断后面那些小人是真实的人,还是小型模型。除非我们转换视角,观察场景的三维结构。换言之,在单张图像里,你无法确定一个物体的真实大小。它可能是一个很大但很远的物体,也可能是一个很近但很小的物体。由于近大远小的原因,它们可能在图像中变成同样大小的样子。

由于单目相机拍摄的图像只是三维空间的二维投影,所以,如果真想恢复三维结构,必须改变相机的视角。在单目SLAM中也是同样的原理。我们必须移动相机,才能估计它的运动(Motion),同时估计场景中物体的远近和大小,不妨称之为结构(Structure)。那么,怎么估计这些运动和结构呢?从生活经验中我们知道,如果相机往右移动,那么图像里的东西就会往左边移动——这就给我们推测运动带来了信息。另一方面,我们还知道:近处的物体移动快,远处的物体则运动缓慢。于是,当相机移动时,这些物体在图像上的运动就形成了视差。通过视差,我们就能定量地判断哪些物体离得远,哪些物体离得近。
然而,即使我们知道了物体远近,它们仍然只是一个相对的值。比如我们在看电影时,虽然能够知道电影场景中哪些物体比另一些大,但无法确定电影里那些物体的“真实尺度”:那些大楼是真实的高楼大厦,还是放在桌上的模型?而摧毁大厦的是真实怪兽,还是穿着特摄服装的演员?直观地说,如果把相机的运动和场景大小同时放大两倍,单目相机所看到的像是一样的。同样地,把这个大小乘以任意倍数,我们都将看到一样的景象。这说明,单目SLAM估计的轨迹和地图将与真实的轨迹和地图相差一个因子,也就是所谓的尺度(Scale)。由于单目SLAM无法仅凭图像确定这个真实尺度,所以又称为尺度不确定性。
平移之后才能计算深度,以及无法确定真实尺度,这两件事情给单目SLAM的应用造成了很大的麻烦。其根本原因是通过单张图像无法确定深度。所以,为了得到这个深度,人们开始使用双目和深度相机。
双目相机和深度相机
使用双目相机和深度相机的目的,在于通过某种手段测量物体与我们之间的距离,克服单目相机无法知道距离的缺点。一旦知道了距离,场景的三维结构就可以通过单个图像恢复出来,也就消除了尺度不确定性。尽管都是为了测量距离,但双目相机与深度相机测量深度的原理是不一样的。双目相机由两个单目相机组成,但这两个相机之间的距离﹝称为基线(Baseline)﹞是已知的。我们通过这个基线来估计每个像素的空间位置——这和人眼非常相似。我们人类可以通过左右眼图像的差异判断物体的远近,在计算机上也是同样的道理。如果对双目相机进行拓展,也可以搭建多目相机,不过本质上并没有什么不同。

计算机上的双目相机需要大量的计算才能(不太可靠地)估计每一个像素点的深度,相比于人类真是非常笨拙。双目相机测量到的深度范围与基线相关。基线距离越大,能够测量到的就越远,所以无人车上搭载的双目通常会是个很大的家伙。双目相机的距离估计是比较左右眼的图像获得的,并不依赖其他传感设备,所以它既可以应用在室内,亦可应用于室外。双目或多目相机的缺点是配置与标定均较为复杂,其深度量程和精度受双目的基线与分辨率所限,而且视差的计算非常消耗计算资源,需要使用GPU和FPGA设备加速后,才能实时输出整张图像的距离信息。因此在现有的条件下,计算量是双目的主要问题之一。
深度相机(又称RGB-D相机,在本书中主要使用RGB-D这个名称)是2010年左右开始兴起的一种相机,它最大的特点是可以通过红外结构光或Time-of-Flight(ToF)原理,像激光传感器那样,通过主动向物体发射光并接收返回的光,测出物体与相机之间的距离。这部分并不像双目相机那样通过软件计算来解决,而是通过物理的测量手段,所以相比于双目相机可节省大量的计算。目前常用的RGB-D相机包括Kinect/Kinect V2、Xtion Pro Live、RealSense等。不过,现在多数RGB-D相机还存在测量范围窄、噪声大、视野小、易受日光干扰、无法测量透射材质等诸多问题,在SLAM方面,主要用于室内,室外则较难应用。

我们讨论了几种常见的相机,相信通过以上的说明,你已经对它们有了直观的了解。现在,想象相机在场景中运动的过程,我们将得到一系列连续变化的图像(你可以用手机录个小视频试试)。视觉SLAM的目标,是通过这样的一些图像,进行定位和地图构建。这件事情并没有我们想象的那么简单。它不是某种算法,只要我们输入数据,就可以往外不断地输出定位和地图信息了。SLAM需要一个完善的算法框架,而经过研究者们长期的努力工作,现有这个框架已经定型了。关于框架我们以后再聊~
本文选自《视觉SLAM十四讲:从理论到实践》一书,感兴趣的小伙伴不妨到书中去一探究竟~
《视觉SLAM十四讲:从理论到实践》

首著问世,国内作者原创SLAM技术书,从基础理论到代码实现,余凯、谭平等大咖好评!
作者:高翔、张涛、刘毅、颜沁睿
图书链接:京东、当当、亚马逊