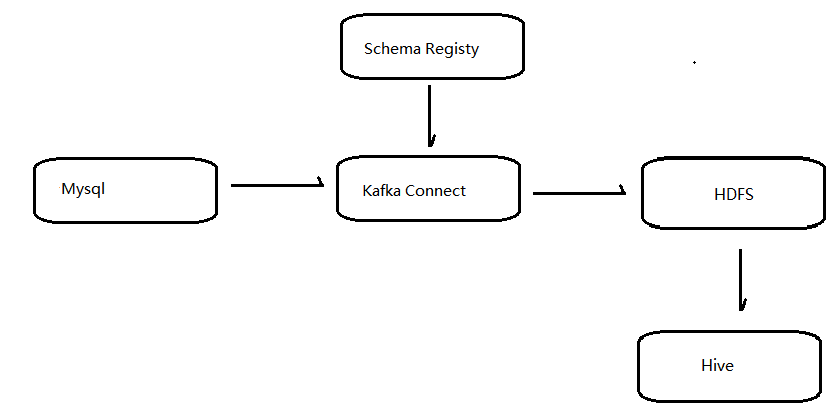
KAFKA
使用kafa作为ETL数据通道,通过kafka配套的connect和schemaRegisty来方便快速实现异构数据源的相互转换和存储,通过connect插件生产和消费数据,通过schemaRegisty转换异构数据(可以在几乎所有你知道的数据源之间相互转换),并且数据可以重复被消费(可以通过配置指定数据存储时长)。kafka的开发团队围绕着kafka开发了一整套自成体系的生态圈(confluent platform)。
Building a Scalable ETL Pipeline with Kafka Connect In 30 Minutes
优点:
可扩展。Kafka集群可以透明的扩展,增加新的服务器进集群。
高性能。Kafka性能远超过传统的ActiveMQ、RabbitMQ等,Kafka支持Batch操作。
容错性。Kafka每个Partition数据会复制到几台服务器,当某个Broker失效时,Zookeeper将通知生产者和消费者从而使用其他的Broker。
缺点:
重复消息。Kafka保证每条消息至少送达一次,虽然几率很小,但一条消息可能被送达多次。
消息乱序。Kafka某一个固定的Partition内部的消息是保证有序的,如果一个Topic有多个Partition,partition之间的消息送达不保证有序。
复杂性。Kafka需要Zookeeper的支持,Topic一般需要人工创建,部署和维护比一般MQ成本更高。
MQ
消息队列中间件还有很多种,列举几个:
RocketMq,是阿里在充分reviewkafka代码后,开发的metaQ。在不断更新,修补以后,阿里把metaQ3.0更名为rocket,并且rocket是java写的易于维护。
RabbitMQ,支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
REDIS
Redis 的有序集合用来做队列还是不错的,用来实现做简单的任务队列,性能不错,也有持久化(rdb/aof) 但是发布、消费等的确认需要自己实现,所以redis得使用还是建议把它当内存数据库来吧。
Kafka

kafka是个日志处理缓冲组件,主要在大数据信息处理中使用。和传统的消息队列相比简化了队列结构和功能,以文件流形式处理存储(持久化)消息(主要是日志)。
日志信息通常数据量巨大,处理组件一般会处理不过来,所以有了缓冲层kafka。kafka支持巨大的日志吞吐量。为了防止数据丢失,其消息被消费后不会直接丢弃,要多存储一段时间,等超过设置的时间阈值才会丢弃。这是mq和redis所不具备的。
主要特点如下:
巨型存储量: 支持TB甚至PB级别数据。
高吞吐,高IO:一般配置的服务器就可实现单机每秒100K条以上的消息传输。
消息分区,分布式消费:能保证消息顺序传输。 支持离线数据处理(hadoop集群)和实时数据处理。
横向扩展:支持在线水平扩展,以支持更大数据处理能力。
redis
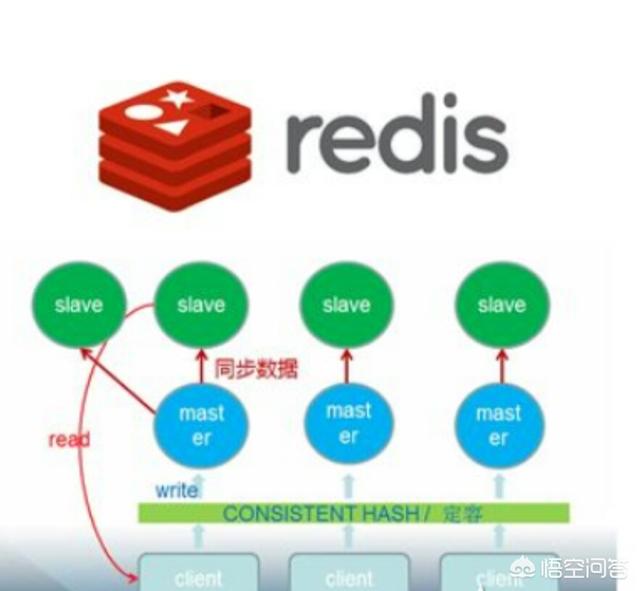
redis是一个高性能的、原子操作的内存键值对nosql。支持高速访问,可用做消息队列的存储,但是不具备消息队列的任何功能和逻辑,要做为消息队列来使用的话,队列功能和逻辑要通过上层应用来自己实现。
MQ,消息队列
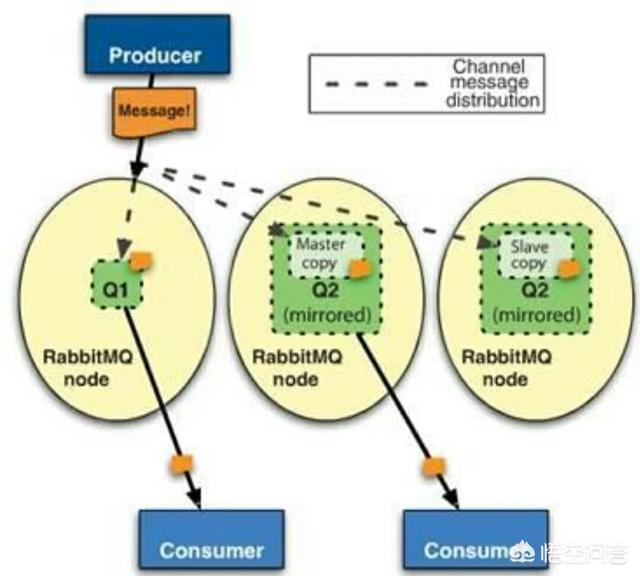
我们以RabbitMQ为例来做介绍。它是用Erlang语言开发的开源消息队列,支持多种协议包括AMQP,XMPP, SMTP, STOMP,适合于企业级的开发。
MQ支持Broker构架,消息发送给客户端时需要在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
其他更多消息队列
还有ActiveMq,ZeroMq等,功能上大同小异。
有专门测试的结果表明,并发吞吐TPS比较,ZeroMq 最好,RabbitMq 次之, ActiveMq 最差。