1. 引言
爬取本地一个网页的内容,具体要求如下
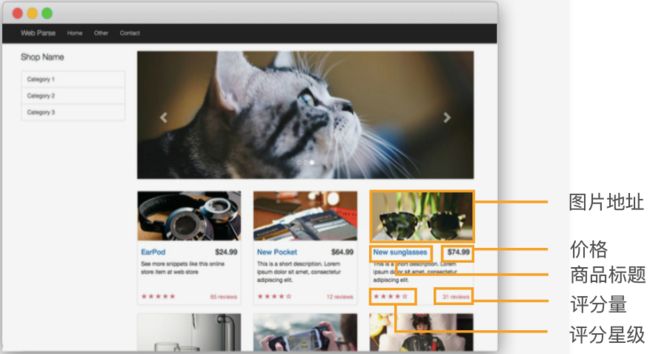
Paste_Image.png
2. 准备
- 借助模块bs4中的
BeautifulSoup函数,lxml库来解析网页
安装:
- CentOS: 从官网下载
python3源码,编译安装再将bin文件夹的绝对路径加入/etc/profile.d/python3.sh,即可得python3、pip3
安装bs4模块:sudo pip3 install bs4
安装lxml库:sudo pip3 install lxml - Ubuntu: 从官方编译好的库中直接用
apt命令安装,简单方便
安装python3:sudo apt install python3
安装pip3:sudo apt install python3-pip
安装bs4:sudo pip3 install bs4
安装lxml:sudo pip3 install lxml
3. 分析
- 右键单击要获取元素,点击检查元素即可得到其在网页中的路径
- 使用
len方法获取list的长度来取得星星数量 - 将数据放入字典
dict
代码如下:
# vim homework.py //用vim新建文件`homework.py`
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = 'jhw'
# 从bs4模块导入BeautifulSoup函数
from bs4 import BeautifulSoup
# 将本次要打开文件的路径赋值给path变量,此为相对路径,和本文件同级
path = 'index.html'
def get_web(path):
# 只读方式打开网页
with open(path, 'r') as f:
# 读取文件内容
wb_data = f.read()
# 用lxml解析见面内容
soup = BeautifulSoup(wb_data, 'lxml')
# 获取标题
titles = soup.select('div > div > div.col-md-9 > div > div > div > div.caption > h4 > a')
# 获取图片
imgs = soup.select('div > div > div.col-md-9 > div > div > div > img')
# 获取价格
prices = soup.select('div > div > div.col-md-9 > div > div > div > div.caption > h4.pull-right')
# 获取评分量
reviews = soup.select('div > div > div.col-md-9 > div > div > div > div.ratings > p.pull-right')
# 获取星级
stars = soup.select('div > div > div.col-md-9 > div > div > div > div.ratings > p:nth-of-type(2)')
# zip函数: for后面变量的个数和zip函数里的变量数量相同,即一次次分别从对应变量的对应位置取值
for title, img, price, review, star in zip(titles, imgs, prices, reviews, stars):
data = {
'title': title.get_text(),
'img': img.get('src'),
'price': price.get_text(),
'review': review.get_text().split(' ')[0],
# 获取星星数量即为星级
'star': len(star.find_all('span', 'glyphicon glyphicon-star')),
}
print(data)
# 引用函数,传入path参数
get_web(path)
# python3 homework.py //运行结果如下
{'price': '$24.99', 'star': 5, 'img': 'img/pic_0000_073a9256d9624c92a05dc680fc28865f.jpg', 'review': '65', 'title': 'EarPod'}
{'price': '$64.99', 'star': 4, 'img': 'img/pic_0005_828148335519990171_c234285520ff.jpg', 'review': '12', 'title': 'New Pocket'}
{'price': '$74.99', 'star': 4, 'img': 'img/pic_0006_949802399717918904_339a16e02268.jpg', 'review': '31', 'title': 'New sunglasses'}
{'price': '$84.99', 'star': 3, 'img': 'img/pic_0008_975641865984412951_ade7a767cfc8.jpg', 'review': '6', 'title': 'Art Cup'}
{'price': '$94.99', 'star': 4, 'img': 'img/pic_0001_160243060888837960_1c3bcd26f5fe.jpg', 'review': '18', 'title': 'iphone gamepad'}
{'price': '$214.5', 'star': 4, 'img': 'img/pic_0002_556261037783915561_bf22b24b9e4e.jpg', 'review': '18', 'title': 'Best Bed'}
{'price': '$500', 'star': 4, 'img': 'img/pic_0011_1032030741401174813_4e43d182fce7.jpg', 'review': '35', 'title': 'iWatch'}
{'price': '$15.5', 'star': 4, 'img': 'img/pic_0010_1027323963916688311_09cc2d7648d9.jpg', 'review': '8', 'title': 'Park tickets'}
4. 总结
- BeautifulSoup是大神写好的第三方库, 安装好拿来就能解析网页代码
- lxml用来分析网页代码结构
- 取得具体元素可以用
select和find_all等方法,且取得的数据是一个list - 当几个
list中的元素个数相同时可以用zip函数实现代码的简化却能实现复杂的功能