Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取中国气象网的天气情况(泉州地区)
2.主题式网络爬虫爬取的内容与数据特征分析
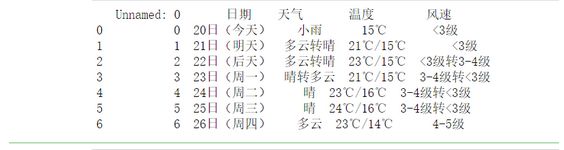
爬取当日的天气,温度,风速等信息;
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本案例使用requests库获取网页数据,使用beautifulSoup库解析页面内容,再使用pandas数据存储库把爬取的数据输出。
技术难点:数据存储、读取、创建数据帧。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
泉州地区编号位置
2.Htmls页面解析

目标信息存在class=”t clearfix” 的ul标签中,日期在 标签中;标签中,天气信息在class="wea"的
温度信息在class="tem"的 标签中;风速在class="win"的 标签中。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
根据上面对页面的分析,只要使用find_all()方法进行查找即可
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
def getHTMLText(url): try: #获取目标页面 r = requests.get(url) #判断页面是否链接成功 r.raise_for_status() #使用HTML页面内容中分析出的响应内容编码方式 r.encoding = r.apparent_encoding #返回页面内容 return r.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
2.对数据进行清洗和处理
#爬取数据 def getData(dayList,weatherList,temperatureList,windList,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser")
for ul in soup.find_all("ul",{"class":"t clearfix"}): #获取日期 for h1 in ul.find_all('h1'): #将日期存在dayList列表中 dayList.append(h1.string) #获取天气信息 for p in ul.find_all('p',{"class":"wea"}): #将天气信息存在weatherList列表中 weatherList.append(p.string) #获取温度信息 for p in ul.find_all('p',{"class":"tem"}): #将温度信息存在temperatureList列表中 temperatureList.append(p.get_text().strip()) #获取风速信息 for p in ul.find_all('p',{"class":"win"}): #将风速信息存在windList列表中 windList.append(p.i.string) #创建文件夹 def makeMkdir(): try: #创建文件夹 os.mkdir("D:\中国天气网") except: #如果文件夹存在则什么也不做 ""
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
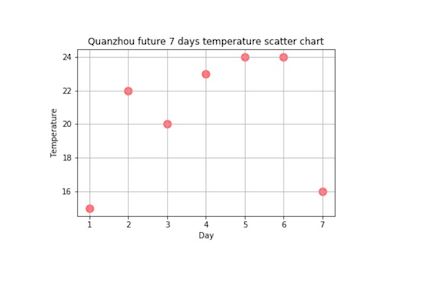
#数据可视化 def dataFigure(dataLiat1): x = [i for i in range(1,8)] #圆点大小 size = 100 # 绘制散点图, alpha=0.5表示透明度 plt.scatter(x, dataLiat1, size, color="r", alpha=0.5, marker='o') #x轴标题 plt.xlabel("Day") #y轴标题 plt.ylabel("Temperature") #图片标题 plt.title("Quanzhou future 7 days temperature scatter chart") # 添加网格 plt.grid() #保存图片 savefig("D:\\中国天气网\\7日温度图.jpg") plt.show()
5.数据持久化
def pdSaveRead(dayList,weatherList,temperatureList,windList): #创建numpy数组 r = np.array([dayList,weatherList,temperatureList,windList]) #columns(列)名 columns_title = ['日期','天气','温度','风速'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel(r'D:\中国天气网\7日天气情况表.xls',columns = columns_title) #读取表中岗位信息 dfr = pd.read_excel(r'D:\中国天气网\7日天气情况表.xls') print(dfr) #用来存储日期 dayList = [] #用来存储天气 weatherList = [] #用来存储温度 temperatureList = [] #用来存储风速 windList = [] #泉州天气url链接 url = 'http://www.weather.com.cn/weather/101230501.shtml' #获取页面HTML代码 html = getHTMLText(url) #获取数据,并将数据存在相应的列表中 getData(dayList,weatherList,temperatureList,windList,html) #创建文件夹 makeMkdir() #存储并打印数据 pdSaveRead(dayList,weatherList,temperatureList,windList)
6.附完整程序代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from matplotlib.pyplot import plot,savefig
import matplotlib.pyplot as plt
import os
import re
#爬取中国天气网的HTML页面
def getHTMLText(url):
try:
#获取目标页面
r = requests.get(url)
#判断页面是否链接成功
r.raise_for_status()
#使用HTML页面内容中分析出的响应内容编码方式
r.encoding = r.apparent_encoding
#返回页面内容
return r.text
except:
#如果爬取失败,返回“爬取失败”
return "爬取失败"
#爬取数据
def getData(dayList,weatherList,temperatureList,windList,html):
#创建BeautifulSoup对象
soup = BeautifulSoup(html,"html.parser")
#遍历所有属性为t clearfix的ul标签
for ul in soup.find_all("ul",{"class":"t clearfix"}):
#获取日期
for h1 in ul.find_all('h1'):
#将日期存在dayList列表中
dayList.append(h1.string)
#获取天气信息
for p in ul.find_all('p',{"class":"wea"}):
#将天气信息存在weatherList列表中
weatherList.append(p.string)
#获取温度信息
for p in ul.find_all('p',{"class":"tem"}):
#将温度信息存在temperatureList列表中
temperatureList.append(p.get_text().strip())
#获取风速信息
for p in ul.find_all('p',{"class":"win"}):
#将风速信息存在windList列表中
windList.append(p.i.string)
#创建文件夹
def makeMkdir():
try:
#创建文件夹
os.mkdir("D:\中国天气网")
except:
#如果文件夹存在则什么也不做
""
#使用pandas进行数据存储、读取
def pdSaveRead(dayList,weatherList,temperatureList,windList):
#创建numpy数组
r = np.array([dayList,weatherList,temperatureList,windList])
#columns(列)名
columns_title = ['日期','天气','温度','风速']
#创建DataFrame数据帧
df = pd.DataFrame(r.T,columns = columns_title)
#将数据存在Excel表中
df.to_excel(r'D:\中国天气网\7日天气情况表.xls',columns = columns_title)
#读取表中岗位信息
dfr = pd.read_excel(r'D:\中国天气网\7日天气情况表.xls')
print(dfr)
c
#用来存储日期
dayList = []
#用来存储天气
weatherList = []
#用来存储温度
temperatureList = []
#用来存储风速
windList = []
#泉州天气url链接
dataLiat1 = []
url = 'http://www.weather.com.cn/weather/101230501.shtml'
#获取页面HTML代码
html = getHTMLText(url)
#获取数据,并将数据存在相应的列表中
getData(dayList,weatherList,temperatureList,windList,html)
#创建文件夹
makeMkdir()
#存储并打印数据
pdSaveRead(dayList,weatherList,temperatureList,windList)
#筛选出温度数据
for i in temperatureList:
fg = re.search(r'^(\d)+',i)
#将温度存储在列表中
dataLiat1.append(int(fg.group()))
#打印存储图片
dataFigure(dataLiat1)

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过观察泉州地区的天气变化可以直观的看到近7日的最高温为24度与最低温度14度,天气状况良好,风速控制在3~5级。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次任务的进行,我发现了许多在课堂上没有遇到过的问题,也明白了只有在经过自己的不断学习,不断实践,不断解决错误的过程中
才能取得真正的进步。在面对实践过程中出现的错误时要有耐心,认真的研究,只有在不断的纠错中才可以取得真正实质上的成长。