前言
年初的时候给自己定了一个目标,就是学习Netty的源码,因此在Q2的OKR上,其中一个目标就是学习Netty源码,并且在部门内进行一次Netty相关的学习分享。然而,出生牛犊不怕虎,当时甚至都不知道Netty怎么用,上来就是看源码,看了不到半天就懵了,连学下去的信心都没了。到Q2结束,我的Netty学习进度几乎为0。Q3的OKR上再次定下了要看Netty源码的目标,然后,整个Q3中,这个口号依旧只是在嘴上喊喊,从没付出行动。到了Q4,依旧在OKR上写上了Netty源码学习的目标,眼瞅着Q4还剩下一个月,Netty源码的学习产出依旧为0。连着失信两次,在Q2、Q3上空喊了两个季度的口号,常言道事不过三,终于决定动笔写写Netty相关的源码分析。
结合我自身学习Netty的经历,在正式进入Netty的源码分析,决定有必要先说说BIO、NIO的关系。在平时工作中,很少直接写网络编程的代码,即使要写也都是使用成熟的网络框架,很少直接进行Socket编程。下面将结合一个Demo示例,来熟悉下网络编程相关知识。在Demo示例中,客户端每隔三秒向服务端发送一条Hello World的消息,服务端收到后进行打印。
BIO
BIO是阻塞IO,也称之为传统IO,在Java的网络编程中,指的就是ServerSocket、Socket套接字实现的网络通信,这也是我们最开始学Java时接触到的网络编程相关的类。服务端在有新连接接入时或者在读取网络消息时,它会对主线程进行阻塞。下面是通过BIO来实现上面场景的代码。
服务端代码BioServer.java
* @author liujinkun
* @Title: BioServer
* @Description: BIO 服务端
* @date 2019/11/24 2:54 PM
*/
public class BioServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
while(true){
// accept()方法是个阻塞方法,如果没有客户端来连接,线程就会一直阻塞在这儿
Socket accept = serverSocket.accept();
InputStream inputStream = accept.getInputStream();
byte[] bytes = new byte[1024];
int len;
// read()方法是一个阻塞方法,当没有数据可读时,线程会一直阻塞在read()方法上
while((len = inputStream.read(bytes)) != -1){
System.out.println(new String(bytes,0,len));
}
}
}
}
在服务端的代码中,创建了一个ServerSocket套接字,并绑定端口8080,然后在while死循环中,调用ServerSocket的accept()方法,让其不停的接收客户端连接。accept()方法是一个阻塞方法,当没有客户端来连接时,main线程会一直阻塞在accept()方法上(现象:程序一直停在accept()方法这一行,不往下执行)。当有客户端连接时,main线程解阻塞,程序继续向下运行。接着调用read()方法来从客户端读取数据,read()方法也是一个阻塞方法,如果客户端发送来数据,则read()能读取到数据;如果没有数据可读,那么main线程就又会一直停留在read()方法这一行。
这里使用了两个while循环,外层的while循环是为了保证能不停的接收连接,内层的while循环是为了保证不停的从客户端中读取数据。
客户端代码BioClient.java
* @author liujinkun
* @Title: BioClient
* @Description: BIO 客户端
* @date 2019/11/24 2:54 PM
*/
public class BioClient {
public static ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1",8080);
// 采用具有定时执行任务的线程池,来模拟客户端每隔一段时间来向服务端发送消息
// 这里是每隔3秒钟向服务端发送一条消息
executorService.scheduleAtFixedRate(()->{
try {
OutputStream outputStream = socket.getOutputStream();
// 向服务端发送消息(消息内容为:客户端的ip+端口+Hello World,示例:/127.0.0.1:999999 Hello World)
String message = socket.getLocalSocketAddress().toString() + " Hello World";
outputStream.write(message.getBytes());
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}
},0,3,TimeUnit.SECONDS);
}
}
在客户端的代码中,创建了一个Socket套接字,并指定要连接的服务器地址和端口号。然后通过使用一个具有定时执行任务功能的线程池,让客户端每隔3秒钟向服务端发送一条数据。
这里为了每隔3秒发送一次数据,使用了具有定时执行任务功能的线程池,也可以不使用它,采用线程的sleep()方法来模拟3秒钟。如果有对线程池不够了解的朋友,可以参考这两篇文章: 线程池ThreadPoolExecutor的实现原理 和 为什么《阿里巴巴Java开发手册》上要禁止使用Executors来创建线程池
然后我们分别启动服务端和一个客户端,从服务端的控制台就可以看到,每个3秒钟就会打印一行 客户端的ip+端口+Hello World的日志。
/127.0.0.1:99999 Hello World
/127.0.0.1:99999 Hello World
/127.0.0.1:99999 Hello World
为了模拟多个客户端的接入,然后我们再启动一个客户端,这个时候我们期待在服务端的控制台,会打印出两个客户端的ip+端口+Hello World,由于服务端和两个客户端都是在同一台机器上,因此这个时候打印出来的两个客户端的ip是相同的,但是端口口应该是不一样的。我们期望的日志输出应该是这样的。
/127.0.0.1:99999 Hello World
/127.0.0.1:88888 Hello World
/127.0.0.1:99999 Hello World
/127.0.0.1:88888 Hello World
然而,这只是我们期望的,实际现象,并非如此,当我们再启动一个客户端后,发现控制台始终只会出现一个客户端的端口号,并非两个。
那么为什么呢?原因就在于服务端的代码中,read()方法是一个阻塞方法,当第一个客户端连接后,读取完第一个客户端的数据,由于第一个客户端一直不释放连接,因此服务端也不知道它还有没有数据要发送过来,这个时候服务端的main线程就一直等在read()方法处,当有第二个客户端接入时,由于main线程一直阻塞在read()方法处,因此它无法执行到accept()方法来处理新的连接,所以此时我们看到的现象就是,只会打印一个客户端发送来的消息。
那么我们该怎么办呢?既然知道了问题出现main线程阻塞在read()方法处,也就是在读数据的时候出现了阻塞。而要解决阻塞的问题,最直接的方式就是利用多线程技术了,因此我们就在读数据的时候新开启一条线程来进行数据的读取。升级之后的服务端代码如下。
服务端代码BioServerV2.java
* @author liujinkun
* @Title: BioServer
* @Description: BIO 服务端
* @date 2019/11/24 2:54 PM
*/
public class BioServerV2 {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
while (true) {
// accept()方法是个阻塞方法,如果没有客户端来连接,线程就会一直阻塞在这儿
Socket accept = serverSocket.accept();
// 用另外一个线程来读写数据
handleMessage(accept);
}
}
private static void handleMessage(Socket socket) {
// 新创建一个线程来读取数据
new Thread(() -> {
try {
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
int len;
while ((len = inputStream.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
客户端的代码不变,依然使用BioClient。在服务端的代码BioServerV2中,读数据的操作我们提取到了handleMessage()方法中进行处理,在该方法中,会新创建一个线程来读取数据,这样就不会造成main线程阻塞在read()方法上了。启动服务端和两个客户端进行验证。控制台打印结果如下。
/127.0.0.1:99999 Hello World
/127.0.0.1:88888 Hello World
/127.0.0.1:99999 Hello World
/127.0.0.1:88888 Hello World
虽然解决了多个客户端同时接入的问题,但是其中的缺点我们也很容易发现:每当有一个新的客户端来连接服务端时,我们都需要为这个客户端创建一个线程来处理读数据的操作,当并发度很高时,我们就需要创建很多的线程,这显然这是不可取的。线程是服务器的宝贵资源,创建和销毁都需要花费很长时间,当线程过多时,CPU的上线文切换也更加频繁,这样就会造成服务响应缓慢。当线程过多时,甚至还会出现句柄溢出、OOM等异常,最终导致服务宕机。另外,我们在读取数据时,是基于IO流来读取数据的,每次只能读取一个或者多个字节,性能较差。
因此BIO的服务端,适用于并发度不高的应用场景,但是对于高并发,服务负载较重的场景,使用BIO显然是不适合的。
NIO
为了解决BIO无法应对高并发的问题,JDK从1.4开始,提供了一种新的网络IO,即NIO,通常称它为非阻塞IO。然而NIO的代码极为复杂和难懂,下面简单介绍写NIO中相关的类。
NIO相关的类均在java.nio包下。与BIO中ServerSocket、Socket对应,NIO中提供了ServerSocketChannle、SocketChannel分别表示服务端channel和客户端channel。与BIO中不同的是,NIO中出现了Selector轮询器的概念,不同的操作系统有不同的实现方式(在windows平台底层实现是select,在linux内核中采用epoll实现,在MacOS中采用poll实现)。另外NIO是基于ByteBuffer来读写数据的。
介绍了这么多关于NIO的类,估计你也懵逼了,下面先看看如何用NIO来实现上面的场景。
服务端代码NioServer.java
/**
* @author liujinkun
* @Title: NioServer
* @Description: NIO 服务端
* @date 2019/11/24 2:55 PM
*/
public class NioServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 轮询器,不同的操作系统对应不同的实现类
Selector selector = Selector.open();
// 绑定端口
serverSocketChannel.bind(new InetSocketAddress(8080));
serverSocketChannel.configureBlocking(false);
// 将服务端channel注册到轮询器上,并告诉轮询器,自己感兴趣的事件是ACCEPT事件
serverSocketChannel.register(selector,SelectionKey.OP_ACCEPT);
while(true){
// 调用轮询器的select()方法,是让轮询器从操作系统上获取所有的事件(例如:新客户端的接入、数据的写入、数据的写出等事件)
selector.select(200);
// 调用select()方法后,轮询器将查询到的事件全部放入到了selectedKeys中
Set selectionKeys = selector.selectedKeys();
// 遍历所有事件
Iterator iterator = selectionKeys.iterator();
while(iterator.hasNext()){
SelectionKey key = iterator.next();
// 如果是新连接接入
if(key.isAcceptable()){
SocketChannel socketChannel = serverSocketChannel.accept();
System.out.println("有新客户端来连接");
socketChannel.configureBlocking(false);
// 有新的客户端接入后,就样将客户端对应的channel所感兴趣的时间是可读事件
socketChannel.register(selector,SelectionKey.OP_READ);
}
// 如果是可读事件
if(key.isReadable()){
// 从channel中读取数据
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
channel.read(byteBuffer);
byteBuffer.flip();
System.out.println(Charset.defaultCharset().decode(byteBuffer));
// 读完了以后,再次将channel所感兴趣的时间设置为读事件,方便下次继续读。当如果后面要想往客户端写数据,那就注册写时间:SelectionKey.OP_WRITE
channel.register(selector,SelectionKey.OP_READ);
}
// 将SelectionKey从集合中移除,
// 这一步很重要,如果不移除,那么下次调用selectKeys()方法时,又会遍历到该SelectionKey,这就造成重复处理了,而且最终selectionKeys这个集合的大小会越来越大。
iterator.remove();
}
}
}
}
看完代码实现,你可能更加懵逼了。这么简单的一个Hello World,居然要写这么多的代码,而且还全都看不懂。(我第一次接触这些代码和API时,就是这种想法,以至于我Q2、Q3季度都不想去学和NIO相关的东西)。下面简答解释下这段代码。
- 首先通过ServerSocketChannel.open()这行代码创建了一个服务端的channel,也就是服务端的Socket。(在计算机网路的7层模型或者TCP/IP模型中,上层的应用程序通过Socket来和底层沟通)
- 通过Selector.open()创建了一个轮询器,这个轮询器就是后续用来从操作系统中,遍历有哪些socket准备好了。这么说有点抽象,举个栗子。坐火车时,通常都会有补票环节。每过一站后,乘务员就会在车厢中吼一嗓子,哪些人需要补票的?需要补票的人去几号车厢办理。这个乘务员就对应NIO中轮询器,定时去车厢中吼一嗓子(也就是去操作系统中“吼一嗓子”),这个时候如果有人需要补票(有新的客户端接入或者读写事件发生),那么它就会去对应的车厢办理(这些接入事件或者读写事件就会跑到selectKeys集合中)。而对应BIO,每对应一个新客户端,都需要新建一个线程,也就是说每出现一个乘客,我们都要为它配备一个乘务员,这显然是不合理的,不可能有那么多的乘务员。因此这就是NIO对BIO的一个巨大优势。
- 然后为服务端绑定端口号,并设置为非阻塞模式。我们使用NIO的目的就是为了使用它的非阻塞特性,因此这里需要调用 serverSocketChannel.configureBlocking(false)设置为非阻塞
- 然后将ServerSocketChannel注册到轮询器selector上,并告诉轮询器,它感兴趣的事件是ACCEPT事件(服务端的Channel就是用来处理客户端接入的,因此它感兴趣的事件就是ACCEPT事件。为什么要把它注册到轮询器上呢?前面已经说到了,轮询器会定期去操作系统中“吼一嗓子,谁要补票”,如果不注册到轮询器上(不上火车),轮询器吼一嗓子的时候,你怎么听得见呢?)
- 接着就是在一个while循环中,每过一段时间让轮询器去操作系统中轮询有哪些事件发生。select()方法就是去操作系统中轮询(吼一嗓子),它可以传入一个参数,表示在操作系统中等多少毫秒,如果在这段时间中没有事件发生(没有人要补票),那么就从操作系统中返回。如果有事件发生,那么就将这些事件方法放到轮询器的publicSelectedKeys属性中,当调用selector.selectedKeys()方法时,就将这些事件返回。
- 接下来就是判断事件是哪种事件,是接收事件还是读事件,亦或是写事件,然后针对每种不同的事件做不同的处理。
- 最后将key从集合中移除。为什么移除,见代码注释。 好了,解释了那么多,里面的细节还有很多,此时估计你还是佷懵。很懵就对了,这就是JDK中NIO的特点,操作繁琐,涉及到的类很多,API也很多,开发者想要掌握这些,难度很大。关键是掌握了,不一定代码写得好;写得好,不一定BUG少;BUG少,不一定性能高。JDK的NIO写法,一不小心就容易BUG满天飞。 上面是服务端NIO的写法,这个时候,可以直接利用BIO的客户端去进行测试。当然NIO也有客户端写法。虽然NIO的写法很复杂,但一回生,二回熟,多见几回就习惯了,所以下面还是贴出了NIO客户端的写法。
NIO客户端NioClient.java
/**
* @author liujinkun
* @Title: NioClient
* @Description: NIO客户端
* @date 2019/11/24 2:55 PM
*/
public class NioClient {
private static ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
public static void main(String[] args) throws IOException {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
boolean connect = socketChannel.connect(new InetSocketAddress("127.0.0.1", 8080));
// 因为连接是一个异步操作,所以需要在下面一行判断连接有没有完成。如果连接还没有完成,就进行后面的操作,会出现异常
if(!connect){
// 如果连接未完成,就等待连接完成
socketChannel.finishConnect();
}
// 每个3秒向服务端发送一条消息
executorService.scheduleAtFixedRate(() -> {
try {
String message = socketChannel.getLocalAddress().toString() + " Hello World";
// 使用ByteBuffer进行数据发送
ByteBuffer byteBuffer = ByteBuffer.wrap(message.getBytes());
socketChannel.write(byteBuffer);
} catch (IOException e) {
e.printStackTrace();
}
}, 0, 3, TimeUnit.SECONDS);
}
}
NIO客户端的写法相对比较简单,利用SocketChannel进行IP和端口的绑定,然后调用connect()方法进行连接到服务端。最后利用ByteBuffer装载数据,通过SocketChannel将数据写出去。
相比BIO而言,NIO不需要为每个连接去创建一个线程,它是通过轮询器,定期的从操作系统中获取到准备好的事件,然后进行批量处理。同时NIO是通过ByteBuffer来读写数据,相比于BIO中通过流来一个字节或多个字节的对数据,NIO的效率更高。但是ByteBuffer的数据结构设计,有点反人类,一不小心就会出BUG。关于ByteBuffer详细的API操作,有兴趣的朋友可以自己去尝试写写。关于BIO和NIO的区别,可以用下面一张图表示。
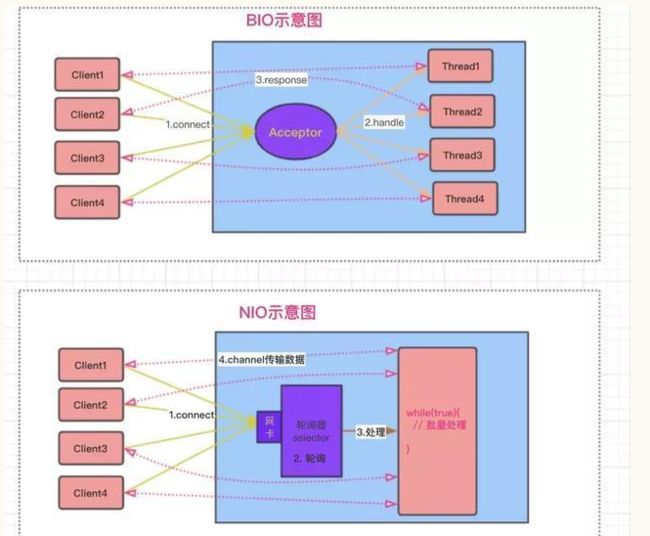
Netty
BIO在高并发下不适合用,而NIO虽然可以应对高并发的场景,但是它一方面因为写法复杂,掌握难度大,更重要的是还存在空轮询的BUG(产生空轮询的原因是操作系统的缘故),因此Netty出现了。Netty是目前应该使用最广泛的一款网络框架,用官方术语讲就是:它是一款基于事件驱动的高性能的网络框架。实际上它是一款将NIO包装了的框架,同时它规避了JDK中空轮训的BUG。虽然它是对NIO的包装,但是它对很多操作进行了优化,其性能更好。目前在很多Java流行框架中,底层都采用了Netty进行网络通信,比如RPC框架中Dubbo、Motan,Spring5的异步编程,消息队列RocketMQ等等都使用了Netty进行网络通信。
既然Netty这么好,怎么用呢?那么接下来就用Netty实现上面的场景。 服务端NettyServer.java
/**
* @author liujinkun
* @Title: NettyServer
* @Description: Netty服务端
* @date 2019/11/24 2:56 PM
*/
public class NettyServer {
public static void main(String[] args) {
// 负责处理连接的线程组
NioEventLoopGroup bossGroup = new NioEventLoopGroup(1);
// 负责处理IO和业务逻辑的线程组
NioEventLoopGroup workerGroup = new NioEventLoopGroup(8);
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
// 添加日志打印,用来观察Netty的启动日志
.handler(new LoggingHandler(LogLevel.INFO))
// 添加用来处理客户端channel的处理器handler
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
ChannelPipeline pipeline = nioSocketChannel.pipeline();
// 字符串解码器
pipeline.addLast(new StringDecoder())
// 自定义的handler,用来打印接收到的消息
.addLast(new SimpleChannelInboundHandler() {
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, String message) throws Exception {
System.out.println(message);
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
super.channelRegistered(ctx);
System.out.println("有新客户端连接");
}
});
}
});
// 绑定端口,并启动
ChannelFuture channelFuture = serverBootstrap.bind(8080).sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 关闭线程组
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
上面的代码虽然看起来也很长,但是这段代码几乎是不变的,它几乎适用于所有场景,我们只需要修改childHandler()这一行相关的方法即可。这里面的代码才是处理我们自定义的业务逻辑的。具体代码细节,就不再详细解释了,后面会单独写文章来分别从源码的解读来分析Netty服务端的启动、新连接的接入、数据的处理、半包拆包等问题。
启动NettyServer,可以直接使用BioClient或者NioClient来测试NettyServer。当然,Netty也有客户端的写法。代码如下。
Netty客户端NettyClient
/**
* @author liujinkun
* @Title: NettyClient
* @Description: Netty客户端
* @date 2019/11/24 2:57 PM
*/
public class NettyClient {
private static ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
public static void main(String[] args) {
// 客户端只需要一个线程组即可
NioEventLoopGroup nioEventLoopGroup = new NioEventLoopGroup();
try {
// 采用Bootstrap而不是ServerBootstrap
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(nioEventLoopGroup)
// 设置客户端的SocketChannel
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
ChannelPipeline pipeline = nioSocketChannel.pipeline();
// 添加一个字符串编码器
pipeline.addLast(new StringEncoder());
}
});
ChannelFuture channelFuture = bootstrap.connect("", 8080).sync();
Channel channel = channelFuture.channel();
executorService.scheduleAtFixedRate(()->{
String message = channel.localAddress().toString() + " Hello World";
channel.writeAndFlush(message);
},0,3,TimeUnit.SECONDS);
channel.closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
nioEventLoopGroup.shutdownGracefully();
}
}
}
实际上客户端的代码也几乎是固定的,所有场景都可以复用这段代码,唯一需要修改的就是handler()方法这一块,需要针对自己的业务逻辑去添加不同的处理器。
相比于NIO的写法,Netty的写法更加简洁,代码量相对更少,几行简单的代码就搞定了服务的启动,新连接接入,数据读写,编解码等问题。这也是为什么Netty使用这么广泛的原因。相比于NIO,Netty有如下几点优点。
- JDK的NIO存在空轮询的BUG,而Netty则巧妙的规避了这一点;
- JDK的API复杂,开发人员使用起来比较困难,更重要的是,很容易写出BUG;而Netty的API简单,容易上手。
- Netty的性能更高,它在JDK的基础上做了很多性能优化,例如将selector中的publicSelectedKeys属性的数据结构由Set集合改成了数组。
- Netty底层对IO模型可以随意切换,针对Reactor三种线程模型,只需要通过修改参数就可以实现IO模型的切换。
- Netty经过了众多高并发场景的考验,如Dubbo等RPC框架的验证。
- Netty帮助我们解决了TCP的粘包拆包等问题,开发人员不用去关心这些问题,只需专注于业务逻辑开发即可。
- Netty支持很多协议栈。JDK自带的对象序列化性能很差,序列化后码流较大,而是用其他方式的序列化则性能较高,例如protobuf等。
- 优点还有很多...
总结
- 本文通过一个示例场景,从BIO的实现到NIO实现,最后到Netty的实现,分别对比了它们的优缺点,毫无疑问,Netty是网络编程的首选框架,至于有点很多。
作者:天堂同志
原文链接:https://juejin.im/post/5ddac340e51d4522fd61a75b