
- inner join 和 outer join 的区别?
假设你要join两个没有重复列的表,这是最常见的情况:
inner join A 和 B 获得的是A和B的交集(intersect),即韦恩图(venn diagram) 相交的部分.
outer join A和B获得的是A和B的并集(union), 即韦恩图(venn diagram)的所有部分.
假定有两张表,每张表只有一列,列数据如下:
A B
1 3
2 4
3 5
4 6
注意(1,2)是A表独有的,(3,4) 两张共有, (5,6)是B独有的。
Inner join 使用等号进行inner join以获得两表的交集,即共有的行。
select * from a INNER JOIN b on a.a = b.b;
select a.*,b.* from a,b where a.a = b.b;
a | b
--+--
3 | 3
4 | 4
Left outer join
full outer join 除了获得B表中符合条件的列外,还将获得A表所有的列。
select * from a LEFT OUTER JOIN b on a.a = b.b;
select a.*,b.* from a,b where a.a = b.b(+);
a | b
--+-----
1 | null
2 | null
3 | 3
4 | 4
Full outer join
full outer join 得到A和B的交集,即A和B中所有的行.。如果A中的行在B中没有对应的部分,B的部分将是 null, 反之亦然。
select * from a FULL OUTER JOIN b on a.a = b.b;
a | b
-----+-----
1 | null
2 | null
3 | 3
4 | 4
null | 6
null | 5
2.union与union all的区别
在数据库中,union和union all关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。如
select * from test_union1
union
select * from test_union2
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
而union all只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,union all要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用union all,如下:
select * from test_union1
union all
select * from test_union2
使用 union 组合查询的结果集有两个最基本的规则:
1。所有查询中的列数和列的顺序必须相同。
2。数据类型必须兼容
-
write a query to find and remove duplicates in a table without creating another table
DELETE FROM table WHERE name IN (SELECT name FROM table GROUP BY name HAVING COUNT(*) > 1) AND NOT id IN (SELECT min(id) FROM table GROUP BY name)
- 什么是游标,解释不同类型的游标
游标实际上是一种从包括多条数据记录的结果集中每次提取一条记录的机制。
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果 。
游标(cursor)必须在声明处理程序之前被声明,并且变量和条件必须在声明游标或处理程序之前被声明。
游标分为 显式游标 和 隐式游标
当查询返回结果超过一行时,就需要一个显式游标,此时用户不能使用select into语句。 显式游标在PL/SQL块的声明部分声明,在执行部分或异常处理部分打开,取数据,关闭。 这里要做一个声明,我们所说的游标通常是指显式游标,而显式游标需要被声明。
当我们在PL/SQL中进行非查询(或者返回单条记录的查询)语句,如update、delete、insert等时,ORACLE 系统会自动地为这些操作设置游标并创建其工作区,并且隐式游标的名字为SQL,由ORACLE 系统定义。 对于隐式游标的操作,如定义、打开、取值及关闭操作,都由ORACLE 系统自动地完成,无需用户进行处理。
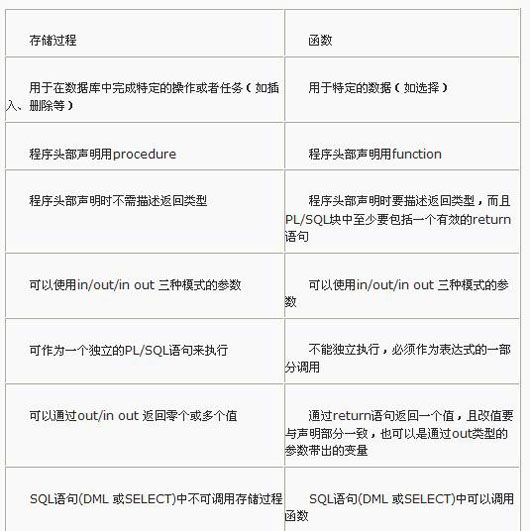
- stored procedure和Function的差异
存储过程(Stored Procedure)是数据库系统中,一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
- 数据库范式
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。
- 第一范式(1NF)属性不可分
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库 - 第二范式(2NF)属性完全依赖于主键 [ 消除部分子函数依赖 ]
满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键。简而言之,第二范式(2NF)就是非主属性完全依赖于主关键字。 - 第三范式(3NF)属性不依赖于其它非主属性 [ 消除传递依赖 ]
满足第三范式(3NF)必须先满足第二范式(2NF)。第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。简而言之,第三范式就是属性不依赖于其它非主属性。满足第三范式的数据库表应该不存在如下依赖关系:关键字段 → 非关键字段x → 非关键字段y
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。 - BCNF
若关系模式R是第一范式,且每个属性都不传递依赖于R的候选键。这种关系模式就是BCNF模式。即在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖。
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。
-
primary key与unique的区别
UNIQUE 约束的字段中不能包含重复值,可以为一个或多个字段定义 UNIQUE 约束 - 作为Primary Key的域/域组不能为null,而Unique Key可以。 - 在一个表中只能有一个Primary Key,而多个Unique Key可以同时存在。 简单的说,primary key = unique + not null
-
数据库中drop delete truncate 的区别
- drop (删除表):删除内容和定义,释放空间。简单来说就是把整个表去掉,要新增数据是不可能的,除非新增一个表。 drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
- truncate (清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构)。与drop不同的是,只是清空表数据而已。
注意:truncate 不能删除行数据,要删就要把表清空。 - delete (删除表中的数据):delete 语句用于删除表中的行。
delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存,以便进行进行回滚操作。
truncate与不带where的delete :只删除数据,而不删除表的结构(定义) - truncate table 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用delete。
如果要删除表定义及其数据,请使用 drop table 语句。 - 对于由foreign key约束引用的表,不能使用truncate table ,而应使用不带where子句的delete语句。由于truncate table 记录在日志中,所以它不能激活触发器。
- 执行速度,一般来说: drop> truncate > delete。
- delete语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
- truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
- 找出每个部门员工中第三高的薪水
Select EmpID,empname,deptid,salary
From (
Select *
,RN = Row_Number() over (Partition By deptid Order By Salary)
,Cnt = sum(1) over (Partition By deptid)
From employee1
) A
Where RN = case when Cnt<3 then Cnt else 3 end
10.rank和row_number的区别 并解释
row_number() 是没有重复值的排序(即使两天记录相等也是不重复的),可以利用它来实现分页
dense_rank() 是连续排序,两个第二名仍然跟着第三名
rank() 是跳跃拍学,两个第二名下来就是第四名