今天终于完成了scadb-sentinel模块的开发,代码已经提交到github了,有了scadb-sentinel模块就基本具备高可用能力了。本篇将全面介绍一下scadb的高可用功能。
1. scadb中MySQL集群配置
这里我们先看一下scadb的架构图:
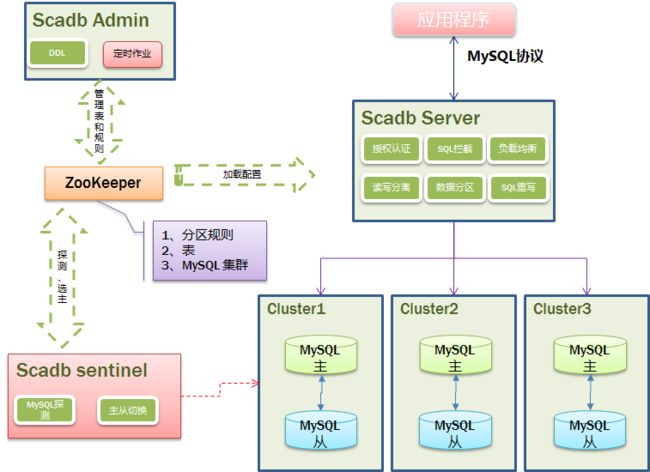
scadb可以支持分库分表的能力,每个库会对应MySQL的一个集群,如图中的Cluster1,Cluster2和Cluster3。scadb同时对MySQL的集群也进行了管理,实现数据库的高可用功能。主要的功能为:
1.1 实例的状态记录:
系统会实时记录每个实例的状态信息,并可以实时感知到每个实例状态的变化信息。每个实例的状态信息用一个类来记录,对应的类名为:MySQLStatus:
- zoneid : 归属的数据中心;
- role: 角色信息,目前支持两种角色:CANDIDATE, SLAVE,其中CANDIDATE角色的MySQL可以有被选成MySQL集群中主库的可能性,而SLAVE角色的MySQL永远只能SLAVE,在scadb启动读写分离的作用;
- status: 状态信息,目前有三种状态:
- START:工作状态,可以对外提供服务
- STOP : 停止状态,不对外提供服务,这种情况一般用于DBA对该MySQL进行维护时,可以把MySQL设置为STOP状态,这时候,scadb所有的进程都不会用到该实例;
- FAILED:失败状态,这种状态一般是scadb-sentinel探测时,发现实例处于失联状态,就会标记该实例为FAILED状态。标记为失联状态的实例,不会对外提供服务,但是,还是会定期进行探测,一旦
- delaySeconds:slave延迟秒数,一般来说,当探测不到数据的时候,会显示延迟秒数为-1,一般主库可能没有delaySeconds数据。延迟秒数的作用在于,如果超过了系统限定的延迟描述,该slave就不会参与到读写分离中。
1.2 主库信息:
主要是为了记录集群的当前的主库和该集群支持的切换模式,对应的类为:ClusterModel,包含的信息有:
- currentMaster: 当前主库
- switchMode: 切换模式, 切换模式有两种
- AUTO : 自动切换,表示该集群会被自动切换;
- MANUAL:手动切换,表示该集群不会自动切换,只能手动切换,这种模式下,一旦发现主库故障,需要DBA参与切换。
2. MySQL实例探测
scadb-sentinel在实现MySQL实例探测功能的时候,我一直在考虑要不要像redis-sentinel,在多个进程中同时进行探测,然后把实例的状态按照主观死亡和客观死亡,这种多方确认的方式来实现。
理论上来说 redis-sentinel这种实现模式,相对来说比较严谨,但是实现难度较高,所以短期内,我没有按照这种方案来做,以后如果有经历再按照这种思路来实现。
我现在的实现思路是每个数据中心部署一个scadb-sentinel进程,让它负责探测自己所在数据中心的MySQL实例,探测出异常后,在zookeeper上标记MySQL实例的异常状态。架构图如下所示:

探测的实现思路如下所示:
- 定时探测同数据中心的所有MySQL实例,每5秒中一次探测;
- 当探测到某个MySQL实例异常时,不会立即标记异常,需要等待下次探测出异常时,才会实际标记MySQL实例状态为FAILED状态,防止误判;
- 对于处于FAILED状态的实例不会按照每5秒一次去探测,而是每次把探测时长加倍,一旦超过2分钟,就会停止加倍。这样做的好处在于,对于异常状态的MySQL实例,探测会比较耗时,会影响其他正常实例的探测。
采用上述的方案有如下几个理由:
- 同数据中心探测,能够最准确的保证探测结果,基本上可以避免因为网络故障造成的探测失误;
- 多个scadb-sentinel进程之间没有交互,实现比较简单;
- 之前开发过rds,基本上是采用本机探测的模式,与同一个数据中心探测的能力类似。
当然该实现也有一定的缺陷,譬如,数据中心内部网络故障造成探测失败就无法避免了,还有就是网线松动也有可能造成问题。虽然出现的几率比较小,但是也是个漏洞,所以下一个阶段,还是要考虑按照redis-sentinel的模式来实现。通过多数scadb-sentinel进程的确定,来定位MySQL实例的故障状态,会更加准确。
3. MySQL主从切换
MySQL集群有两种切换模式:自动切换和手动切换,这里主要针对自动切换模式下的集群如何实现主从切换功能。
上一节讲述了MySQL实例的实时探测和状态标记,一旦一个MySQL集群中的主库实例被标记成故障状态(或者被手工改为STOP状态),处于FAILED和STOP状态的MySQL实例将不会对外提供服务,因此这个时候就需要主从切换,否则,服务会不正常,
scadb-sentinel是多进程部署模式,如果多个进程同时做切换,有可能会造成混乱,所以我们需要从scadb-sentinel中选出一个主,让主独立负责切换工作。
3.1 scadb-sentinel选主
选主采用了curator库中的LeaderSelector,每个scadb-sentinel在启动时会初始化一个LeaderSelector实例,使用该实例就会选出一个主出来,然后由改进程来负责切换功能。
3.2 scadb-sentinel主从切换
3.2.1 主从切换的判断
scadb-sentinel会实时监视MySQL实例的状态变化,发生了任何的变化都会判断是是否需要进行主从切换,总从切换的判断主要是两个条件:
- 主库是否不正常,处于FAILED或者STOP状态;
- 是否有合适的候选者。选择候选者的逻辑为:
- 找到角色为CANDIDATE的实例;
- 看看该实例是否状态正常(为START);
- 看看那些后选择实例与主库最接近;
以上两个条件都满足才会进行主从切换,否则不会进行主从切换。
3.2.2 主从切换
一旦主从切换的条件满足了,那么系统就会进行该集群的主从切换工作了。目前MySQL的主从切换根据集群配置不同,可能进行主从切换的逻辑也不同,所以,这里我把主从切换的模式设置为了可配置的模式。
在配置文件中,有一个配置参数:
switcher=org.herry2038.scadb.switcher.MysqlSwitcherCommon
这是一个缺省的配置,也是目前唯一的切换实现,该切换实现非常简单,就是直接把在主库信息在zookeeper中进行修改即可,说到这里,我简单介绍一下目前MySQL主从切换的几种模型。
- 主主从
这种模型一般用于非GTID模式下,采用这种模型的话,主库会在两个MASTER之间进行切换,并且切换也很简单,就是我们目前的实现org.herry2038.scadb.switcher.MysqlSwitcherCommon可以解决的,只要在zookeeper中标记新的主库即可。
所以我目前的实现就是适合这种模型的。这种切换模型有可能需要DBA参与,不过对于数据一致性要求不是非常高的业务比较适合这种模型。
- MHA支持的切换模型(一主多从)
MHA支持的一种主从切换模型,只有一个主库,其他的从库都连到当前的主库上,主库出现故障后的切换过程为:
1). 恢复新master
- 选举一个新master,根据relay-log 最新来判断;
- 从crashed 的master中把binlogs logs从新master的relay logs的end_log_pos开始把差异的日志生成出来;
- 把差异日志在新master上应用;
- 应用成本,设置为可用;
2)恢复其他的slave - 从crashed 的master中把binlogs logs从slave的relay logs的end_log_pos开始把差异的日志生成出来;
- 把差异日志slave上应用;
- 应用成功后,让该slave指向新的master,并让该slave可用;
MHA这种主从切换模式比较成熟,也可以减少数据不一致性,但是存在一些问题:
- crashed master如果主机不可达,会造成不可用;
- crashed master日志在新master应用不成功,会造成系统不可用;
- crashed master日志在从库应用不成功,会造成该从库不可用;
- 需要ssh打通各个机器;
这些限制对于可用性和安全性要求较高的应用来说,将会无法接受,所以scadb以后也不会对这种模式提供支持。
- GTID模型下的切换
这种模式的切换会比较容易,并且很容易保证集群中MySQL的数据一致性,切换的步骤基本为:
1)选出新的Master(位置最新的);
2)让其他的Slave把主库指向该Master;
下一阶段,会考虑实现该模型。
4. 整体高可用性
系统是配置是基于Zookeeper的,实例状态和主库切换的结果,都会反应到Zookeeper上,scadb和scadb-admin都会在第一时间得到通知。
MySQL实例状态变化
scadb比较关注实例状态的变化,目前会有两种情况需要考虑
故障状态/停止状态:这两种状态下的实例不会参与服务。如果主库变成这种状态,将会临时不能提供写服务,所有的写操作都会失败,只有等待自动切换完成或者人工切换;如果是从库进入这种状态,读操作会落到其他同一个数据中心的从库上,如果没有合适的从库,将会落到主库。
延迟时间:延迟时间超出临界值的从库与故障故障的实例一样。
主库变化
主库变化信息scadb和scadb-admin都会关心,scadb-admin只会在主库上操作。而scadb进程的写操作也是只在主库上执行。
从上面的分析可以看出,任何实例(包括主库)故障都不会造成停服,主库故障可能会有短暂的不可用,经过测试和估计,目前的方案可以保证在30秒内恢复正常。
5. 安装版本
scadb目前的安装版本和docker都还没有包含scadb-sentinel,后续会陆续更新。