10.两个样本的比较
1.样本的比较
现在,我们讲讲推断统计中两个变量之间的关系问题。
之前的章节中,我们都是采用单个方法进行函数分布问题的求解。然而,在实际的统计问题中,我们往往需要多种测量方法来了解两个变量之间的关系,尤其是一个变量的结果是否影响到另一个变量的结果,即两个变量之间是否存在某种联系,而其中,有一种关系我们非常熟悉,那就是某个变量是另一个变量的函数,即y=f(x)的形式,这样通过函数,我们就能直观的看到两个变量间的相互联系,即哪个变量是自变量,哪个变量是因变量。不过,大部分的两变量之间的关系其实是相当复杂的,不是三言两语就能说清的,这时需要我们具体情况具体分析了。当然,在第二个变量中,某一个具体的值都会有与之对应的第一个变量的分布,而不同的值所对应的分布往往是不一样的。所以,在统计分析方法中,我们都会把这种类型的第二个变量称之为探索变量,而它所对应的分布则称之为response(当然,你可以把response理解成答案分布,或者是这个变量的应答及其相关分布),而这样的探索变量在临床医学中有着广泛的运用。好了,下面我们就直入正题讲讲样本是怎样比较的。
2.样本均值比较
现在我们先看一个例子。首先,我们还是使用cars这个数据集,还是先对汽车的耗油量之差进行分析。在之前的讲解中,我已经求出了汽车重量的平均值,为2414lb。所以,我们对汽车重量是否达到2414lb进行分组,而且这一次是检验自变量为重量,因变量为耗油量之差的探索性分析,所以我们要先对汽车重量进行转换成因子格式的操作,具体如下:
heavy<-factor(cars$curb.weight>2414)
plot(dif.mpg~heavy)
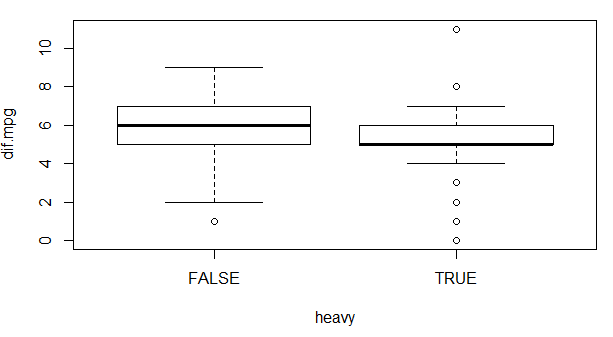
我们看到了把重量是否大于2414lb的汽车进行分组以后用箱图展示出来的结果。接下来,我们用t检验对这两个变量进行检验:
t.test(dif.mpg~heavy)

通过t检验,我们得到了汽车重量较轻的一组的平均值为5.805825,而重量较大的则是5.254902。再看看t,算出来的结果是2.4255,而p则为0.01621<0.05,说明了它处在拒绝域之中,我们可以拒绝原假设,也就是说,这两个变量的期望并不相同。
这里,我们要注意一下第一行写的Welch Two Sample t-test这段文字,这里是说这次t检验采用了Welch检验方法,对汽车耗油量之差和汽车重量进行变量探索性分析,主要是比较这两个变量的两个样本的期望是否一样。通常情况下,如果两个样本的期望是一样的,那么最后一行所显示的数值理应也是一样的,或者是它们之差小的可以让这个p大于0.05跳出拒绝域,显然,这一次的检验t值落在了拒绝域范围之内,所以,这两个样本的期望存在一定差别。
再说一下两样本期望之差,其差为5.805825-5.254902=0.550923,而计算出来的差值95%置信区间则为[0.1029150,0.9989315]。
3.样本的置信区间之差比较
上一节的最后我们稍微提了一下两样本之差的问题,而且只是笼统的说了一下它们俩之差的95%置信区间,那么,可能有人回问,我为什么会在讲两样本期望比较的时候会最后用两行字提了一下期望之差的置信区间?看到这一节的标题以后,会不会觉得有点像是我们写作文里一种叫做承上启下的写作手法,当然,这里用的实在有点不好,不过没关系,反正又不是语文课,只要知道就好了。
那么,既然在文章的最后引出了样本期望之差的置信区间,我们又为什么要学习两样本置信区间之差的比较呢?
先前,我们都只是用单个方法求出单个变量的单个样本的置信区间,然而实际上,我们大多数情况下是要在一个分布函数中去多个样本(多个变量)进行研究的,因此,我们需要掌握多样本的分析,而本节内容主要集中在两样本(研究两个变量)的区间问题上进行探讨。
假设一个随机样本分布X,E(X)和D(X)分别表示了这个样本的期望和方差。好了,又回到先前的例子,我们又对已经分好组的汽车重量进行探讨,还是之前的分组那样,重量大于2414lb的为一组,其余的为一组,并分别用符号Xa和Xb表示。现在,我们用E(Xa)-E(Xb)表示两样本期望之差,它将用于比较两区间之差的比较中,而X-则表示汽车重量的总平均值,同时,而且,我们会根据
这个公式进行区间估计。在R里,qnorm(0.975)相信对大家来说已经很熟悉了吧,算出来的结果为1.96;再看看上面讲到的区间估计的公式,其实可以简化为下面这个公式:
其中S为样本的标准差。
现在我们再来看一下下面的这个公式:
首先,我们都知道两样本的均值及其期望之差为
,又根据中心极限定理又可以推出标准化正态分布的标准差,就是结合上面两个公式得:
从这里,我们大致可以得知。
实际情况下,如果是要计算正则化正态分布的标准差,这两个样本其实一开始我们是不知道的。不过,我们还可以从这两个样本中分别取出一个子样本,分别以Sa,Sb来表示,由此,我们又能得知Var(Sa)=S2a,Var(Sb)=Sb2,从而推导出Var(Sa)/na+Var(Sb)/nb=Sa2/na+Sb2/nb,又由上文提到的公式又能推导出事件{-1.96<=Z<=1.96}也可以在这个条件下表示成下面的形式:
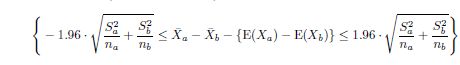
最后,我们又根据以上所列举的公式推导出两样本的期望之差为:
又回到耗油量之差这个例子,我们现在就根据上面的方法进行模拟:
我们首先还是分别把它们的平均值和方差算出来,计算完均值后可得,而标准差之差为
因此,我们现在所得出的两样本期望之差的95%置信区间为。
转载于:http://shujuren.org/article/97.html