EM算法及其应用(一)
EM算法及其应用(二): K-means 与 高斯混合模型
上一篇阐述了EM算法的主要原理,这一篇来看其两大应用 —— K-means 与 高斯混合模型,主要由EM算法的观点出发。
K-means
K-means的目标是将样本集划分为K个簇,使得同一个簇内样本的距离尽可能小,不同簇之间的样本距离尽可能大,即最小化每个簇中样本与质心的距离。K-means属于原型聚类(prototype-based clustering),原型聚类指聚类结构能通过一组原型刻画,而原型即为样本空间中具有代表性的点。在K-means中,这个原型就是每个簇的质心 \(\boldsymbol{\mu}\) 。
从EM算法的观点来看,K-means的参数就是每个簇的质心 \(\boldsymbol{\mu}\),隐变量为每个样本的所属簇。如果事先已知每个样本属于哪个簇,则直接求平均即可得到 \(\boldsymbol{\mu}\) 。但现实中不知道的情况下,则需要运用EM的思想:
假设要k个簇,先随机选定k个点作为质心\(\{\boldsymbol{\mu_1}, \boldsymbol{\mu_2} \cdots \boldsymbol{\mu_k}\}\):
- 固定\(\boldsymbol{\mu_k}\),将样本划分到距离最近的\(\boldsymbol{\mu_k}\)所属的簇中。若用\(r_{nk}\)表示第n个样本所属的簇,则
\[ r_{nk} = \left. \begin{cases} 1 \,\, & \text{if} \;\;\;k = \mathop{argmin}_j ||\mathbf{x}_n - \boldsymbol{\mu}_j||^2 \\ 0 \,\, & \text{otherwise} \end{cases} \right. \]
固定\(r_{nk}\),根据上一步的划分结果重新计算每个簇的质心。由于我们的目标是最小化每个簇中样本与质心的距离,可将目标函数表示为 \(J = \sum\limits_{n=1}^N r_{nk} ||\mathbf{x}_n - \boldsymbol{\mu}_k||^2\),要最小化\(J\)则对\(\boldsymbol{\mu}_k\)求导得 \(2\sum\limits_{n=1}^N r_{nk}(\mathbf{x}_n - \boldsymbol{\mu}_k) = 0\),则
\[ \boldsymbol{\mu}_k = \frac{\sum_nr_{nk} \mathbf{x}_n}{\sum_n r_{nk}} \]
即簇中每个样本的均值向量。
上面两步分别更新\(r_{nk}\)和\(\boldsymbol{\mu_k}\)就对应了EM算法中的E步和M步。和EM算法一样,K-means每一步都最小化目标函数 \(J\),因而可以保证收敛到局部最优值,但在非凸目标函数的情况下不能保证收敛到全局最优值。另外,K-means对每个样本进行“硬分配(hard assignment)”,即只归类为一个簇,然而某些样本可能处于簇与簇的边界处,将这些样本强行分到其中一个簇可能并不能反映确信度。后文的高斯混合模型可进行“软分配(soft assignment)”, 即对每个样本所划分的簇进行概率估计。
最后总结一下K-means算法的优缺点:
优点:
- 可解释性比较强。
- 调参的参数仅为簇数k。
- 相对于高斯混合模型而言收敛速度快,因而常用于高斯混合模型的初始值选择。K-means 的时间复杂度为 \(\mathcal{O}(N\cdot K \cdot I)\) ,簇数 \(K\) 和 迭代次数 \(I\) 通常远小于\(N\),所以可优化为 \(\mathcal{O}(N)\) ,效率较高。
缺点:
对离群点敏感。
K值难以事先选取,交叉验证不大适合,因为簇越多,目标函数 \(\sum\limits_{n=1}^N r_{nk} ||\mathbf{x}_n - \boldsymbol{\mu}_k||^2\) 就越小。常采用的方法有:一、“拐点法”,如下图 K=3 就是一个拐点。
二、 加上正则化系数 \(\lambda\) ,使得 \(\sum\limits_{n=1}^N \left(r_{nk} ||\mathbf{x}_n - \boldsymbol{\mu}_k||^2\right) + \lambda K\) 最小。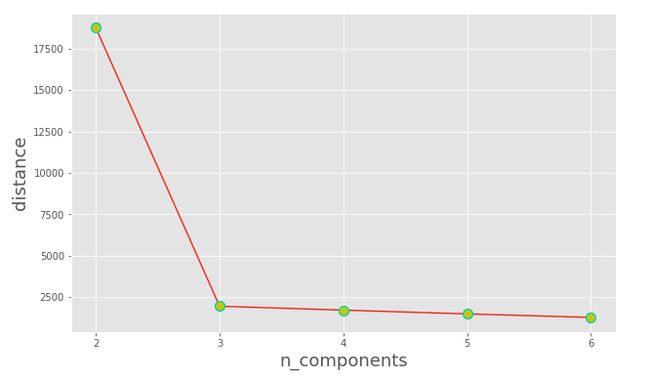
无法保证收敛到全局最优值,常使用不同的初始值进行多次试验。也可以通过 K-means++ 算法优化,核心思想是选取与已有质心距离较远的点作为初始值。
只能发现球状的簇。
由于采用欧氏距离,无法直接计算类别型变量。
高斯混合模型
高斯混合模型同样多用于聚类,与K-means不同的是其采用概率模型来表达聚类原型。
首先回顾一下高斯分布(Gaussian Distribution):对于随机变量\(x\),其概率密度函数可表示为:
\[ \mathcal{N}(x|\mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \]
若\(\mathbf{x}\)为n维随机向量,则多元高斯分布(Multivariate Gaussian Distribution)为:
\[ \mathcal{N}(\mathbf{x}| \boldsymbol{\mu},\mathbf{\Sigma}) = \frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^\frac12}\,e^{-\frac12(\mathbf{x}-\boldsymbol{\mu})^T\mathbf{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})} \]
其中\(\boldsymbol{\mu}\)为n维均值向量,\(\mathbf{\Sigma}\)为\(n\times n\)的协方差矩阵,\(|\mathbf{\Sigma}|\)为\(\mathbf{\Sigma}\)的行列式。
很多时候我们发现单个高斯分布无法很好地描述数据的性质,如下图数据分成了两个簇,如果使用两个高斯分布明显能更好地描述其结构。
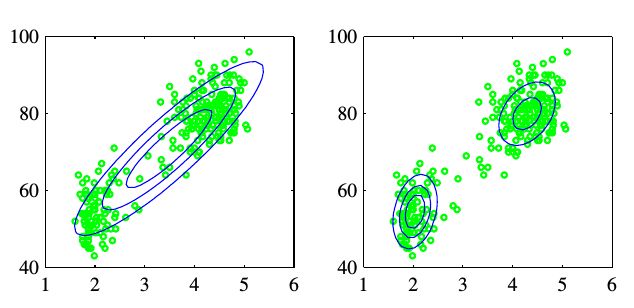
因此沿着这个思路就诞生了高斯混合模型(Mixture of Gaussians),本质上是k个高斯分布的线性组合,这样灵活性大增,能描述更多样的分布:
\[ p(\mathbf{x}) = \sum\limits_{k=1}^{K}\pi_k\mathcal{N}(\mathbf{x}|\boldsymbol{\mu}_k,\mathbf{\Sigma}_k) \qquad \tag{1.1} \]
其中\(0 \leqslant\pi_k\leqslant 1\)为混合系数(mixing coefficients),满足\(\sum\limits_{k=1}^{K} \pi_k= 1\) 。
由于本文的主角是EM算法,所以下面以EM算法的角度来看待高斯混合模型。
回忆EM算法是一种对含有隐变量的概率模型参数的极大似然估计。通常隐变量\(\mathbf{Z}\)未知,而实际知晓的只有观测数据\(\mathbf{X}\)。而对于高斯混合模型来说,观测数据是这样产生的:先依照\(\pi_k\)选择第k个高斯分模型,然后依照其概率密度函数进行采样生成相应的样本。
可以看到在经过上述过程后我们拿到手的只有采样得来的样本,却不知道每个样本来自于哪个分模型,但这样就表示我们获得了高斯混合模型的隐变量。
这里定义K维随机向量 \(\mathbf{z} = \begin{bmatrix} z_1 \\ z_2 \\ \vdots \\ z_k \\ \end{bmatrix}\),\(\mathbf{z}\)中只有一个\(z_k\)为1,其余元素为0,即\(z_k = \left. \begin{cases}1\,, & \text{数据来自第k个分模型} \\ 0\,, & \text{否则} \end{cases} \right.\),
这样\(z_k\)即为高斯混合模型的隐变量,表示样本来自于第k个分模型。
由于\(p(\mathbf{x}) = \sum\limits_zp(\mathbf{x},\mathbf{z}) = \sum\limits_{z}p(\mathbf{z})\,p(\mathbf{x}|\mathbf{z})\),对比\((1.1)\)式中高斯混合模型的定义,可将\(\pi_k\)视为选择第k个分模型的先验概率,即\(\pi_k = p(z_k = 1)\);而对应的\(\mathcal{N}(\mathbf{x}|\mathbf{\mu}_k, \mathbf{\Sigma}_k) = p(\mathbf{x}|z_k = 1)\)。另外在得到观测数据\(\{\mathbf{x}_1, \mathbf{x}_2 \cdots \mathbf{x}_n\}\)后,每个\(\mathbf{x}_n\)都对应一个隐变量\(z_{nk}\),则运用贝叶斯定理,\(\mathbf{x}_n\)属于第k个分模型的后验概率 (记作\(\gamma(z_{nk})\))为:
\[ \begin{align*} \gamma(z_{nk}) = p(z_{nk} = 1|\mathbf{x}_n) & = \frac{p(z_{nk} = 1)\,p(\mathbf{x}_n|z_{nk} = 1)}{\sum\limits_{j=1}^Kp(z_{nj}=1)\,p(\mathbf{x}_n|z_{nj} = 1)} \\ & = \frac{\pi_k\,\mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_k,\mathbf{\Sigma}_k)}{\sum\limits_{j=1}^K \pi_j\,\mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_j,\mathbf{\Sigma}_j)} \tag{1.2} \end{align*} \]
下图显示了\(\gamma(z_{nk})\)的作用,图a是依照完全数据的联合分布\(p(\mathbf{x},\mathbf{z})\)作图,每个点依照其所属的第k个分模型标记颜色,这类似于“硬分配”; 图b则不考虑隐变量\(\mathbf{z}\),仅依照不完全数据\(\mathbf{x}\)直接作图; 图c则考虑了每个样本来自于各个分模型的后验概率\(\gamma(z_{nk})\),这样一些在簇中间的点的颜色是红蓝绿三种颜色的混合,表明这些点来自于每个簇的概率比较接近,这即为“软分配”。
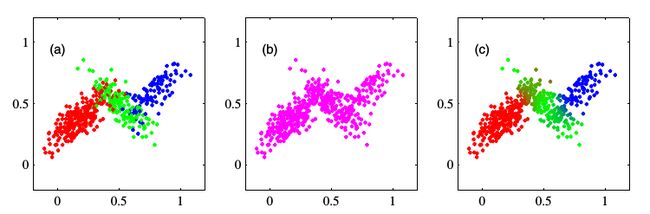
为了估计参数,如果直接采用极大似然法,则
\[ \begin{align*} L(\mathbf{\theta}) = ln\,p(\mathbf{X}|\mathbf{\theta}) = ln\,p(\mathbf{X}|\mathbf{\pi},\boldsymbol{\mu},\mathbf{\Sigma}) & = ln\left[\prod\limits_{n=1}^N\left(\sum\limits_{k=1}^K\,\pi_k \mathcal{N}(\mathbf{x}_n|\boldsymbol{\mu}_k,\mathbf{\Sigma}_k)\right) \right] \\[2ex] & = \sum\limits_{n=1}^N ln\left(\sum\limits_{k=1}^K \pi_k \frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^\frac12}\,e^{-\frac12(\mathbf{x}-\boldsymbol{\mu})^T\mathbf{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})} \right) \end{align*} \]
上式直接求导比较复杂,因为存在“和的对数” \(ln (\sum_{k=1}^K\pi_k\,\mathcal{N} \cdot)\) ,而如果使用EM算法则会方便很多。
先依照上一篇EM算法的流程,写出含Q函数:
\[ \mathcal{Q}(\mathbf{\theta}, \mathbf{\theta}^{(t)}) = \sum\limits_{n=1}^N\sum\limits_{\mathbf{z}}p(\mathbf{z}|\mathbf{x}_n,\mathbf{\pi}^{(t)},\boldsymbol{\mu}^{(t)},\mathbf{\Sigma}^{(t)})\,ln(\mathbf{x}_n,\mathbf{z}|\pi,\boldsymbol{\mu},\mathbf{\Sigma}) \tag{1.3} \]
由\((1.2)\)式可知,\((1.3)\)中第一项 \(p(z_{nk} = 1|\mathbf{x}_n,\pi^{(t)},\boldsymbol{\mu}^{(t)},\mathbf{\Sigma}^{(t)}) = \gamma(z_{nk})\),表示当前参数下每个样本\(\mathbf{x}_n\)属于第k个分模型的后验概率。而第二项为完全数据的对数似然函数:
\[ \begin{align*} ln(\mathbf{x}_n,\mathbf{z}|\pi,\mathbf{\mu},\mathbf{\Sigma}) & = ln\prod\limits_{k=1}^K \left[\pi_k\mathcal{N}(\mathbf{x}_n|\boldsymbol{\mu}_k,\mathbf{\Sigma_k}) \right]^{z_{nk}} \\ & = \sum\limits_{k=1}^Kz_{nk} \left[ln \pi_k + ln\,\mathcal{N}(\mathbf{x_n}|\boldsymbol{\mu}_k,\mathbf{\Sigma}_k)\right] \end{align*} \]
由此\((1.3)\)式变为:
\[ \begin{align*} & \sum\limits_{n=1}^N\sum\limits_{k=1}^K \gamma (z_{nk}) \left[ln \pi_k + ln\,\mathcal{N}(\mathbf{x_n}|\boldsymbol{\mu}_k,\mathbf{\Sigma}_k)\right] \\ = \;& \sum\limits_{n=1}^N\sum\limits_{k=1}^K \gamma (z_{nk}) \left[ln\,\pi_k + ln\left(\frac{1}{(2\pi)^\frac{n}{2}|\mathbf{\Sigma|^\frac{1}{2}}}\,e^{-\frac12 (\mathbf{x}_n - \boldsymbol{\mu}_k)^T\mathbf{\Sigma}_k^{-1}(\mathbf{x}_n-\boldsymbol{\mu}_k)} \right) \right] \tag{1.4} \end{align*} \]
可以看到上式括号中变成了“对数的和”,这使得求导方便了很多,且求解时式中\(ln(\cdot)\)和\(e^{(\cdot)}\)可以相互抵消。
\((1.4)\)式分别对\(\boldsymbol{\mu}_k\),\(\boldsymbol{\Sigma}_k\)求导得:
\[ \boldsymbol{\mu}_k = \frac{\sum\limits_{n=1}^N\gamma(z_{nk}) \cdot \mathbf{x}_n}{\sum\limits_{n=1}^N\gamma(z_{nk})}\qquad,\qquad \boldsymbol{\Sigma}_k = \frac{\sum\limits_{n=1}^N \gamma(z_{nk})\cdot (\mathbf{x}_n - \boldsymbol{\mu}_k)\cdot(\mathbf{x}_n-\boldsymbol{\mu}_k)^T}{\sum\limits_{n=1}^N \gamma(z_{nk})} \]
可以看到分模型k的\(\boldsymbol{\mu}_k\)和\(\boldsymbol{\Sigma}_k\)是所有样本的加权平均,其中每个样本的权重为该样本属于分模型k的后验概率\(\gamma(z_{nk})\) 。对比上文中K-means的 \(\boldsymbol{\mu}_k = \frac{\sum_nr_{nk} \cdot \mathbf{x}_n}{\sum_nr_{nk}}\),二者形式类似,区别为K-means中的\(r_{nk} \in \{0,1\}\),而高斯混合模型中\(\gamma(z_{nk})\)为概率估计。
对于混合系数\(\pi_k\),因为有限制条件\(\sum_{k=1}^K \pi_k = 1\),因此需要使用拉格朗日乘子法转化为无约束优化问题:
\[ \sum\limits_{n=1}^N\sum\limits_{k=1}^K \gamma (z_{nk}) \left[ln\,\pi_k + ln\left(\frac{1}{(2\pi)^\frac{n}{2}|\mathbf{\Sigma|^\frac{1}{2}}}\,e^{-\frac12 (\mathbf{x}_n - \boldsymbol{\mu}_k)^T\mathbf{\Sigma}_k^{-1}(\mathbf{x}_n-\boldsymbol{\mu}_k)} \right) \right] + \lambda(\sum\limits_{k=1}^K \pi_k - 1) \]
对\(\pi_k\)求导得,
\[ \begin{align*} & \sum\limits_{n=1}^N\frac{\gamma(z_{nk})}{\pi_k} + \lambda = 0 \qquad \Longrightarrow \qquad \pi_k = \frac{\sum\limits_{n=1}^N \gamma(z_{nk})}{-\lambda} \tag{1.5} \\ & \\ & \text{由于$\sum_{k=1}^K\pi_k = 1\;,\qquad$ 则} \;\;\sum_{k=1}^K \;\frac{\sum_{n=1}^N \gamma (z_{nk})}{-\lambda} = 1 \;, \;\lambda = -N \quad 代入(1.5) \;,\\ & \\ & \text{得}\; \pi_k = \frac{\sum_{n=1}^N\gamma(z_{nk})}{N} \end{align*} \]
即每个分模型k的混合系数是属于k的样本的平均后验概率,由此运用EM算法能大大简化高斯混合模型的参数估计过程,在中间步只需计算\(\gamma(z_{nk})\)就行了。
高斯混合模型的算法流程
输入: 样本集 \(\mathbf{X} = \{\mathbf{x}_1, \mathbf{x}_2 \cdots \mathbf{x}_n\}\)
输出: 高斯混合模型参数 \(\pi, \boldsymbol{\mu}, \boldsymbol{\Sigma}\)
- 初始化各个分模型参数 \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k\)
- E步: 依照当前模型参数,计算观测数据\(\mathbf{x}_n\)属于分模型k的后验概率:
\[ \begin{align*} \gamma(z_{nk}) = p(z_{nk} = 1|\mathbf{x}_n) = \frac{\pi_k\,\mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_k,\mathbf{\Sigma}_k)}{\sum\limits_{j=1}^K \pi_j\,\mathcal{N}(\mathbf{x}_n|\mathbf{\mu}_j,\mathbf{\Sigma}_j)} \end{align*} \]
- M步: 根据 \(\gamma(z_{nk})\)计算新一轮参数:
\[ \boldsymbol{\mu}_k^{new} = \frac{\sum\limits_{n=1}^N\gamma(z_{nk}) \cdot \mathbf{x}_n}{\sum\limits_{n=1}^N\gamma(z_{nk})} \]
\[ \boldsymbol{\Sigma}_k^{new} = \frac{\sum\limits_{n=1}^N \gamma(z_{nk})\cdot (\mathbf{x}_n - \boldsymbol{\mu}_k^{new})\cdot(\mathbf{x}_n-\boldsymbol{\mu}_k^{new})^T}{\sum\limits_{n=1}^N \gamma(z_{nk})} \]
\[ \pi_k^{new} = \frac{\sum_{n=1}^N\gamma(z_{nk})}{N} \]
- 重复2. 和3. 步直至收敛。
最后总结一下高斯混合模型的优缺点:
优点:
- 相比于K-means更具一般性,能形成各种不同大小和形状的簇。K-means可视为高斯混合聚类中每个样本仅指派给一个混合成分的特例,且各混合成分协方差相等,均为对角矩阵\(\sigma^2\mathbf{I}\)。
- 仅使用少量的参数就能较好地描述数据的特性。
缺点:
- 高斯混合模型的计算量较大收敛慢。因此常先对样本集跑k-means,依据得到的各个簇来定高斯混合模型的初始值。其中质心即为均值向量,协方差矩阵为每个簇中样本的协方差矩阵,混合系数为每个簇中样本占总体样本的比例。
- 分模型数量难以预先选择,但可以通过划分验证集来比较。
- 对异常点敏感。
- 数据量少时效果不好。
EM算法在半监督学习上的应用
在现实的分类问题中常遇到数据集中只有少量样本是带有标签的,而大部分样本的标签缺失。如果直接将无标签的样本丢弃,则会容易造成大量的有用信息被浪费。而如果使用EM算法,将缺失标签视为隐变量,很多时候能达到利用所有数据进行训练的目的。流程如下:
- 仅用带标签样本训练学习器,得到初始参数\(\theta\)。
- E步: 利用训练好的学习器预测无标签样本,将其分类到概率最大的类别,这样所有样本就都有标签了。
- M步: 用所有样本重新训练学习器,得到参数\(\theta^t\)。
- 重复2. 和 3. 步直至收敛,得到最终模型。
/