微信公众号:Lucidastar
如有问题或建议,请公众号留言
最近更新:2018-06-27
分析过程
- 简单使用
- 涉及到的知识点及用到的东西
- 重要变量的解释
- 提问问题(当然,在提问问题之前我是看过源码的,所以我认为这是重点或者难点我就进行提问了)
这是我分析源码的过程,可以按这我的这个过程进行下去
开始
我们在开发中,经常会使用到集合,List 、set等,今天我们就对HashMap进行简单的分析下(基于1.8)。首先从名字上可以看出,他是一个哈希表,具体什么是哈希表可以查阅相关资料。而Map就是存储一个键值对Map
下面我们先来一段原理:
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置 来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
好吧,这段是我从网上进行查找的,下面我们通过提问问题的方式来进行分析。
简单的使用
Map map = new HashMap<>();//创建
map.put("科目1", 1);//添加
map.put("科目2", 2);
map.put("科目3", 3);
map.put("科目4", 4);
map.put("科目5", 5);
map.put("科目6", 6);
map.put("科目7", 7);
map.put("科目8", 8);
Integer value = map.put("科目9", 9);//当添加新的数据时,key值不相同,那么返回的值就是null
Integer value1 = map.put("科目8", 10);//当key值相同时,会把原来的value给替换掉,并且返回替换掉的value
System.out.println(value);
System.out.println(value1);
boolean empty = map.isEmpty();//判断map是否为空
map.remove("科目6");//移除一个,并且返回移除的value
for (Map.Entry entry : map.entrySet()) {//map的遍历
System.out.println(entry.getKey()+":"+entry.getValue());
}
其他的api可以自行查阅文档。
涉及到的知识点及用到的东西
在开始我们就简单的介绍了一下,会涉及到数组,链表及红黑树(也叫平衡树)的数据结构方面的知识,如果对这方面不太了解的,可以查些资料简单了解一下。
红黑树的介绍:https://www.sohu.com/a/201923614_466939
链表的介绍:链表分为单链表,双链表和循环链表:http://www.baike.com/wiki/%E9%93%BE%E8%A1%A8
数组大家应该不陌生,这里就略过去了。
涉及到的变量,以及在里头的作用(我认为需要了解和重要的)
transient Node
transient int size;(键值映射的数量)
int threshold;//需要扩容的大小(容量*负载因子系数)threshold = length(长度,默认是16) * Load factor(默认是0.75)
final float loadFactor;//负载因子
transient int modCount;//主要用来记录HashMap内部结构发生变化的次数(数组和链表的结构发生改变)
下面我们通过提问问题的方式进行学习。
一、HashMap是怎样的一个结构?

是一个“链表散列”的数据结构,即数组和链表的结合体。
二、是如何把数据存到数组当中的?
如果我们想把数据存入进去,首先我们需要知道他的下标位置,然后找到相应的位置放进去,他是如何计算下标的呢?
if ((p = tab[i = (n - 1) & hash]) == null) //这个hash值就是通过下面的key算出来的,我们来看一下
tab[i] = newNode(hash, key, value, null);
而hash值的计算是通过这个
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
注意:h 在向右移位时,h的值已经是hashCode的值了
n 为数组的长度,第一次是16,上面已经讲过,我们来看一下如何计算出来的
我们来测试一下下标的计算:((n - 1) & hash)
int n = 16;
for (int i = 0; i < 12; i++) {
System.out.print(hash(i) & (n - 1));
System.out.print(",");
}
打印结果:0,1,2,3,4,5,6,7,8,9,10,11这就好比是table下标的位置
我们再来测试一个对象:
class Student{
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
}
int n = 16;
for (int i = 0; i < 12; i++) {
Student student = new Student();
student.setName("张三"+i);
System.out.print(hash(student) & (n - 1));
System.out.print(",");
}
打印结果:0,10,3,1,2,11,7,6,10,3,3,5
为什么上面的下标没有重复的,而测试对象时有重复的呢?
因为Integer重写了hashCode方法,而我创建的对象没有重新hashCode
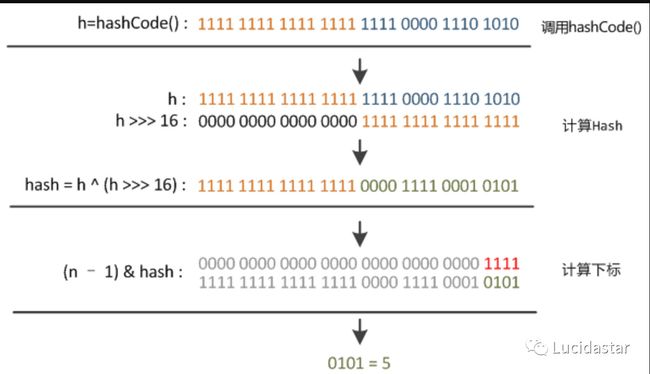
那他是如何进行操作的呢?先来张图
^ 代表异或
我们就以第一个例子为例,假如传入的是5
h=hashCode()=5: 0000 0000 0000 0000 0000 0000 0000 0101 =5
h >>>16: 0000 0000 0000 0000 0000 0000 0000 0000 = 0
逻辑右移
解释:比如300 二进制就是 100101100
300>>>1 结果是:10010110
300>>>2 结果是:1001011
300>>>3 结果是:100101
所以当16的时候就是0了
hash=h^(h>>>16): 0000 0000 0000 0000 0000 0000 0000 0101 这是异或后的值
^是代表的异或 例子:00=0,11=0 ,1^0 = 1,0^1=1
(n-1) & hash :
0000 0000 0000 0000 0000 0000 0000 1111 (n-1=15)
0000 0000 0000 0000 0000 0000 0000 0101 得到:0101 十进制就是5
&代表的是与:0&0=0,1&1=1 ,1&0 = 0,0&1=0
两个都是1时才是1
结论:那计算出来的下标位置就是5 我们就可以验证上面,5就会存到数组下标为5的位置。
三、什么时候会把数据存到数组中的链表中?
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//数组为空时创建
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//插入数组
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//当key相等时,就把value赋值
e = p;
else if (p instanceof TreeNode)//如果是红黑树
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
=============================================================
for (int binCount = 0; ; ++binCount) {//这里就是插入链表
if ((e = p.next) == null) {//如果链表的下一个是空,就创建一个节点,
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//当链表的长度大于16时,就转为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//// key已经存在并且相等,就把这个节点替换
break;
p = e;
}
}
//如果你插入是,key不为空,并且原来的节点不为空,并且返回替换掉的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}.
=============================================================
++modCount;//结构发生变化
if (++size > threshold)//超过最大容量时, 就会进行扩容。
resize();
afterNodeInsertion(evict);
return null;
}
横杠之间就是把数据存到数组对应的链表中了。
四、什么时候开始扩容?
if ((tab = table) == null || (n = tab.length) == 0)//数组为空时,就会进行初始化
n = (tab = resize()).length;
if (++size > threshold)//超过最大容量时, 就会进行扩容。(默认shreshold为12 16*0.75=12)
resize();
五、如何进行扩容的?
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果老的数组大于零
if (oldCap >= MAXIMUM_CAPACITY) {//大于最大的容量时,就会返回老的数组,不让扩容了
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold//向左移动一位,扩大原来的两倍
}
else if (oldThr > 0) // initial capacity was placed in threshold(初始容量设为阈值)
newCap = oldThr;
else { // zero initial threshold signifies using defaults//如果为零的话,就使用默认的阈值
newCap = DEFAULT_INITIAL_CAPACITY;(默认的容量)
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);(默认的阈值)
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];//用新的容量值创建一个新的数组
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
当size的数量大于threshold这个值时,就进行扩容。原来的老数组长度大于零,
newThr = oldThr << 1; // double threshold//向左移动一位,扩大原来的两倍
Node
六、扩容之后做了一些什么操作?
table = newTab;
if (oldTab != null) {//老的数组不为空
for (int j = 0; j < oldCap; ++j) {//开始遍历
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;//把老的数组节点设为空
if (e.next == null)//如果这个数组下没有链表
newTab[e.hash & (newCap - 1)] = e;//就把数据这key值的哈希值与上新的数组长度-1
else if (e instanceof TreeNode)//这是红黑树的情况
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order//下面就是数组下有链表,有值
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {//这个地方就是数组下面有链表,并且把链表下的数据放到新的数组当中。
next = e.next;
if ((e.hash & oldCap) == 0) {//这是原来的索引,通过递归
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
(扩容之后,原来的数组和链表的位置是如何迁移到扩容后的数组当中的呢?以及位置是如何计算的呢?这一块的代码没有太搞明白)
七、什么时候生碰撞?
也就是问题三种,部分代码:
for (int binCount = 0; ; ++binCount) {//这里就是插入链表
if ((e = p.next) == null) {//如果链表的下一个是空,就创建一个节点,
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//当链表的长度大于16时,就转为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//// key已经存在并且相等,就把这个节点替换
break;
p = e;
}
}
//如果你插入是,key不为空,并且原来的节点不为空,并且返回替换掉的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
也就是说,首先通过((n-1)& hash)算出数组下标位置,当这个位置已经占用的话,就会插入到这个数组节点对应的链表中,也就是说这时候发生了碰撞。
当这个链表长度大于8时,就会转换为红黑树
这就是我对HashMap的理解。可以关注我的公众号共同学习探究
我的公众号:Lucidastar
