近十几年,神经网络语言建模(Language Modeling, LM)一直是人工智能领域的研究热点,多种神经网络结构被引入到语言建模中。其中,前向神经网络是最早被引入到语言建模中的神经网络结构,随后是循环神经网络,包括标准循环神经网络、长短期记忆循环神经网络和门限循环单元神经网络,接着卷积神经网络也在语言建模中取得了出乎意料的成功。
1. 前言
语言建模(Language Modeling, LM)作为人工智能领域的基础任务之一,在诸如自然语言处理(Natural Language Processing, NLP)、语音识别(Speech Recognition)、机器翻译(Machine Translation, MT)等以自然语言为处理对象的任务中起到了关键的作用。虽然语言建模仅在语音识别中有直接的应用,但对语言建模具有深刻的理解有助于更好地理解上述任务,语言建模的思想即是人工智能领域处理自然语言的基本思想。另外,语言建模的相关技术通常可以直接或者间接地应用到其他任务中。
在神经网络(Neural Network, NN)被成功应用于语言建模之前,主流的语言模型为N-gram模型,采用计数统计的方式,在离散空间下表示语言的分布。由于缺乏对词的相似性的有效表示,N-gram语言模型存在严重的数据稀疏问题。虽然引入平滑技术,但数据稀疏问题仍不能得到有效的解决。神经网络语言模型则采用分布式的方式表示词,即通常所说的词向量,将词映射到连续的空间内,有效地解决了数据稀疏问题。并且神经网络具有很强的模式识别能力,神经网络语言模型的性能远优于N-gram模型。但由于神经网络语言模型的计算复杂度远高于N-gram模型,在对实时性有要求的应用场合,如语音识别,仍采用N-gram语言模型。N-gram语言建模方面的研究,推荐阅读Goodman (2001)的论文,该篇论文对N-gram语言建模的相关技术进行了细致的对比分析,建模的工具包则可以参考SRILM。本文将只对神经网络语言模型进行详细的介绍,并分析不同神经网络结构在语言建模中的优劣。
2. 语言模型
语言建模的对象是自然语言,即人类文明发展过程中自然演化的语言,不包括编程语言、世界语等。但严格地讲,自然语言也并不完全是自然产生的,而是人为创造出来的。另外,自然语言的表现形式通常分为语音与文字,而语言建模主要针对某种自然语言对应的文字系统,因此将该任务称为“文字系统建模 (Writing System Modeling, WSM)”更为严谨。通常获取某种文字系统下的文本所表达的信息,需要了解对应文字系统的内部结构,以及其与相应自然语言的对应关系。而语言模型仅从文本中构建,能够表示的只有文字系统本身的内部结构信息。虽然采用“文字系统建模”更为严谨,但为了与主流的研究一致,仍然沿用“语言建模”的命名习惯。
假设为来源于某种自然语言的词序列,语言建模的目的就是构建该自然语言中词序列的分布,然后用于评估某个词序列的概率。如果给定的词序列符合语用习惯,则给出高概率,否则给出低概率。在语言建模过程中,采用了链式法则,单个词序列的概率被分解为序列中各个词的条件概率的乘积,而每个词的条件概率为给定其上文时的该词出现的概率。因此,上述词序列的概率可表示为:
不难看出,上述模型的成立时需要前提假设,即在词序列中,每个词只依赖于其上文,而与下文无关。不论是依据语言使用的直观体验,还是人工智能的诸多实践,都验证了该假设是不成立的。在自然语言处理中,如何同时考虑上下文信息已有许多研究成果,此处不进行展开讨论。
语言模型的目标是评估词序列的概率,模型的训练采用最大似然评估准则,最大化模型在训练数据上的似然概率。语言模型训练的目标函数就采用似然函数,即:
其中,为语言模型的参数,为正则项。
语言模型的性能通常采用困惑度(Perplexity, PPL)来衡量,困惑度的定义如下:
困惑度,即模型编码数据所需要的平均字节数的指数,用于衡量模型预测样本的好坏程度。语言模型的困惑度越小,意味着语言模型的分布更接近测试数据的分布。
3. 神经网络语言模型
神经网络语言模型引起广泛关注是在Bengio et al. (2003)提出前向神经网络(Feed-forward Neural Network, FNN)语言模型之后,但对神经网络语言建模的研究可以追溯到更早之前,如Schmidhuber (1996),Xu and Rudnicky (2000)等。但由于神经网络训练困难,基于当时的硬件条件模型训练的时间较长。直到Bengio et al. (2003)发布其研究成果,神经网络语言模型才引起学术界以及工业界的兴趣。随后Mikolov et al. (2010)将循环神经网络(Recurrent Neural Network, RNN)引入语言建模,使得语言模型的性能得到较大的提升。接着循环神经网络的改进版本,长短期记忆(Long Short Term Memory, LSTM)循环神经网络以及门限循环单元(Gated Recurrent Unit, GRU)神经网络,相继地被用于进一步改善语言建模的性能。另外,卷积神经网络也出乎意料地在语言建模中取得了成功,性能也能够与循环神经网络相比肩。
3.1 前向神经网络语言模型
前向神经网络,又被称为全连接(Fully Connected Neural Network)神经网络,是最早被引入到语言建模中的神经网络结构。前向神经网络一般可表示为:
其中,,为权重矩阵,为输入层的节点数, 为隐层的节点数,输出层的节点数,在语言模型中等于词典的大小,为直接连接输入层与输出层的权重矩阵,和分别为隐层和输出层的偏置项,为输出向量,为激活函数。
Bengio et al. (2003)提出的前向神经网络语言模型的结构如图1所示。由于前向神经网络不具备学习时序依赖关系的能力,如果预测当前词时,考虑所有上文会比较困难。一方面,当上文较长时,网络的输入节点数会较大;另一方面,当前词的上文是变长的,不易处理。因此,前向神经网络语言模型采用了与N-gram模型相似的方法处理上文信息,只考虑前个词,则当前词的条件概率近似地表示为:
此处,又引入了另一个假设,即当前词只依赖于前个词。
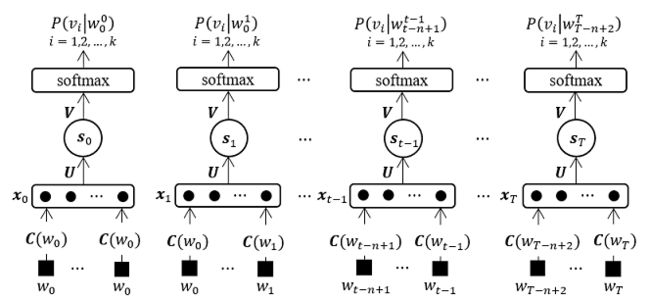
建立语言模型的首要工作是从训练数据集中构建词典,并为每个词赋予唯一的索引,然后构建特征矩阵,其中为词典的大小,为特征向量的大小。特征矩阵的每行为对应词的特性向量,即词向量,通过词的索引进行查找。当对当前词进行预测时,取其前个词的词向量,并按照序列顺序进行拼接,形成模型的输入向量,其中。模型的输出为当前上文信息下,词典中各个词的非归一化的条件概率,需要采用Softmax函数对输出概率进行归一化,即:
Bengio et al. (2003)在其2001年版本的论文中提出了两种模型结构。除了上述被称为直连结构(Direct Architecture)的模型,还有一种称为循环结构(Cycling Architecture)的模型。在循环模型中,针对词典中的每个词都训练了一个预测模型,每个模型只输出对应词的未归一化的条件概率,然后采用Softmax对所有输出进行归一化处理。两种模型在布朗语料库上的测试结果如下表所示:
| 序号 | 模型 | PPL | 备注 |
|---|---|---|---|
| 01 | 3-gram模型语言模型 | 348 | - |
| 02 | 直连前向神经网络语言模型 | 265 | - |
| 03 | 循环前向神经网络语言模型 | 270 | - |
实验结果显示,直连结构的模型性能与循环结构模型的PPL几乎相当。目前循环结构的模型已不再被关注,因为直连结构的模型的PPL略高,并且结构更紧凑。另外,实验数据显示前向神经网络语言模型的PPL远低于3-gram语言模型,体现了神经网络语言模型的优越性。在Bengio et al. (2003)的论文中,输入层与输出层之间的直接连接层以及隐层的偏置项对模型性能的影响得到了分析。引入直接连接层,能够帮助模型快速学习数据中的线性关系,但会使模型的泛化能力降低,从而使得模型的PPL值略有上升,但训练速度加快。而添加或者去除隐层的偏置项并不会对模型性能造成明显的影响。
3.2 循环神经网络语言模型
前向神经网络缺乏学习时序依赖的能力,而循环神经网络则是被设计用来处理时序问题的。Bengio et al. (2003)指出采用循环神经网络进行语言建模会获得更好的性能,而后Mikolov et al. (2010)对循环神经网络语言建模进行了研究,并取得了更好的效果。Mikolov et al. (2010)所采用的是标准循环神经网络,其一般结构可以表示为:
其中,为权重矩阵,为时刻隐层的状态。
循环神经网络引入了中间隐层状态,从而将信息沿着时序向后传播。在循环神经网络语言模型中,对当前词进行预测时,只需要将其上一个词的词向量作为输入,其余上文的信息通过隐层状态输入。因此,循环神经网络语言模型的结构与前向神经网络语言模型有所不同,其具体结构如图2所示。

循环神经网络的详细研究成果推荐参阅Mikolov (2012)的博士论文。除了循环神经网络语言模型本身的研究,论文还介绍了其他传统的语言建模技术,并与神经网络语言建模进行对比。另外,还提出了神经网络语言建模的优化方法,如通过模型组合降低PP L,基于词类加速模型计算等。模型的研究实验在宾州树库(Penn Tree Bank, PTB)上进行,部分测试结果如下表所示:
| 序号 | 模型 | PPL | 备注 |
|---|---|---|---|
| 01 | 3-gram语言模型 | 148.3 | - |
| 02 | 5-gram语言模型 | 141.2 | - |
| 03 | 前向神经网络语言模型 | 140.2 | - |
| 03 | 循环神经网络语言模型 | 124.7 | - |
从上表中的数据可以看出,循环神经网络语言模型具有显著的优势,而前向神经网络语言模型与5-gram语言模型相比,已不具备明显的优势了。
虽然标准循环神经网络被设计用于解决时序问题,但研究过程中发现,标准循环神经网络存在梯度缩减(Vanishing Gradient)或者梯度爆炸(Exploding Gradient)的问题,导致其无法学习时序上的长期依赖关系。针对这个问题,长短期记忆循环神经网络引入了门限机制,使得循环神经网络能够学习到更长期的时序依赖关系。长短期记忆循环神经网络由Hochreiter and Schmidhuber (1997)提出,而后被Gers and J. Schmidhuber (2000),Cho et al. (2014)等进一步改进优化,其一般结构可表示为:
其中,,,分别为输入门、遗忘门和输出门,为内部记忆单元,,,, ,,,,,,,,,均是权重矩阵,,,,和为偏置项,为隐层的激活函数,门限单元的激活函数,一般采用Sigmoid函数。
长短期记忆循环神经网络在语言建模中的最初研究来源于论文Sundermeyer et al. (2012),其语言模型的结构与图2所示的结构类似,只是将标准循环神经网络更换为长短期记忆循环神经网络。在宾州树库上进行试验,结果显示与标准循环神经网络语言模型相比,长短期记忆循环神经网络语言模型的PPL减少了8%。
门限循环单元神经网络作为与长短期记忆循环神经网络同等受欢迎的循环网络结构,同样受到语言建模研究者的青睐。门限循环单元网络也引入了门限机制来解决循环网络中梯度传递的问题,但其只引入了两个门机制,因此计算量会比相同规模的长短期记忆循环神经网络要少,其一般结构可以表示为:
其中,为重置门,为更新门,,,,,,,,均为权重矩阵,,,和为偏置项,为隐层的激活函数,门限单元的激活函数,一般也采用Sigmoid函数。
Jozefowicz et al. (2015)研究了不同循环神经网络结构在多种人工智能任务中表现,其中包括语言建模任务。针对语言建模任务的研究,同样是在宾州树库上进行的,试验结果如下表所示:
| 序号 | 模型 | PPL | 备注 |
|---|---|---|---|
| 01 | 标准循环神经网络语言模型 | 124.7 | - |
| 02 | 长短期记忆神经网络语言模型 | 81.4 | - |
| 03 | 长短期记忆神经网络语言模型 | 79.83 | 遗忘门的偏置项设为1.0 |
| 04 | 门限循环单元神经网络语言模型 | 91.7 | - |
在语言建模中,长短期记忆循环神经网络在诸多循环神经网络结构中显现出显著的优势,并且当将遗忘门的偏置项设为1.0时,模型的性能能够进一步提高。在这项研究成果发表之后,长短期记忆循环神经网络的遗忘门的偏置项通常默认设置为1.0。另外,此处值得一提,Jozefowicz et al. (2015)指出,除了语言建模任务,在其他任务中门限循环单元神经网络的性能均优于长短期记忆循环神经网络。但是实际情况却比较奇怪,目前在其他人工智能任务中,依然是长短期记忆循环神经网络出现的频率较高。
3.3 卷积神经网络语言模型
卷积神经网络(Convolutional Neural Network, CNN)的优势在于特征提取,并在计算机视觉(Computer Vision, CV)领域取得了巨大的成功。而对于语言建模这类序列问题,一直认为循环神经网络的性能会优于卷积神经网络。然而,Dauphin et al. (2016)尝试采用卷积神经网络进行语言建模,并引入了门限单元来降低深层卷积网络的训练难度,取得了出乎意料的成功,其模型的结构如图3所示。
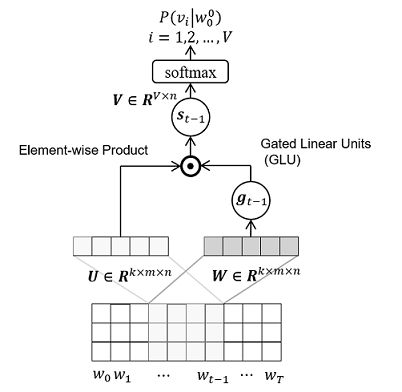
与上述的神经网络语言模型相比,除了神经网络结构不同之外,卷积神经网络语言模型的输入数据的形式也有所改变。对当前词进行预测时,将上文词序列的词向量按顺序进行拼接,形成特征矩阵。卷积核的高度与向量的大小一致,需要设计多种宽度的卷积核,并且相同尺寸的卷积核可以有多个,然后在特征矩阵上进行一维卷积,采用最大池化(Maxpooling)操作得到最终的特征向量。该特征向量作为网络输出层的输入,而输出层与上述神经网络语言模型一致。Dauphin et al. (2016)使用的实验语料库为百万级词语料库(One Billion Word Bench, OBWB),实验结果如下表所示:
| 序号 | 模型 | PPL | 备注 |
|---|---|---|---|
| 01 | 长短期记忆神经网络语言模型 | 43.9 | 1层,2048个节点,1GPU |
| 02 | 长短期记忆神经网络语言模型 | 39.8 | 2层,2048个节点 ,1GPU |
| 03 | 长短期记忆神经网络语言模型 | 30.6 | 2层,分别为8192,1024个节点,32GPUs |
| 04 | 卷积神经网络语言模型 | 38.1 | 13层,1268个节点,1GPU |
根据上表的数据,取得最好结果的模型是长短期记忆循环神经网络语言模型,但是该模型的规模巨大,训练成本非常高。在训练成本相当的情况下,卷积神经网络由于并行性较高,可以采用较大规模的网络结构,得到与长短期记忆循环神经网络相当的结果。可以说卷积神经网络与基于注意力机制的转换网络(Transformer)类似,主要优势在于高并行性,能够训练规模较大的模型。但在语言建模这类时序问题上仍存在明显的缺陷,首先由于卷积网络的平移不变性,无法区分词的顺序,针对这个问题的解决方法是引入了位置向量。另一个问题是卷积网络不能学习时序上的长期依赖关系,只是从词序列中提取出丰富的N-gram特征。对于循环神经网络和卷积神经网络,哪个更适合用于语言建模并没有确定的结论,但需要明白各自的优劣。循环神经网络可以学习时序上的长期依赖关系,但由于计算量的问题限制了模型的规模;而卷积神经网络虽然缺乏长期依赖关系的表示能力,但由于其高并行性,可以训练较大规模的网络,提取丰富的N-gram特征。
4. 概括总结
相对于传统的语言建模技术,神经网络语言建模技术具有显著的优势。采用分布式表示方法,将词映射到连续空间,有效地解决了数据稀疏问题,并且获得的词向量能够体现出词与词之间的相似性。另外,由于神经网络的强大的模式学习能力,在采用PP L为性能指标时,神经网络语言建模远优于传统的语言建模方法。在多种神经网络结构中,循环神经网络与卷积神经网络均优于前向网络,而两者不分伯仲,各有优劣。其中,循环神经网络的诸多变形中,以长短期记忆循环神经网络的性能最佳。虽然神经网络语言模型目前取得最好的结果,但仍然存在诸多需要进行改进的问题。近十几年,许多优化技术被提出用于改进神经网络语言建模的性能。针对神经网络语言建模的研究基本可以分为两个方向,其一是减少神经网络语言模型的计算量,包括训练阶段和预测阶段;另一个方向是改变数据的输入形式,从而引入更多的自然语言中的模式,从而提高模型的性能。
神经网络语言建模在实际应用中的最大障碍就是其计算量过大,导致无法满足实时性要求,因此在语音识别的实际应用中,仍然倾向于采用N-gram语言模型。甚至在没有实时性要求的应用场合,其计算的时间成本也是不能接受的。神经网络语言模型的计算量主要集中在模型的输出层,模型的输出层的网络节点数等于词典的大小,一般能达到几十万,甚至几百万。由于需要采用Softmax对输出概率进行归一化处理,不可避免的需要对所有节点进行计算,导致较大的计算量。降低神经网络语言模型的计算量的研究,也就主要是减少输出层的计算量。迄今为止,已有许多优化技术被提出,用于加速神经网络语言模型的计算,包括重要性采样(Importance Sampling)、层级Softmax(Hierarchical Softmax)、噪声对比评估(Noise Contrastive Estimation, NCE)等。这些优化技术均能够有效的改善神经网络语言模型的计算速度,但其中部分只能够加速训练阶段的计算,如重要性采样和噪声对比评估,并且大多数都是以牺牲模型精度为代价。这些加速技术在实际应用中也会存在诸多问题,而且时间成本仍然相对较高,因此仍然需要研究出更有效的加速技术。
在神经网络语言建模中,文本数据的表示可以分为两个层面:句子和词。针对这两个层面的数据表示,都有许多研究成果被提出,尤其是针对词的表达,目的均是希望将更多的自然语言中的模式输入语言模型中。语言建模过程中,文本的最小表示单位为词,并采用分布式表示方式,即通常所说的词向量。然而,语言(更准确地讲是文字系统)的最小表示单位并不是词,如英文的词由多个字母组成,中文的词由一个或多个字符组成,而单个字符又可以拆分为偏旁部首,韩文的词一般也有多个字符,字符又有多个音节字符。丰富词表示的方法就将字符级别或者更低级别的信息引入到词向量中。目前相关的研究大多针对特定的语言进行,甚至需要对应语言的专业知识。对于句子层面,研究的目的则是在预测当前词时,能够同时利用上下文的信息,而不是只利用单向的文本信息。
作者:施孙甲由 (原创)