原文链接
本页面提供了如何配置和优化使用大型状态的应用程序的指南。
概述
为了让Flink应用程序在大规模集群上可靠的运行,必须满足两个条件:
- 应用必须能可靠的获取checkpoint
- 失败后,需要足够的资源来满足输入数据流
第一部分讨论如何更好地执行checkpoint。最后一部分展示了一些关于计划分配多少资源的最佳实践。
监控状态和检查点
监控checkpoint行为的最简单方法是通过UI的checkpoint部分。checkpoint监控文档展示了如何访问可用的checkpoint指标。
当增加checkpoint时,特别感兴趣的两个数字是:
- 操作符启动它的checkpoint的延迟时间:这个时间当前没有直接暴露,但是对应于:
`checkpoint_start_delay = end_to_end_duration - synchronous_duration - asynchronous_duration`
如果触发checkpoint的延迟时间总是非常高时,表明**checkpoint barriers**需要很长时间才能从Source到达操作符。这通常表明系统在一个恒定的反压力下运行。
- 在对齐过程中缓冲的数据量。对于精确一次的语义,Flink在接收多个输入流的操作符上对齐流,在对齐过程中缓冲一些数据。理想情况下,缓冲的数据量是很少的,较多的数据意味着来自不同输入流的checkpoint barrier在不同的时间被收到。
注意:当出现瞬时的反压力,数据倾斜,或网络问题,这些数字会偶尔增高。然而,如果这些数字一直很高,这就意味着Flink将许多资源放入了checkpoint。
优化Checkpoint
Checkpoint是根据应用配置的间隔定期触发的。当执行Checkpoint需要的时间比Checkpoint间隔更长时,下一个Checkpoint在当前执行中的Checkpoint完成之前不会触发。默认情况下,当前正在执行的Checkpoint完成之后会立即触发下一个Checkpoint。
当Checkpoint完成的时间通常比间隔时间还要长(例如,因为状态比预期的要大,或者存储Checkpoint的速度突然变慢),系统就会不断的产生新的Checkpoint(新的Checkpoint在完成之后立即产生)。这意味着太多的资源被绑定在Checkpoint上,而操作符很少进行处理。这种行为对使用异步Checkpoint状态的流应用可能影响较小,但仍然可能会影响总体应用程序性能。
为了防止这种情况,应用可以定义一个Checkpoint最小间隔时间
StreamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
这个间隔是Checkpoint完成之后和新的Checkpoint开始之间的最小间隔时间。下图演示了它对检查点的影响。
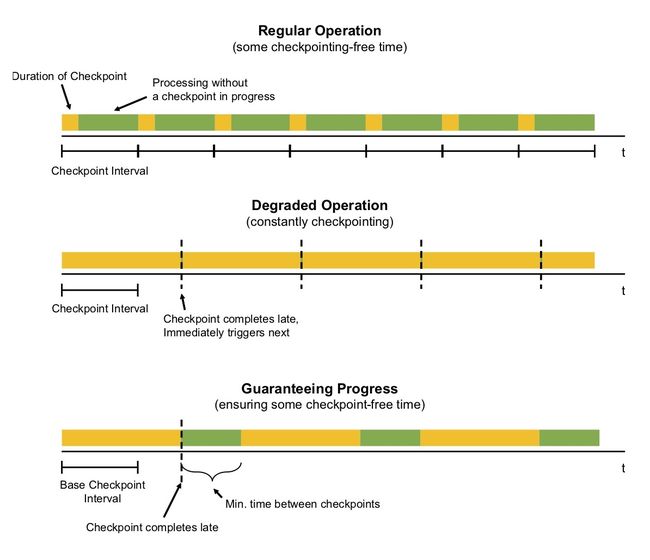
注意:可以配置应用程序(通过CheckpointConfig),允许在进程中同时存在多个Checkpoint。对于具有较大状态的Flink应用程序,这通常会将过多的资源绑定到Checkpoint。当一个savepoint被手动触发时,它可能与正在进行的Checkpoint同时进行。
优化网络缓冲
在Flink 1.3 之前,网络缓冲数量的增加也导致了Checkpoint时间的增加,因为保留更多的in-flight数据意味着Checkpoint barrier被延迟了。从Flink 1.3 开始,每个输出/输入通道使用的网络缓冲数量是受限的,因此网络缓冲可以配置为不影响Checkpoint时间(请参见网络缓冲配置)。
尽可能进行异步Checkpoint
当状态进行异步快照时,Checkpoint的性能要比同步快照好。特别是在具有多个join, Co-functions或者窗口的越复杂的流应用中,这可能会产生深远的影响。
为了使状态被异步快照,应用程序必须做两件事:
使用由Flink管理的状态: 状态托管意味着Flink提供状态存储的数据结构。当前,keyed state是这样的,它是接口
ValueState,ListState,ReducingState背后的抽象。使用支持异步快照的状态后端。在Flink 1.2中,只有RocksDB状态后端使用完全异步快照。从Flink 1.3 开始,基于堆的状态后端也支持异步快照。
上述两点意味着,大状态通常应该保存为keyed状态,而不是operator状态。
优化RocksDB
许多大型FLink流式应用的状态存储使用的RocksDB State Backend。它的规模远远超出主内存,并且能够可靠的存储大keyed状态。
不幸的是,RocksDB的性能可能因配置而异,而且几乎没有关于如何正确地调优RocksDB的文档。例如,默认的配置是针对SSD的,在机械磁盘上执行次级的优化。
增量式的Checkpoint
相对于全量式的Checkpoint,增量式的Checkpoint能够显著的减少Checkpoint的时间,而代价(潜在的)是更长的恢复时间。核心思想是,增量式的Checkpoint只记录对之前已完成的Checkpoint的变更,而不是一个完整的,自包含的状态后端备份。就像这样,增量式的Checkpoint基于前一个Checkpoint。Flink利用了RocksDB内部的备份机制,该机制随着时间的推移而自我整合。因此,Flink中的增量式Checkpoint不会无限期的增长,旧的Checkpoint最终会被自动的整合和删除。
虽然我们强烈建议在大型状态下使用增量式Checkpoint,但是请注意,这是一个新特性,并且当前默认是不开启的。要开启这个特征,用户可以在初始化 RocksDBStateBackend 时将构造函数中相应的布尔标识设为 true,例如:
RocksDBStateBackend backend =
new RocksDBStateBackend(filebackend, true);
向RocksDB传递选项
RocksDBStateBackend.setOptions(new MyOptions());
public class MyOptions implements OptionsFactory {
@Override
public DBOptions createDBOptions() {
return new DBOptions()
.setIncreaseParallelism(4)
.setUseFsync(false)
.setDisableDataSync(true);
}
@Override
public ColumnFamilyOptions createColumnOptions() {
return new ColumnFamilyOptions()
.setTableFormatConfig(
new BlockBasedTableConfig()
.setBlockCacheSize(256 * 1024 * 1024) // 256 MB
.setBlockSize(128 * 1024)); // 128 KB
}
}
预定义选项
Flink对于不同的设置,为RocksDB提供了一些预定义的选项集合,它们可以通过如下示例进行设置RocksDBStateBacked.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM).
我们希望随着时间的推移可以积累更多的文档。当您发现一组可以很好的工作并且似乎代表某些工作负载的选项时,可以自由地提供这些预定义的选项概要文件。
重要: RocksDB是一个本地库,它的内存不是来自JVM,而是处理器的本地内存。分配给RocksDB的任何内存都必须考虑在内,通常是通过减少TaskManager的相同数量的JVM内存。不这样做的结果是,可能会导致YARN/Mesos/等终止JVM进程来分配比配置更多的内存。
容量评估
本节讨论为了使Flink作业可靠的运行,应该如何决定为作业分配多少资源。容量评估的基本原则是:
正常的操作应该有足量的空间,而不会经常运行在反压模式。关于如何检查应用是否运行在反压模式下,参见[反压监控] (https://ci.apache.org/projects/flink/flink-docs-release-1.4/monitoring/back_pressure.html)。
在程序在无故障运行期间,没有反压时需要的最多资源外,提供一些额外的资源。这些资源需要能够“覆盖住”程序恢复期间积累的输入数据。资源的多少取决于恢复操作恢复需要执行多次时间(这依赖于当失败时,需要被加载到新TaskManager中的状态的大小),以及该场景需要多长时间才能恢复。
重要: 应该根据Checkpoint激活来建立基线,因为Checkpoint连接了一定数量的资源(例如网络带宽)。临时的反压通常是OK的,重要的部分是负载峰值期间,在catch-up阶段,或者外部系统(Sink中的写操作)突然变慢时。
某些操作(如大窗口)会给下游操作符带来更大的负荷:在窗口情况下,当窗口正在构建时,下游操作符可能几乎没有什么工作,但是当窗口释放时,它们就会增加负载。对下游并行度的规划需要考虑窗口发出的数量和需要处理的速度有多快。
重要: 为了便于以后添加资源,请确保将数据流程序的最大并行度设置为一个合理的数字。最大的并行度定义了在重新缩放程序(通过保存点)时,可以设置程序并行度的程度。
Flink内部的bookkeeping跟踪在max-parallelism-many key groups粒度下的并行状态。Flink的设计努力使它的效率高到最大的并行度,即使是执行低并行度的程序。
压缩
Flink为所有的Checkpoint和savepoint提供了压缩选项(默认:关闭)。当前,压缩总是使用snappy压缩算法(version 1.1.4),但是我们计划在未来支持自定义的压缩算法。在keyed状态下,压缩工作在key-groups的粒度下,即,每个key-group能被单独的压缩,这对于弹性部署是很重要的。
可以通过ExecutionConfig激活压缩:
ExecutionConfig executionConfig = new ExecutionConfig();
executionConfig.setUseSnapshotCompression(true);
注意: 压缩选项对增量快照没有影响,因为它们使用的是RocksDB的内部格式,它总是使用box的snapp压缩。