本篇我们的主题是数据可视化的利器——seaborn库的使用。
Seaborn是基于matplotlib,在matplotlib的基础上进行了更高级的API封装,便于用户可以更加简便地做出各种有吸引力的统计图表。可以说,seaborn是matplotlib的很好补充,而且能够高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
01
安装seaborn
我们可以使用pip安装。
![]()
或者,也可以使用conda进行安装
![]()
02
了解seaborn API基本形式
seaborn画图函数,主要针对pandas的DataFrame或numpy数据,有以下几种主要形式:
sns.图名(x='X轴 列名', y='Y轴 列名', data=原始数据df对象)
sns.图名(x='X轴 列名', y='Y轴 列名', hue='分组绘图参数', data=原始数据df对象)
sns.图名(x=np.array, y=np.array[, ...])
03
导入第三方库
使用时候,我们需要将过程中会使用到三方库进行import。除了主要的seaborn之外,我们还会需要使用到matplotlib和pandas库,主要基于“薪酬”数据进行可视化操作。同时,我们还需要设置字体和负号的RC参数,让其能正常显示。

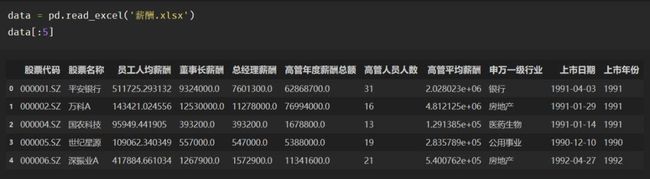
薪酬数据可以通过百度网盘进行下载,此处使用pd.read_excel()进行读取。
(数据链接:https://pan.baidu.com/s/19sdHiB5PRy-VSc3S0sYDnQ)
04
基础的直方图、曲线图等我们就不再一一示范,本篇中,我们主要示范散点图、箱线图、小提琴图、单变量密度估计图、双变量密度估计图、热力图、矩阵散点图的绘制。
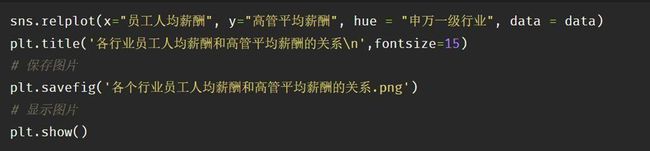
1、散点图,表现两个变量之间的关系
散点图中,每个点为数据集中的一个观察值,seaborn库中,我们可以使用relplot()生成散点图。
参数x:x轴上的数据,此处我们使用“员工人均薪酬”
参数y:y轴上的数据,此处我们使用“高管平均薪酬”
参数hue:可以让我们在图中添加另一个维度,通过散点的不同颜色表示不同含义。此例中,我们用不同颜色表示不同行业,使用“申万一级行业”做色调
参数data:可视化的数据对象,此处我们使用data这个已经赋值了薪酬数据的DataFrame

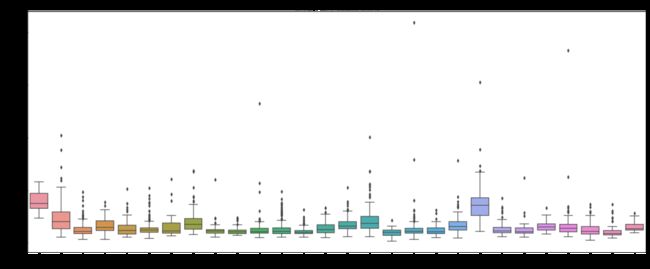
2、箱线图,表现分布情况
箱线图中,可以展示上边缘、下边缘、中位数和两个四分位数,同时可以很方便观察到离群点。seaborn库中,我们可以使用catplot(kind='box')生成箱线图。
参数x:x轴上的数据,此处我们使用“员工人均薪酬”
参数y:y轴上的数据,此处我们使用“高管平均薪酬”
参数kind:表示画图的类型(如:箱线图,默认为小提琴图)
参数data:可视化的数据对象,此处我们使用data这个已经赋值了薪酬数据的DataFrame
参数ax:所选择的画布如果传入orient则画出的盒形图是横向的

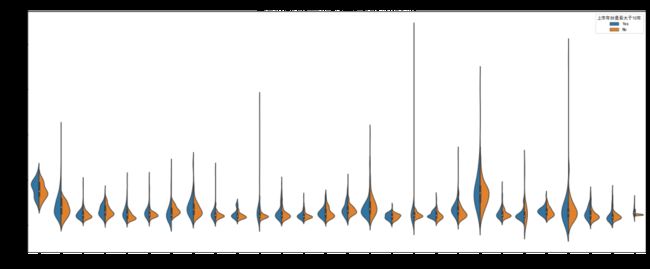
3、小提琴图,表现分布情况
小提琴图结合了箱形图和密度图的特征,主要用来显示数据的分布形状。中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表 95% 置信区间,而白点则为中位数。在seaborn库中,我们可以使用catplot()生成小提琴图。
参数x:x轴上的数据,此处我们使用“申万一级行业”
参数y:y轴上的数据,此处我们使用“员工人均薪酬”
参数kind:表示画图的类型(如:箱线图,默认为小提琴图)
参数data:可视化的数据对象,此处我们使用data这个已经赋值了薪酬数据的DataFrame
参数ax:所选择的画布
参数hue:不同类别的数据,分别绘制小提琴
参数split:为True时,例如:把同属于银行的数据按照上市年份是否大于10年,分别绘制在小提琴图的两侧

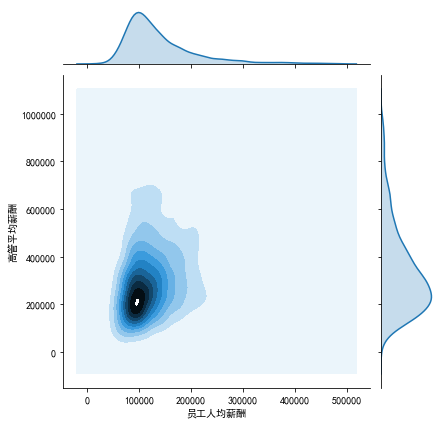
4、双变量密度估计图,展现数据的分布和关联情况
双变量密度估计图,既能展现单个变量的分布,也能展现双变量之间的关系。在seaborn库中,我们可以使用jointplot()来生成。
参数x:x轴上的数据,此处我们使用“员工人均薪酬”
参数y:y轴上的数据,此处我们使用“高管人均薪酬”
参数kind:表示外围单变量分布的表现形式(如:直方图)
参数data:可视化的数据对象,此处我们使用data这个已经赋值了薪酬数据的DataFrame

5、热力图,表示各个变量之间的相关系数
热力图可以展现多变量之间的相关系数,在seaborn库中可以使用heatmap()来绘制。
参数annot:是否显示数字
参数vmax:最大值
参数vmin:最小值
参数xticklabels:是否显示x轴标签
参数yticklabels:是否显示y轴标签
参数square:是否为正方形
参数data:可视化的数据对象


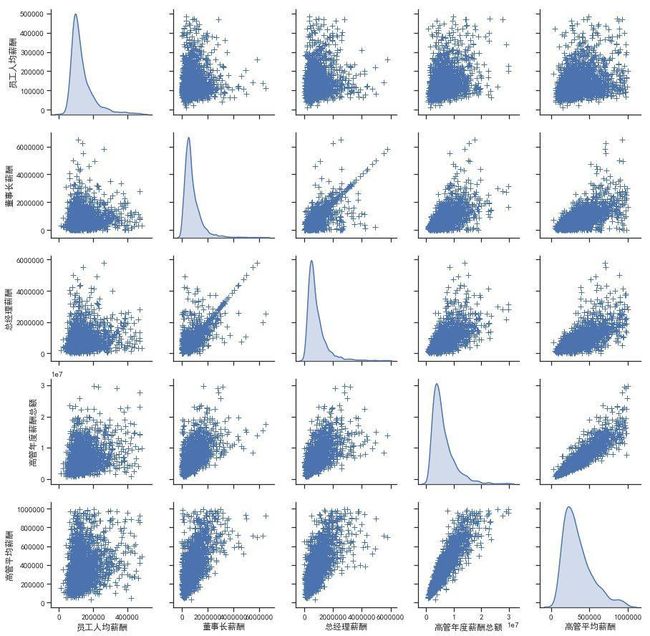
6、矩阵散点图,表现数据的分布
矩阵散点图,可以展现多个变量,两两之间的散点图,以及自身的分布规律。在seaborn中可以使用pairplot()绘制。
参数diag_kind:自身分布的展现类型(如:直方图,密度图)
参数markers:散点图中点的形状
参数plot_kws:调节点的大小,颜色,线的宽度等
参数diag_kws:展示形式的调整(如:密度图中十分填充)
参数data:可视化的数据对象

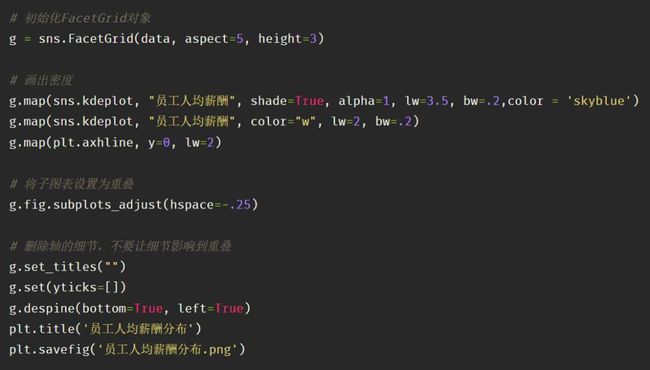
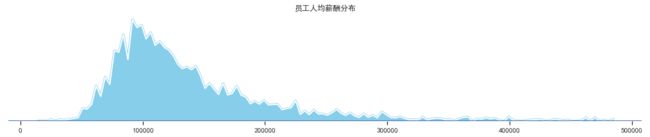
7、单变量密度估计图,展现单个变量的分布规律
单变量密度估计图,可以反映变量自身的分布规律。在seaborn中可以使用kdeplot()进行绘制。
参数shade:是否显示阴影
参数alpha:透明度
参数color:颜色
参数data:可视化的数据对象