NodeJS是单进程单线程[1]结构,适合编写IO密集型的网络应用。为了充分利用多核CPU的计算能力,最直接的想法是同时运行多个实例进程,但手动管理这些进程却是个麻烦事,不但要知道当前CPU的核心数以确定进程数量,还要为不同实例进程配置不同网络监听端口(Listening Port)避免端口冲突[2],另外还要监控进程运行状态,执行Crash后重启等操作,最后还得配合Load Balancer统一对外的服务端口:
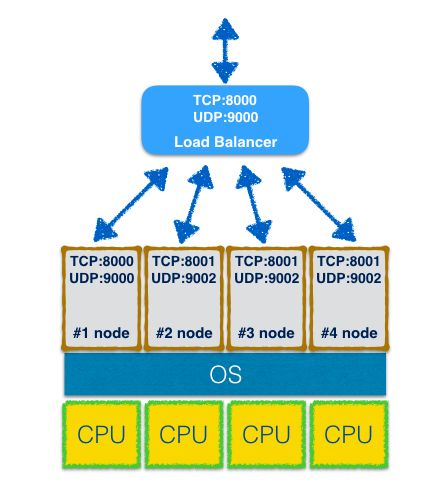
想想就好烦!幸好,NodeJS引入了Cluster模块试图简化这些体力劳动。使用Cluster模块可以运行并管理多个实例进程,而且无须为每个进程单独配置监听端口(当然如果你想的话也可以)。下面是Cluster模块的基本用法,一个子进程启动器:
//cluster_launcher.js
let cluster = require('cluster');
if (cluster.isMaster) {
// Here is in master process
let cpus = require('os').cpus().length;
console.log(`Master PID: ${process.pid}, CPUs: ${cpus}`);
// Fork workers.
for (var i = 0; i < cpus; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Here is in Worker process
console.log(`Worker PID: ${process.pid}`);
require('./tcpapp.js');
//require('./udpapp.js'); //uncomment if you need a udp server
}
代码很简单,运行后会产生一个Master进程及n个Worker子进程,n等于CPU核心数。
启动器本身代码(cluster_launcher.js)在Master和Worker子进程都会被执行,依据cluster.isMaster的值来区分运行在Master和Worker上的代码分支。Master进程的cluster对象上定义有fork方法,调用后操作系统会生成一个新的Worker子进程。Worker子进程除了从Master进程继承了环境变量和命令行等设置,另外还多了一个环境变量NODE_UNIQUE_ID来保存Worker进程的Id(由Master负责分配)。Cluster模块内部通过判断NODE_UNIQUE_ID的存在与否确定当前运行的进程是Master还是Worker:
cluster.isWorker = ('NODE_UNIQUE_ID' in process.env);
cluster.isMaster = (cluster.isWorker === false);
刚才提到使用Cluster模块管理多进程Node应用,可以不用单独为每个进程指定监听端口,也就是从使用者角度看每个进程使用同一个端口监听网络而不会发生端口冲突。这是怎么做到的呢?原来Node内部让TCP和UDP模块的对Cluster启动的情况做了特殊处理,接下来对TCP和UDP两种情况分别开8。
首先是TCP,按国际惯例,Hello World!。
//tcpapp.js
let http = require('http');
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
以上代码实现了一个最简单的HTTP服务器,在8000端口监听请求并返回“hello world”字符串。TCP是面向连接的协议,操作系统层面每个监听端口都对应一个 Socket用来监听网络上的TCP连接请求(Incoming Connection),每当握手成功操作系统就会创建一个新的Socket代表这个已建立的连接(Established Connection)用做后续的IO操作。单独运行上面的服务器的话,这两种Socket都属于同一个进程,也就是监听TCP连接和处理HTTP请求都在一个进程完成。以下步骤帮助确认这种情况:
$ node tcpapp.js &
[1] 51647 //pid
打开浏览器访问:http://localhost:8000 ,然后lsof查看进程socket的情况:
$ lsof -a -i tcp:8000 -P -l
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
Google 10268 501 97u IPv6 0xff13215c8e8c1ac7 0t0 TCP localhost:50807->localhost:8000 (ESTABLISHED)
node 38622 501 11u IPv6 0xff13215c8e8c1567 0t0 TCP *:8000 (LISTEN)
node 38622 501 12u IPv6 0xff13215c8e8c1007 0t0 TCP localhost:8000->localhost:50807 (ESTABLISHED)
可以看到同一个node进程上打开了两个Socket(DEVICE列的值不同),一个负责监听端口,一个负责已建立连接上的IO。一般来说TCP连接握手由操作系统在内核空间完成,不会形成性能瓶颈,单进程node应用的瓶颈在于应用逻辑,即使业务逻辑以IO为主,CPU消耗仍然比内核操作大得多。因此单进程node应用的瓶颈会在业务逻辑处理量增加到单CPU核心饱和时出现。
下面看看用cluster_launcher.js启动的情况,运行下面的命令:
$ node cluster_launcher.js &
[1] 28153
Master PID: 28153, CPUs: 4
Worker PID: 28155
Worker PID: 28156
Worker PID: 28154
Worker PID: 28157
可以看到一个Master进程启动了四个Worker子进程:
$ pstree 28153
-+- 28153 /usr/local/bin/node /tmp/demo/cluster_launcher.js
|--- 28154 /usr/local/bin/node /tmp/demo/cluster_launcher.js
|--- 28155 /usr/local/bin/node /tmp/demo/cluster_launcher.js
|--- 28156 /usr/local/bin/node /tmp/demo/cluster_launcher.js
\--- 28157 /usr/local/bin/node /tmp/demo/cluster_launcher.js
打开浏览器访问http://localhost:8000,然后lsof下进程的socket的情况:
$ lsof -a -i tcp:8000 -P -R -l
COMMAND PID PPID USER FD TYPE DEVICE SIZE/OFF NODE NAME
Google 10268 1 501 3u IPv6 0xff13215c8e8c1007 0t0 TCP localhost:50504->localhost:8000 (ESTABLISHED)
Google 10268 1 501 5u IPv6 0xff13215c8e8bffe7 0t0 TCP localhost:50547->localhost:8000 (ESTABLISHED)
Google 10268 1 501 10u IPv6 0xff13215c8e8c0547 0t0 TCP localhost:50548->localhost:8000 (ESTABLISHED)
node 28153 12710 501 17u IPv6 0xff13215c8e8c1567 0t0 TCP *:8000 (LISTEN)
node 28154 28153 501 14u IPv6 0xff13215c8e8c0aa7 0t0 TCP localhost:8000->localhost:50548 (ESTABLISHED)
node 28155 28153 501 14u IPv6 0xff13215c8e8bfa87 0t0 TCP localhost:8000->localhost:50547 (ESTABLISHED)
node 28156 28153 501 14u IPv6 0xff13215c8e8c1ac7 0t0 TCP localhost:8000->localhost:50504 (ESTABLISHED)
可以看到分配给Master和Worker进程的DEVICE(对应Protocol Control Block的内核地址)的值都不一样,说明各有各的Socket。Master进程只有一个处在Listening状态的Socket负责监听8000端口,Worker进程的Socket都是Established的,说明Worker进程只负责处理连接上的IO。同时也可以看到,三个Established状态的TCP连接[3]被分配给了三个Worker进程,也就是说,Cluster模块可以利用多进程并行处理同一端口的TCP连接:
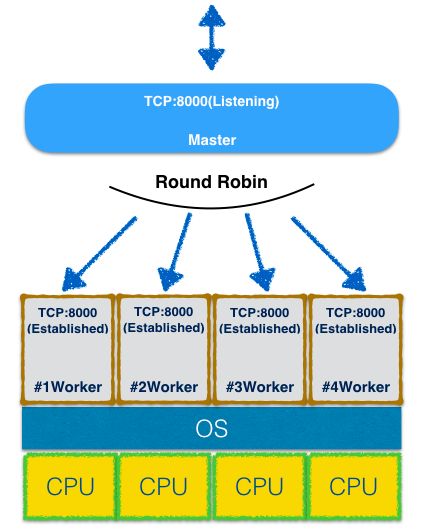
剩下的就要看每个Worker进程的负载是否均衡了。上图所示是Cluster模式下Established TCP连接的默认调度方式(除Windows以外),调度由Master进程负责,以Round Robin的方式将Established状态的连接IPC给Worker进程做进一步处理,这样看来各Worker的负载是平均的。
默认的调度策略(Round Robin)大多数时候可以工作的很好,连接按建立的顺序依次被分配到各Worker进程,每个CPU内核都可以得到充分利用。但是,这也意味着这种调度方式不能保证“同源(来自同一个IP)的连接”被同一个Worker进程处理,带来上层应用会话状态的管理问题。一般情况下可以使用redis等全局session store保存应用会话状态,对所有进程可见,然而不是所有的应用层状态都受业务代码掌控,能放入全局store,典型的例子是Socket.io 在建立WebSocket连接过程中的握手状态是保存在本地进程内存中的,而且目前没有提供接口控制保存策略,那么当通过Cluster模块启动Socket.io服务器时,同源的连接可能会被分配给不同Worker进程,出现握手失败的状况。解决的方法并不复杂,Master进程只需把同源IP的连接分配给同一个worker进程就可以了(这种调度方式有时被称作IP Hash),可惜Cluster模块目前并没提供这个选项,只能借助第三方插件了[4]。
除了默认的调度策略,还可以让OS的Process Scheduler来负责worker进程的调度(详见SCHED_NONE策略),这也是Windows上的默认策略,但在Linux下效果并不理想,这里不再赘述。
接下来是UDP的情况:
//udpapp.js
let dgram = require('dgram');
let server = dgram.createSocket('udp4');
server.on('error', (err) => {
console.log(`server error:\n${err.stack}`);
server.close();
});
server.on('message', (msg, rinfo) => {
console.log(`server got: ${msg} from ${rinfo.address}:${rinfo.port}`);
});
server.on('listening', () => {
var address = server.address();
console.log(`server listening ${address.address}:${address.port}`);
});
server.bind(9000);
上面的代码启动UDP服务器,在9000端口监听UDP packet。用cluster_launcher.js启动并lsof查看socket结果如下:
$ node cluster_launcher.js &
Master PID: 23263, CPUs: 4
Worker PID: 23266
Worker PID: 23265
Worker PID: 23267
Worker PID: 23264
server listening 0.0.0.0:9000
server listening 0.0.0.0:9000
server listening 0.0.0.0:9000
server listening 0.0.0.0:9000
$ lsof -a -i udp:9000 -P -R -l
COMMAND PID PPID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 23263 12710 501 17u IPv4 0xff13215c8a237c97 0t0 UDP *:9000
node 23264 23263 501 14u IPv4 0xff13215c8a237c97 0t0 UDP *:9000
node 23265 23263 501 14u IPv4 0xff13215c8a237c97 0t0 UDP *:9000
node 23266 23263 501 14u IPv4 0xff13215c8a237c97 0t0 UDP *:9000
node 23267 23263 501 14u IPv4 0xff13215c8a237c97 0t0 UDP *:9000
可以看到Master和Worker进程的实际上共享同一个UDP Socket(DEVICE指向地址相同),但区别是Worker子进程调用了Bind方法而Master进程没有,Master进程在这里的作用仅仅是管理Worker进程“声明”使用到的UDP Socket:每当Worker调用Bind方法监听某UDP端口时,内部会通过IPC询问Master是否有可重用的UDP Socket,Master收到询问后会在本地Socket缓存中查找,没有则新创建一个并缓存起来,之后把相应的UDP Socket IPC给Worker,Worker收到后在其上完成真正的Bind操作。这样处理结果就是Cluster模块把UDP packet的分发任务交给OS的Process Scheduler负责:当9000端口收到一个UDP packet时,Process Scheduler就会随机分配给一个Worker做进一步处理:
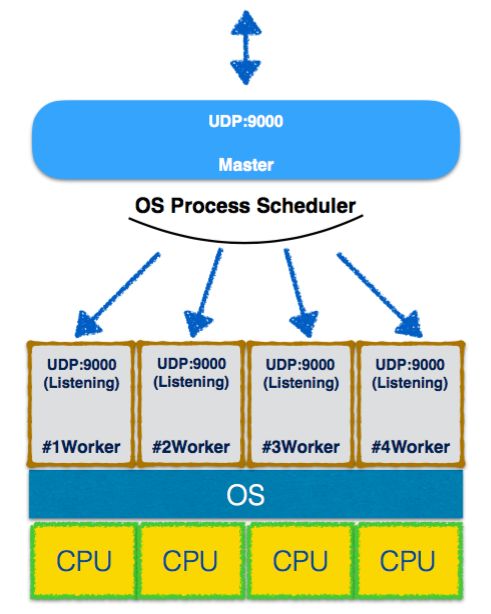
以上是对Cluster模块在处理TCP和UDP时内部机理的一些分析发掘,希望能对各位使用好Cluster模块有所帮助,如有纰漏敬请指出。
[1]这里指用户的编程模型是单进程单线程的,NodeJS进程本身是多线程的,例如,NodeJS的底层库libuv用线程池将文件系统的同步操作转化成异步操作,只不过这一切对用户透明。
[2]Linux Kernel 3.9之后支持了SO_REUSEPORT选项,可以让多个进程共享同一个端口,但libuv目前没有采用。
[3]访问服务器时,浏览器通常会同时打开多个TCP连接发送HTTP请求,加快页面的加载速度。
[4]indutny/sticky-session可以解决Socket.io的问题。
本文原创,欢迎转载,但请注明出处