我们平时所写的OC代码,底层都是C/C++代码。

我们有两个方法可以打印内存大小:
// 获得NSObject实例对象的成员变量所占用的大小
NSLog(@"%zd", class_getInstanceSize([NSObject class]));
// 获得obj指针所指向内存的大小
NSLog(@"%zd", malloc_size((__bridge const void *)obj));
输出:8,16
那么,上面两个值具体是如何得到的呢?
有答案来说是内存对齐,所以,下面就去了解一下内存对齐是个啥?
1. 内存对齐
数据在内存中存储往往不是像我们想象的那样,一个挨着一个毫无空间浪费的顺序排列。为了存取的效率是按一定规则存放的,这个存放的规则就是内存对齐。
2. 为什么需要内存对齐?
虽然内存的基本单位是字节,但是大部分处理器存取数据的往往不是按字节来的,CPU把内存当成是一块一块的,一般会以双字节、4字节、8字节、16字节、甚至32字节为单位来存取。每次内存存取都会产生一个固定的开销,减少内存存取次数将提升程序的性能,所以CPU一般会以2/4/8/16/32字节为单位来进行存取操作,我们将上述这些存取单位,也就是块大小称为内存存取粒度。
eg:现在考虑4字节存取粒度的处理器取int类型变量(32位系统),也就是说该处理器一次读取4个字节的数据。
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的连续4个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),还要将两块数据进行偏移,最后合并后放入寄存器。
对一个内存未对齐的数据,进行了这么多额外的操作,这对CPU的开销很大,大大降低了CPU性能,所以还是很需要内存对齐的。
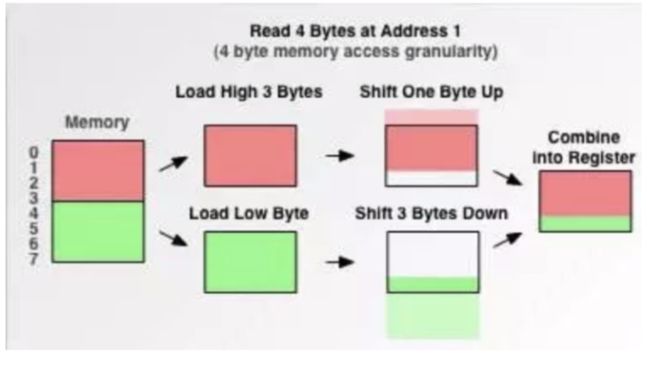
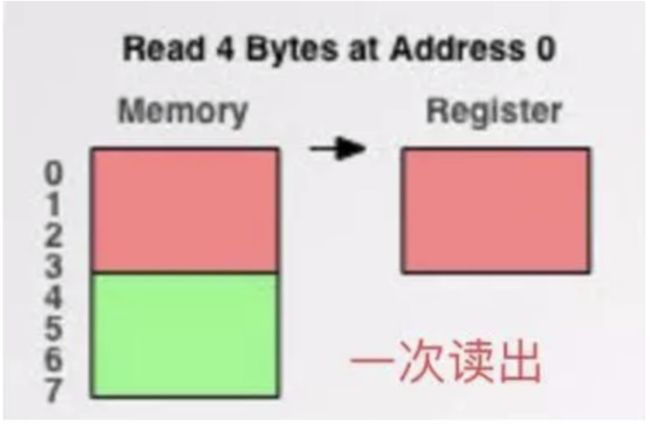
现在有了内存对齐的,int类型数据只能存放在按照对齐规则的内存中,比如说0地址开始的内存。
那么现在该处理器在取数据时一次性就能将数据读出来了,而且不需要做额外的操作,提高了效率。
我们知道指针存的是一个地址,在32位操作系统里面,最大寻址空间位0~2^32-1,即4个字节(32位)就可以表示,相应的在64位操作系统环境中用8个字节表示指针。所以,指针本身所占控件大小与所指对象所占空间大小无关,只与操作系统有关。
- 32位编译器
| 类型 | char | char*(指针) | short int | int | unsigned int | float | double | long | long long | unsigned long |
|---|---|---|---|---|---|---|---|---|---|---|
| 字节占用 | 1 | 4 | 2 | 4 | 4 | 4 | 8 | 4 | 8 | 4 |
- 64位编译器
| 类型 | char | char*(指针) | short int | int | unsigned int | float | double | long | long long | unsigned long |
|---|---|---|---|---|---|---|---|---|---|---|
| 字节占用 | 1 | 8 | 2 | 4 | 4 | 4 | 8 | 8 | 8 | 8 |
3. 内存对齐规则
每个特定平台上的编译器都有自己的默认“对齐系数”,程序猿可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
我们来看下内存对齐的规则:
数据成员对齐规则:
struct的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照temp = min(对齐系数,数据成员长度),temp的整数倍进行补齐。结构体的整体对齐规则
在数据成员按照第1步完成各自对齐之后,结构体本身也要进行对齐。对齐会按照temp = min(max(成员1,成员2,成员3),对齐系数),temp的整数倍进行补齐结构体作为成员
如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。
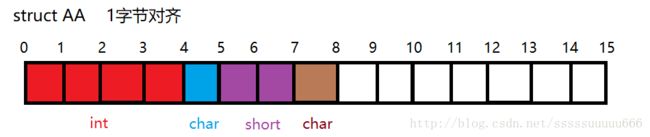
例1:字节对齐系数为1
- 第一步:成员数据对齐
#pragma pack(1)
struct AA {
int a; //长度4 < 1 按1对齐;偏移量为0;存放位置区间[0,3]
char b; //长度1 = 1 按1对齐;偏移量为4;存放位置区间[4]
short c; //长度2 > 1 按1对齐;偏移量为5;存放位置区间[5,6]
char d; //长度1 = 1 按1对齐;偏移量为6;存放位置区间[7]
//整体存放在[0~7]位置区间中,共八个字节。
};
#pragma pack()
- 第二步:整体对齐
整体对齐系数 = min(max(int,char,short,char), 1) = 1,所以不需要再进行整体对齐,整体大小就为8.
图示如下:
例2:字节对齐系数为2
- 第一步:成员数据对齐
#pragma pack(2)
struct AA {
int a; //长度4 > 2 按2对齐;偏移量为0;存放位置区间[0,3]
char b; //长度1 < 2 按1对齐;偏移量为4;存放位置区间[4]
short c; //长度2 = 2 按2对齐;偏移量要提升到2的倍数6;存放位置区间[6,7]
char d; //长度1 < 2 按1对齐;偏移量为7;存放位置区间[8];共9个字节
};
#pragma pack()
-
第二步: 整体对齐
整体对齐系数 = min((max(int,short,char), 2) = 2,将9提升到2的倍数,则为10.所以最终结果为10个字节。
图示如下:(X为补齐部分)
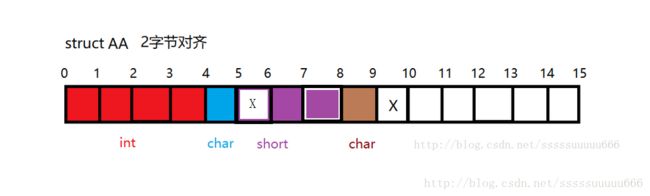 image.png
image.png
例3:字节对齐系数为4
- 第一步:成员数据对齐
#pragma pack(4)
struct AA {
int a; //长度4 = 4 按4对齐;偏移量为0;存放位置区间[0,3]
char b; //长度1 < 4 按1对齐;偏移量为4;存放位置区间[4]
short c; //长度2 < 4 按2对齐;偏移量要提升到2的倍数6;存放位置区间[6,7]
char d; //长度1 < 4 按1对齐;偏移量为7;存放位置区间[8];总大小为9
};
#pragma
- 第二步: 整体对齐
整体对齐系数 = min((max(int,short,char), 4) = 4,将9提升到4的倍数,则为12.所以最终结果为12个字节。
图示如下:(X为补齐部分)
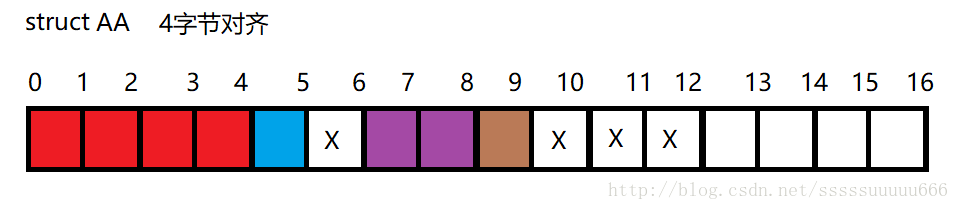
例4:字节对齐系数为8
- 第一步: 成员数据对齐
#pragma pack(8)
struct AA {
int a; //长度4 < 8 按4对齐;偏移量为0;存放位置区间[0,3]
char b; //长度1 < 8 按1对齐;偏移量为4;存放位置区间[4]
short c; //长度2 < 8 按2对齐;偏移量要提升到2的倍数6;存放位置区间[6,7]
char d; //长度1 < 8 按1对齐;偏移量为7;存放位置区间[8],总大小为9
}
#pragma pack()
- 第二步: 整体对齐
整体对齐系数 = min((max(int,short,char), 8) = 4,将9提升到4的倍数,则为12.所以最终结果为12个字节。
例5:OC举例
Person类:
@interface Person: NSObject
{ // 8
int _one;
double _two;
int _three;
char _four; // 1
char _five;
}
@end
我们来继续分析一下:
isa指针 // 长度8 = 8 , 按8对齐;偏移量为8;存放位置区间[0,8]
int _one; // 长度4 < 8,按4对齐;偏移量为12;存放位置区间[12,15]
double _two; // 长度8 = 8 , 按8对齐;偏移量为16;存放位置区间[16,23]
int _three; // 长度4 < 8,按4对齐;偏移量为24;存放位置区间[24,27]
char _four; // 长度1 < 8,按1对齐;偏移量为28;存放位置[28]
char _five; // 长度1 < 8,按1对齐;偏移量为29;存放位置[29]
整体对齐应该为8的倍数,所以为32。Person类为32个内存,实际使用为30个。
我们通过下面的代码:
NSLog(@"%zd", class_getInstanceSize([NSObject class]));
也是可以验证的,这也是结构体对齐规则。
注意:在oc类中,分配内存对齐时 后面如果有小的内存是可以直接占据前面虚拟的无占据的分配内存的。
但是使用NSLog(@"%zd", malloc_size((__bridge const void *)obj));得到的,为啥不一样呢?
malloc_size这个方法返回的是系统给这个对象分配了多少空间,iOS系统内存再次对齐,最后为16的倍数。
这是runtime中看到的代码:
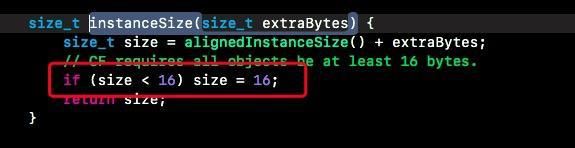
所以:最一开始的NSObject对象实际只使用了8个字节,但是系统给分配了16个字节。