社交网络分析方法(Social Network Analysis, SNA),是由社会学家根据数学方法、图论等发展起来的定量分析方法。历史学家 Lawrence Stone 将其作为方法论引入群体传记学中。 如同学者 Charles Wetherell 所述:
“个人关系组成之集合体的概念化,提供历史学家评估古人于何时、如何,及为何利用亲族与非亲族关系。 社会网络关系分析家发现,人们须从不同的社会关系中、不同的人身上,寻求情绪上与经济上的支持。 因此,仅研究人们如何于危机时刻利用亲族关系已不足够;相反地,历史学的研究必须涵盖过去人们如何为不同目的而利用亲族与朋友关系,以及此一利用关系的优势与限制。 事实上,社会网络关系做为一种研究方法不仅有助于此一论辩,更帮助历史学家 Charles Tilly 所提出的挑战:将平民百姓的日常生活与大规模的社会变迁作有意义的链接。 ”
本文将以宋代政治人物苏轼为例,从苏轼及其亲友的往来书信中归纳出社交网络关系(“朋友圈”),然后借助 networkx 对其社交网络关系进行可视化和分析。

0 准备工作
按照惯例,先导入相关包。除了常用的几个包外,还有这次的主角—— networkx 包。该包用于创建网络对象,以各种数据格式加载或存储网络,并可以分析网络结构、建立网络模型、设计生成网络的算法以及绘制网络。
import sqlite3
import numpy as np
import pandas as pd
import networkx as nx
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
接着,设置数据库地址(使用 SQLite 数据库,保存在本地),方便加载数据:
db = 'F:\pydata\dataset\CBDB_aw_20180831_sqlite.db'
数据来源于 CBDC(China Biographical Database),即中国历代人物传记数据库
1 搜索人物
从数据库中查找苏轼的 person_id:
# 查找 person_id 函数
def getPersonId(person_name):
''' Get person_id
@param person_name: str
@return person_id: str
'''
sql = '''
SELECT c_personid
FROM biog_main
WHERE c_name_chn = '{0}'
'''.format(person_name)
try:
person_id = str(pd.read_sql(sql, con=sqlite3.connect(db)).iloc[0, 0])
return person_id
except:
print("No such person.")
# 查找苏轼的 person_id,注意要使用繁体中文
person_id = getPersonId('蘇軾')
查找
person_id有待优化,应支持简体输入以及人物别名
# 打印 person_id
print(person_id)
'3767'
2 获取数据
在获得目标人物(苏轼)的 person_id 后,需要通过该 id 在数据库中查找相关记录,得到苏轼与其亲友、及其亲友与其他人的书信往来关系:
这里联查了 3 张表,分别是传记主表(biog_main)、关系信息表(assoc_data)、关系代码表(assoc_codes)
sql = '''
SELECT a.c_personid person_id
, b1.c_name_chn person_a
, c_assoc_id assoc_id
, b2.c_name_chn person_b
, a.c_assoc_code assoc_code
, c.c_assoc_desc_chn assoc_desc
FROM assoc_data a
LEFT JOIN biog_main b1
ON a.c_personid = b1.c_personid
LEFT JOIN biog_main b2
ON a.c_assoc_id = b2.c_personid
LEFT JOIN assoc_codes c
ON a.c_assoc_code = c.c_assoc_code
WHERE (a.c_personid = {0}
OR a.c_personid IN (
SELECT c_personid
FROM assoc_data
WHERE c_assoc_id = {0}
AND c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436'))
OR a.c_assoc_id IN (
SELECT c_assoc_id
FROM assoc_data
WHERE c_personid = {0}
AND c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436')))
AND a.c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436')
'''.format(person_id)
person_assoc = pd.read_sql(sql, con=sqlite3.connect(db))
在对数据库执行了查询操作后,我们将得到一个 DataFrame,其中包括了:
- person_id:关系人A id
- person_a: 关系人A姓名
- assoc_id:关系人B id
- person_b:关系人B姓名
- assoc_code:关系代码
- assoc_desc:关系名称
# 查看 DataFrame 信息
person_assoc.info()
RangeIndex: 2595 entries, 0 to 2594
Data columns (total 6 columns):
person_id 2595 non-null int64
person_a 2595 non-null object
assoc_id 2595 non-null int64
person_b 2595 non-null object
assoc_code 2595 non-null int64
assoc_desc 2595 non-null object
dtypes: int64(3), object(3)
memory usage: 121.7+ KB
关系人A或关系人B为苏轼的记录数:
person_assoc[(person_assoc['person_id'] == int(person_id)) | (person_assoc['assoc_id'] == int(person_id))].count()
person_id 550
person_a 550
assoc_id 550
person_b 550
assoc_code 550
assoc_desc 550
dtype: int64
DataFrame 中包含了 8 种关系(均为书信往来关系):
# 打印所有关系的名称
for i in person_assoc['assoc_desc'].unique():
print(i)
致書Y
被致書由Y
答Y書
收到Y的答書
致Y啓
收到Y的啓
答Y啓
收到Y的答啓
3 生成社交网络
从包含边列表(至少两列节点名称和零个或多个边缘属性列)的 DataFrame 返回图。
# 生成图
person_G = nx.from_pandas_edgelist(person_assoc, source='person_a', target='person_b', edge_attr='assoc_desc')
图中描述了 906 个关系,其中包含 614 个唯一个体。苏轼的社交网络中的随机个体在社交网络的其余部分平均有近 3 个联系人。由于存在大量与苏轼亲友有书信往来的但与苏轼本人无关系的记录,整个社会网络的密度较低。
# 打印图信息
print(nx.info(person_G))
print('Density: {0}'.format(nx.density(person_G)))
Name:
Type: Graph
Number of nodes: 614
Number of edges: 906
Average degree: 2.9511
Density: 0.004814257855051517
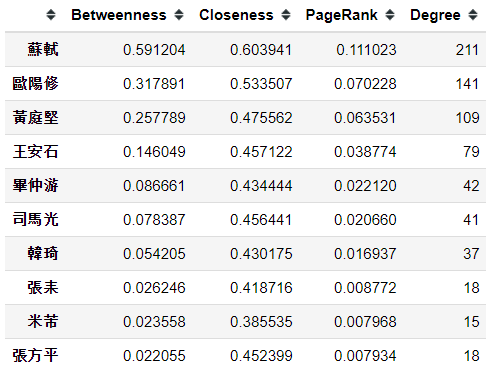
接着,通过 networkx 生成社交网络的中心度和 PR 值,中心度包括:接近中心度(或紧密中心度,Closeness centrality),中介中心度(或间距中心度,Betweenness centrality),度中心度(Degree centrality),
person_betweenness = pd.Series(nx.betweenness_centrality(person_G), name='Betweenness')
person_person = pd.Series.to_frame(person_betweenness)
person_person['Closeness'] = pd.Series(nx.closeness_centrality(person_G))
person_person['PageRank'] = pd.Series(nx.pagerank_scipy(person_G))
person_person['Degree'] = pd.Series(dict(nx.degree(person_G)))
desc_betweenness = person_person.sort_values('Betweenness', ascending=False)
desc_betweenness.head(10)
4 可视化
在绘制可视化图形前,需要提前创建一致的图形布局,这里选用了 kamada_kawai_layout 的图形布局:
#pos = nx.circular_layout(person_G)
pos = nx.kamada_kawai_layout(person_G)
#pos = nx.shell_layout(person_G)
#pos = nx.spring_layout(person_G)
#pos = nx.random_layout(person_G)
绘制图形的函数:
# 绘制函数
def draw_graph(df, top):
''' Draw Graph
@param df: DataFrame
@param top: int, numbers of top
'''
nodes = df.index.values.tolist() #生成节点列表
edges = nx.to_edgelist(person_G) #生成边列表
# 生成无向度量图
metric_G = nx.Graph()
metric_G.add_nodes_from(nodes)
metric_G.add_edges_from(edges)
# 生成 Top n 的标签列表
top_labels = {}
for node in nodes[:top]:
top_labels[node] = node
# 生成节点尺寸列表
node_sizes = []
for node in nodes:
node_sizes.append(df.loc[node]['Degree'] * 16 ** 2)
# 设置图形尺寸
plt.figure(1, figsize=(64, 64))
# 绘制图形
nx.draw(metric_G, pos=pos, node_color='#cf1322, with_labels=False)
nx.draw_networkx_nodes(metric_G, pos=pos, nodelist=nodes[:top], node_color='#a8071a', node_size=node_sizes[:top])
nx.draw_networkx_nodes(metric_G, pos=pos, nodelist=nodes[top:], node_color='#a3b1bf', node_size=node_sizes[top:])
nx.draw_networkx_edges(metric_G, pos=pos, edgelist=edges, edge_color='#d9d9d9', arrows=False)
nx.draw_networkx_labels(metric_G, pos=pos, font_size=20, font_color='#555555')
nx.draw_networkx_labels(metric_G, pos=pos, labels=top_labels, font_size=28, font_color='#1890ff')
# 保存图片
plt.savefig('tmp.png')
最后,生成网络图,图中的每个节点都对应苏轼朋友圈中的一个人,而在朋友圈中与苏轼最亲近的 20 个人的节点以红底蓝字突出显示,节点大小对应程度大小:
draw_graph(desc_betweenness, 20)
从图中不难看出,苏轼处于该社交网络的最中心,而“六一居士”欧阳修、王安石、黄庭坚等社交达人也有着较高的中心程度。有趣的是,宋代书法四大家——苏黄米蔡,原来都处于同一个社交网络中(其实是笔者孤陋寡闻了)。
5 One More Thing
CBDB 还提供了查询 API,可以通过输入人物的姓名或 id 快速查找人物的传记信息,下面以朱熹为例简单介绍下如何使用该 API:
import requests
url = 'https://cbdb.fas.harvard.edu/cbdbapi/person.php?name=%E6%9C%B1%E7%86%B9&o=json'
my_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Host': 'cbdb.fas.harvard.edu',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
def getJSON(url, headers):
""" Get JSON from the destination URL
@ param url: str, destination url
@ param headers: dict, request headers
@ return json: json, result
"""
res = requests.get(url, headers=headers)
res.raise_for_status() #抛出异常
res.encoding = 'utf-8'
json = res.json()
return json
# 获取 json
json = getJSON(url, headers=my_headers)
# 解析 json,打印基本信息
json['Package']['PersonAuthority']['PersonInfo']['Person']['BasicInfo']
{'PersonId': '3257',
'EngName': 'Zhu Xi',
'ChName': '朱熹',
'IndexYear': '1189',
'Gender': '0',
'YearBirth': '1130',
'DynastyBirth': '南宋',
'EraBirth': '建炎',
'EraYearBirth': '4',
'YearDeath': '1200',
'DynastyDeath': '南宋',
'EraDeath': '慶元',
'EraYearDeath': '2',
'YearsLived': '71',
'Dynasty': '宋',
'JunWang': '吳郡',
'Notes': "Zhu Xi [3257] Shengzheng, p. 2224; Jiangxi TZ, 10.21b; SHY:ZG, 72.33a, 36a. CBD, 1, 587-597.From Hartwell's ACTIVITY table:1181: Apt. Liangzhe Dong tiju1182: In office as Liangzhe Dong tiju1182: As Liangzhe Dong tiju, impeached Tang Zhoungyou.淳祐中從祀孔廟。\x7f 《唐代人物知識ベース》記其生卒年為:1130 - 1200.\x7f\x7f"}