回头想想,从最开始学习编程开发到现在也有五年多了,记得自己的第一个作品是一个基于WEBQQ协议的QQ聊天机器人,从它身上我学到了至今甚至以后很长时间都需要的一个知识点——HTTP协议。
自打互联网诞生以来,HTTP协议始终就是非常重要的一个环节,因为网络中的很大部分数据都是基于HTTP协议来传输的。比如浏览网页,比如你整天刷朋友圈、刷微博,甚至你现在能够看到这篇文章,它们都是通过HTTP协议送到你的面前的。
如果你搞懂了HTTP协议,那么你就可以做很多有趣的东西。
比如做个QQ聊天机器人让你的QQ能够自动与人聊天;
比如做个机器人让它每天替你去做QQ等级加速的任务;
比如做个论坛或贴吧的自动发帖器自动抢沙发;
比如你突然心血来潮想把自己微博下的几千条微博全部删掉。
是不是有点意思呢?
其实这些都是小玩意儿。
还记得那些关于爬虫的文章吗?
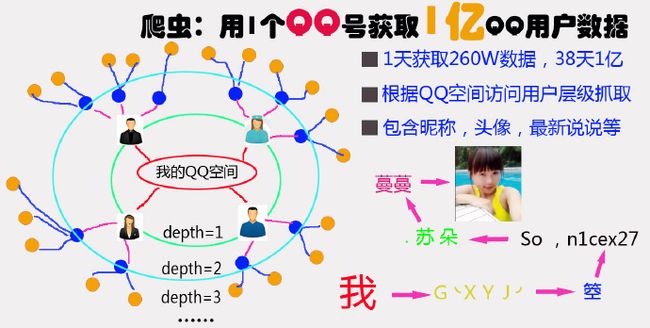
这是一个大数据时代,但是普通开发者如何才能拿到大数据呢?
爬虫就是一个很好的解决方案。不论QQ空间还是知乎,不论淘宝还是京东,都可以利用爬虫爬去他们的数据拿来做我们自己的数据分析。
那么,所谓爬虫到底是什么呢? 其实爬虫就是一个根据一定的规则发送HTTP请求的小程序。
现在你知道HTTP的重要性了吧?
下面我们就来讲解下HTTP协议。
什么?你不要听?没意思?那么如果我告诉你利用爬虫还可以爬小黄图呢?是不是已经迫不及待了呢?
咳咳咳~
不要乱想了!
还是先来学HTTP吧!!!
昨天已经说过了,HTTP协议主要分为两部分,Request和Response,下面我们一个一个来讲解下。
Request
GET / HTTP/1.1
Host: 61.135.169.125
User-Agent: Mozilla/5.0 (Macintosh;Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36
Cookie: BAIDUID=F2AA23D33A77970AEAC
GET / HTTP/1.1
GET是一种HTTP的请求方法,还有POST。这是最常用的两种方法,GET其实就是在进行最普通的URL访问。每当我们在浏览器的地址栏输入一个网址进行访问的时候都是发起了一个GET类型的HTTP请求。比如这个网址http://php.net/manual/zh/book.yaf.php
访问这个地址发出的HTTP数据就是:
GET /manual/zh/book.yaf.php HTTP/1.1
HTTP/1.1是HTTP的版本,是99年发布出来的,目前主流的浏览器都是采用这个版本。
ps:在去年中旬HTTP/2也发布了,不过貌似只有谷歌在Chrome中已经全面启用了HTTP/2。
Host: 61.135.169.125
Host其实就是目标服务器地址,可以是域名,也可以是IP地址。比如上面那个URL,在HTTP中的表现就是
Host: php.net
看到这里是不是知道了什么呢?
没错,昨天题目的答案其实你去访问一下这个IP地址就知道了。
User-Agent: Mozilla/5.0 (Macintosh;Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36
User-Agent是指浏览器,通过它告诉服务器这个request是通过什么浏览器发出来的。
Cookie: BAIDUID=F2AA23D33A77970
现在你肯定已经明白了访问网页就是不断的发送与接收HTTP数据,那么需要登录的网站是如何识别你的登录状态的呢?
答案就是Cookie!
Cookie你可以把它理解为一种临时的身份标示。当你登录一个网站,这时候实际上就是从服务器获得了一个cookie,这个cookie保存在你的浏览器上,这样你之后再发送的HTTP请求就会自动的带上这个cookie发送给服务器,服务器通过这个cookie就能识别到你是一个已经登录的用户,这样就可以访问到你的私人数据了。
聪明的你一定猜到了什么。
没错,所谓退出登录其实就是清除了cookie。
Response
HTTP/1.1 200 OK
Server: bfe/1.0.8.14
Date: Sat, 27 Feb 2016 13:59:27 GMT
Content-Type: text/html;charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: private
Expires: Sat, 27 Feb 2016 13:59:27 GMT
Content-Encoding: gzip
HTTP/1.1 200 OK
HTTP/1.1 前面已经说过了,HTTP的版本。
200是HTTP的返回状态代码。200 OK 代表正常返回。其他常见的还有404代表找不到页面。302代表重定向跳转。502代表服务器错误。
Server: bfe/1.0.8.14
Server顾名思义就是服务器,这里告诉了我们网站是用的什么服务器及服务器的版本,我这个抓的是百度的包,这里是bfe,据说是是百度自己研发的一套前端接入系统。我们常见的Web服务器主要是Apache和Nginx。
Date: Sat, 27 Feb 2016 13:59:27 GM
这个也很好理解,就是服务器的响应时间。
Content-Type: text/html;charset=utf-8
返回的数据类型,text/html意思就是html代码,charset指的是编码格式。我们常用的编码格式就是utf-8和gbk。我们常用的数据类型还有 image/jpeg,image/png,text/css,text/json,text/xml等等。
今日题目:
VGhlIHR3ZW50eS1maWZ0aCBGaWJvbmFjY2kgbnVtYmVyIGlzPw==
注:将答案回复给公众号【不谈代码】即可赚取M币。