文章标签:深度学习 人工智能 paddlepaddle 线性回归 入门 实战 教程
内容标签:深度学习流程简介、神经网络简介、学习率介绍、损失介绍、线性回归
前言
该系列文章相对于极简入门系列要更注重理解部分,同时对代码进行解读,依旧不会牵扯太复杂的数学原理部分,以入门为主。随后会补出实战视频,方便大家进一步学习深度学习。
点击进入PaddlePaddle入门专题页面,获取完整教程信息
点击进入往期PaddlePaddle文章、极简入门专题页面
少了些滑稽,多了些代码。
当然,难度也会有所增加,需要多自己尝试才能更好的适应PaddlePaddle框架。
此外,入门深度学习是需要一定的编程、数学基础。
Python的熟练度虽然要求不高,但必须得有一个小项目的经验(比方说写一个小爬虫,翻转并拼接一些图片、飞机大战等)。
如果连Debug的基础都没有,入门深度学习将会举步维艰,即使更换其它深度学习框架也会如此。
PaddlePaddle目前还是比较适合入门,尤其是英语水平较低的同学,官方提供的原生中文文档将更适合你。
同时PaddlePaddle是国产开源的框架,虽然跟主流的TensorFlow、Pytorch还有些距离,但五脏俱全,所以欢迎你的加入。
PaddlePaddle官方网站:https://www.paddlepaddle.org.cn/
PaddlePaddle官方用户交流群: Q 796771754,也可以在官方网站中找到。
该篇文章将带你编写属于你的第一个PaddlePaddle深度学习程序,包括训练和预测部分。此外,这篇文章会告诉你深度学习的一些入门级思想,方便在接下来的学习中拥有更好的效率。
一、准备工作
1、打开PaddlePaddle官方文档方便学习
2、打开你最拿手的IDE
3、准备好PaddlePaddle环境,可以在PaddlePaddle官网上获得最新版安装方案
4、调整好坐姿开始复制代码
二、深度学习简介
相信大家都经历过很多考试了,即使没有也没关系,你肯定有一套自己的学习方法。
深度学习跟日常的应试流程也颇为相似,都是需要在考试(测试)前不断的刷题(训练)、更正错误(反向传播)、最后通过考试得到自己真正的分数。
下面的一个流程图就是对比了一下应试的刷题部分,可以参考一下。
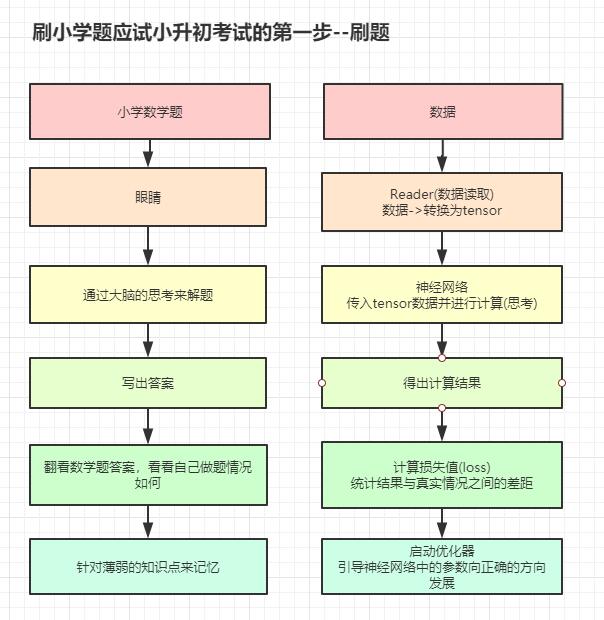
左侧的流程你可能会比较熟悉,而右边的会比较陌生,因为右侧的机器"学习"的过程。
看不懂没有关系的,这不就开始介绍了吗[滑稽]
在下方术语解释部分 看不懂没有关系,直接跳过就行了,实战之后相信你就能理解了
1、小学数学题--数据
在生活中要想应试获取好的成绩,自然需要获取一些信息来辅助应试,以增加自己的经验
在深度学习中这一个环节也是必不可少的,一个好的模型也是需要大量、高质量的数据集支持才可以的。
模型
可以理解为记录神经网络各种结构、参数的文件,每个人的脑子都可以看做一个独特的模型。
数据集
分为训练集、验证集、测试集。其中训练集就相当于练习题,写的越多收获的经验也就越多。验证集相当于模拟考试,用来评估模型收敛情况,也就是平时练习小学数学题的情况。测试集相当于高考,评估模型总体情况,因为在数据集划分上验证集和测试集很相似,而且都不参与反向传播的过程,往往在实际操作中将两者合并操作来提升调试模型的效率。
2、Reader--数据读取器
有了数据之后就得想方设法把它塞入神经网络里面。
在PaddlePaddle框架中,需要把原始数据转换成Numpy的数组对象后方可让数据转换成Tensor(张量)
Tensor
深度学习框架中的一种数据格式,可以提供给机器运算的一种通用数据形式。
3、机器的大脑--神经网络
得到Tensor之后,就可以把它放入机器的大脑中来计算了,在深度学习中有很多网络结构(CNN、RNN...),本节将会搭建一个非常小的神经网络,用一个全连接层(FC)来完成"小学考试任务"(线性回归任务)。
全连接层(FC)
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来 。[摘自百度百科]
4、计算损失
数据经过神经网络的思考之后就一定是正确的吗?就像在做数学题一样,遇到陌生的题,很难确定自己的答案是否正确。
计算损失就是对比自己的答案与正确答案之间的差距,知道自己的得分情况之后也就能明确下一步自己要强化的方向了。
本节将会使用均方差损失函数来计算损失。
均方差
均方差表示的就是样本数据的离散程度。标准差就是样本平均数方差的开平方,标准差通常是相对于样本数据的平均值而定的,通常用M±SD来表示,表示样本某个数据观察值相距平均值有多远。 [摘自百度百科]
5、优化器
优化器并不是可有可无的东西。
在你得知自己练习题的测试成绩(损失)后,是不是要发奋图强了?那么该怎样去提升成绩呢?
优化器就是为了提升成绩而设定的,这里会牵扯到反向传播,你也可以去了解反向传播的具体步骤,但在这篇文章中你只需要了解反向传播是可以让"学习成绩"逐渐变好的一种策略就够了,相当于"查看错题集"->"对错题进行思考、纠正"
反向传播
反向传播算法主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。 [摘自百度百科]
三、实战部分
本次实战就拿一个乘法和加法的简单计算题为题库(数据集),在不告诉机器计算步骤的情况下,让它自己去摸索解题方案,并对它进行期末考核,从而完成线性回归任务。
简略步骤是:定义数据->定义张量、网络等组件->输入数据->开始学习(训练)->期末考核(预测)
注意!输入数据这一个部分是在定义张量、网络等组件之后才进行的!
1、导入PaddlePaddle框架和必要的第三方库
import paddle.fluid as fluid
import numpy as np
2、定义数据集(小学数学题题库)
这里定义形如y = 10x + 3的题目,已知x的值为某个数值,让机器求出y的值。
data_X = [[1], [2], [3], [5], [10]] # 相当于练习题
data_Y = [[13], [23], [33], [53], [103]] # 相当于练习题答案
先给他5道题作为练习题吧。
3、定义张量格式
定义张量格式是什么鬼?刚刚没有介绍这个东西啊!
定义张量的格式,只是为了方便让框架知道我们想给机器喂什么样的数据,提前做一下心理准备。
我们只要把数据的格式、类型等信息定义好,框架就会明白该怎样把原始的数据转换成张量了。
但需要注意的是,这里并不是立即转化的,这些只是定义,只有输入数据之后才会转换(上面定义的data是不是还没有与下方的代码建立联系呢?对,他们还没有建立联系,还只是个陌生人)
x = fluid.layers.data(name="x", shape=[1], dtype="float32")
y = fluid.layers.data(name="y", shape=[1], dtype="float32")
name="x"这个参数可能不太好理解,下面贴出一个示例代码,可别把这个示例代码也给copy到py文件里啊!
张某人 = fluid.layers.data(name="老张", shape=[1], dtype="float32")
在Python中,你喊出张某人,那么Python就知道对应的那个对象就是上面定义的那一行代码。
但在框架内部,如果想得到刚刚的那个x对象,有时候可能不太容易,毕竟那么多张某人,万一你手滑了让变量名冲突了可咋办,要是PaddlePaddle叫错人就尴尬了。所以在定义这个张某人变量时就把他独一无二的外号也给定义下来,以后在框架内部直接喊外号就可以避免这个问题了。
shape=[1]则是定义数据的形状,[1]代表是一维数据,且第一维只有一个值,[3,9]代表是二维数据,第一维有3组数据,每组数据中又含有9个数据。一个RGB彩色图片的shape就可以定义为三维数据[通道数(R、G、B),长,宽],例如[3,32,32]是一个RGB三通道宽高均为32像素的图片。这里因为我们每次只会给机器提供一道数学题,所以x的形状自然为[1],又因为一道题只对应一个答案,所以y的形状也是[1]。
至于dtype="float32"这个参数,就是定义张量的数据类型,为了方便训练,这里就全部定义为浮点型。
4、定义神经网络
神经网络也是深度学习中比较重要的一个部分,它的设计决定了机器的思路。
这里我们定义一个全连接层作为机器的"大脑"。
out = fluid.layers.fc(input=x, size=1)
input的意思是输入,那我们就把刚刚定义为x的张量传递给它,等传入"数学题"的时候,数据就会先变成x这个张量,然后通过input这个参数加载到这个全连接层,out是这个全连接层的计算结果。注意,此时还没有传入数据!
size这个参数就是神经元的个数,就像脑细胞一样,越多思考的就越多,精度上去了,速度却下来了。这里因为是小学题,所以一个神经元就够用了。
5、定义计算损失策略
loss = fluid.layers.square_error_cost(input=out, label=y) # 使用均方差损失函数进行计算损失
avg_loss = fluid.layers.mean(loss) # 对损失求平均(至于为什么要定义这句,下一节会介绍这个问题)
input=out和label=y,分别是刚刚神经网络思考后的结果和练习题的答案,它们两个做对比之后就可以计算出损失值了。
6、定义优化器
opt = fluid.optimizer.SGD(learning_rate=0.01) # 使用随机梯度下降策略进行优化,学习率为0.01
opt.minimize(avg_loss) #拿到损失值后,进行反向传播
7、初始化PaddlePaddle训练环境
place = fluid.CPUPlace() # 初始化CPU运算环境
start = fluid.default_startup_program() # 初始化训练框架环境
exe = fluid.Executor(place) # 初始化执行器
exe.run(start) # 准备执行框架
这里使用CPU运算,至于为什么用CPU而不是GPU(这就一个简单的线性回归任务,要什么GPU,要什么自行车啊!)
fluid.default_startup_program()这句代码可能会让很多人一脸懵逼,这节不做介绍,知道有这一句就可以了。
8、开始做练习题(训练)
for i in range(100): # 把刚才的5道题的题库,练习100遍!
for x_, y_ in zip(data_X, data_Y): #从题库里每次抽出一道题
x_ = np.array(x_).reshape(1, 1).astype("float32") # 将抽出的题目转换成numpy对象
y_ = np.array(y_).reshape(1, 1).astype("float32") # 将抽出的答案转换成numpy对象
info = exe.run(feed={"x": x_, "y": y_}, fetch_list=[loss])
if i % 10 == 0:
print(info[0])
这里解释一下为什么要转换成Numpy对象,因为数据种类实在是太多了,为了有一个较统一的方案来读取数据,这里就使用Numpy作为一种通用数据格式(这个解释有些片面,实际与性能之类都有关系)
exe.run(feed={"x": x_, "y": y_}, fetch_list=[loss])中feed就是数据输入的入口,"x"就是刚刚定义的外号"老张"而非张某人,而x_是刚才转换为Numpy对象的那个变量名,也就是带有练习题数据的Numpy对象。
fetch_list里则是填写你想要获得哪些神经网络的输出。这里因为是训练解读,我们并不关心他每道题的结果,只关心做题的情况是好还是不好,所以这里就只获取loss损失值即可。
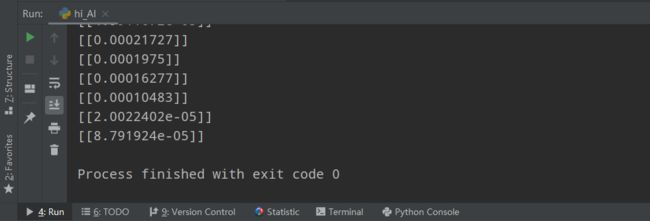
这里我们可以看到,损失已经降到非常低了,但我们还少了一步,就是保存模型。
fluid.io.save_inference_model(dirname="infer.model", feeded_var_names=["x"], target_vars=[out], executor=exe)
保存模型的方法也是非常简单,dirname不多说就是模型要保存的文件夹路径,infer.model就是我随便起的文件夹名了,这里大家可以随意发挥,只要符合命名规范即可。
feeded_var_names里的"x"还是刚刚定义的外号"老张",为什么要有这个参数呢?因为在预测的时候我们依旧需要对数据进行转换(原始数据->Numpy对象->所定义好的张量格式->张量),在预测时我们一般只会有原始数据,原始数据转换为Numpy的格式也是非常简单的。但我们可能不知道在训练模型时,用途为输入数据的那个张量格式是什么,所以这里把刚刚定义为输入的x给保存进去,方便预测时使用。
既然保存神经网络的输入格式了,那也把输出格式也给保存进去呗,target_vars既然没要求"叫外号",那就直接把变量名out给放进去就可以了。
executor不解释了,就是框架执行器
9、开始考试(预测)
我们要新建一个全新的Python文件,因为要想把训练和预测写在一起,还需要特殊的写法,至于该怎么写会在下一节说明。
这里需要你新建一个全新的Python文件
想必你也非常想知道自己训练的模型效果了,那就直接贴上代码吧!
import paddle.fluid as fluid
import numpy as np
# 定义测试数据
test_data = [[100], [567], [20]]
# 初始化预测环境
exe = fluid.Executor(place=fluid.CPUPlace())
# 读取模型
Program, feed_target_names, fetch_targets = fluid.io.load_inference_model(dirname="infer.model",
executor=exe)
# 开始预测
for x_ in test_data:
x_ = np.array(x_).reshape(1, 1).astype("float32")
out = exe.run(program=Program, feed={feed_target_names[0]: x_}, fetch_list=fetch_targets)
print(out[0])
这里除了Program, feed_target_names, fetch_targets其它的相信你应该都已经比较熟悉了。
Program是用做预测的程序,当然你也可以翻译为是项目。只需要把它放入exe.run中,执行器就知道这是一个预测项目了。
feed_target_names就是刚刚定义的神经网络输入入口x,因为刚刚保存时候是["x"],是个列表(list)形式,所以这里就使用索引( feed_target_names[0]: x_)来获得刚才的输入入口x。fetch_targets`不解释了,就是神经网络的输出,也是你在保存预测模型时候定义的。
完成了这些,那就开始考试吧!
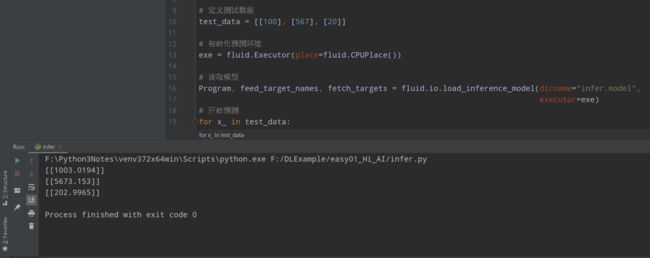
可以看到100对应的结果是1003.0194,与题型y = 10x + 3的结果还是非常吻合的,模型效果可以!
至此,你已经完成了你的第一个深度学习程序。
如果你有什么建议也可以在评论区留言,遇到问题还可以在这篇文章的顶部获取官方交流2群的信息。
当然,如果想一次性获取全部代码,可以点击下方GitHub链接,希望看到你的Star哟~
https://github.com/GT-ZhangAcer/DLExample/tree/master/easy01_Hi_AI
文章不定期更新,欢迎关注!
点击进入PaddlePaddle入门专题页面,获取完整教程信息
点击进入往期PaddlePaddle文章、极简入门专题页面