项目简介
本文将介绍一个笔者自己的项目:自制简单的诗歌搜索系统。该系统主要的实现功能如下:指定一个关键词,检索出包含这个关键词的诗歌,比如关键词为“白云”,则检索出的诗歌可以为王维的《送别》,内容为“下马饮君酒,问君何所之?君言不得意,归卧南山陲。但去莫复问,白云无尽时。”
该项目使用的Python模块为:
- requests
- BeautifulSoup
- pymongo
- tornado
其中,requests模块和BeautifulSoup模块用来制作爬虫,爬取网上的诗歌。pymongo模块用来将爬取的诗歌写入到MongoDB数据库。tornado模块用于网页端展示。
该项目主要分以下三步实现:
- 收集数据:使用爬虫,爬取网上的诗歌作为项目的数据集;
- 存入数据库:将爬取到的诗歌写入到MongoDB数据库;
- 网页展示:利用tornado框架实现诗歌搜索功能。
该项目的结构如下:
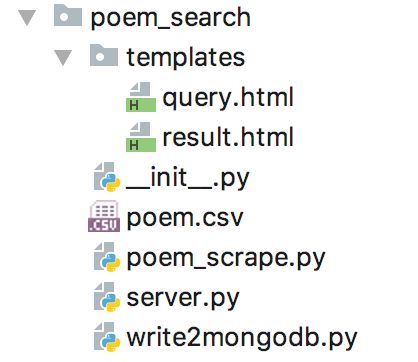
数据收集
首先,我们利用Python爬虫来爬取诗歌,存为CSV文件poem.csv。爬取的网址为:https://www.gushiwen.org 。由于仅是展示该项目的思路,因此,只爬取了该页面中的唐诗三百首、古诗三百、宋词三百、宋词精选,一共大约1100多首诗歌。
实现该爬虫的代码文件为poem_scrape.py,代码如下:
# -*- coding: utf-8 -*-
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 爬取的诗歌网址
urls = ['https://www.gushiwen.org/gushi/tangshi.aspx',
'https://www.gushiwen.org/gushi/sanbai.aspx',
'https://www.gushiwen.org/gushi/songsan.aspx',
'https://www.gushiwen.org/gushi/songci.aspx'
]
poem_links = []
# 诗歌的网址
for url in urls:
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
content = soup.find_all('div', class_="sons")[0]
links = content.find_all('a')
for link in links:
poem_links.append(link['href'])
# print(poem_links)
# print(len(poem_links))
content_list = []
title_list = []
dynasty_list = []
poet_list = []
# 爬取诗歌页面
def get_poem(url):
#url = 'https://so.gushiwen.org/shiwenv_45c396367f59.aspx'
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
# 诗歌内容
poem = soup.find('div', class_='contson').text.strip()
poem = poem.replace(' ', '')
poem = re.sub(re.compile(r"\([\s\S]*?\)"), '', poem)
poem = re.sub(re.compile(r"([\s\S]*?)"), '', poem)
poem = re.sub(re.compile(r"。\([\s\S]*?)"), '', poem)
poem = poem.replace('!', '!').replace('?', '?').replace('\n', '')
content = poem
if content:
content_list.append(content)
else:
content_list.append('')
# 诗歌朝代,诗人
dynasty_poet = soup.find('p', class_='source').text
if ':' in dynasty_poet:
dynasty, poet = dynasty_poet.split(':')
else:
dynasty, poet = '', ''
dynasty_list.append(dynasty)
poet_list.append(poet)
# 诗歌标题
title = soup.find('h1').text
if title:
title_list.append(title)
else:
title_list.append('')
# 爬取诗歌
for url in poem_links:
get_poem(url)
# 写入至csv文件
df = pd.DataFrame({'title': title_list,
'dynasty': dynasty_list,
'poet': poet_list,
'content': content_list
})
print(df.head())
df.to_csv('./poem.csv', index=False)
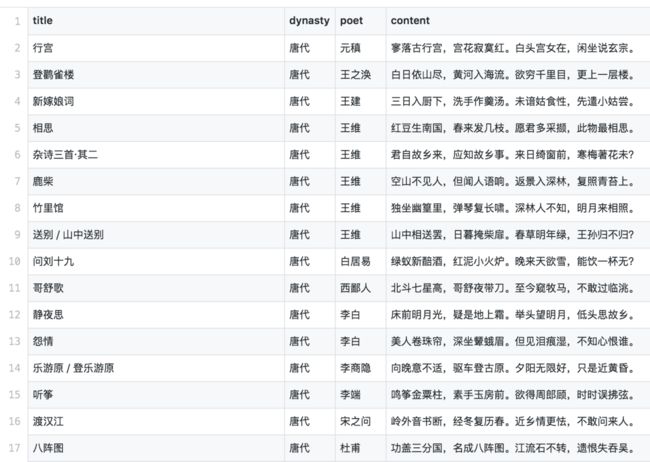
储存的poem.csv的前几行如下:
数据库
数据收集完毕后,我们需要将这些数据出访到数据库中,便于后续的调用,在这里选择MongoDB。利用文件write2mongodb.py文件可以将刚才爬取到的诗歌存放至MongoDB数据库中,完整的代码如下:
import pandas as pd
from pymongo import MongoClient
# 连接MongoDB
conn = MongoClient('mongodb://localhost:27017/')
db = conn["test"]
# 插入诗歌
df = pd.read_csv('poem.csv')
columns = ['title', 'dynasty', 'poet', 'content']
for i in range(df.shape[0]):
print(i)
row = df.iloc[i, :]
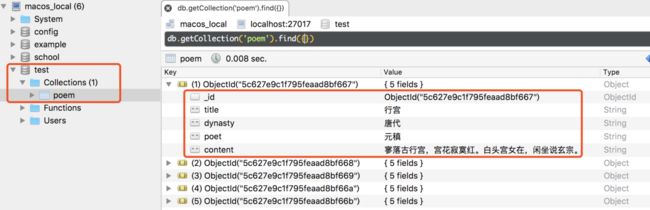
db.poem.insert(dict(zip(columns, row[columns])))不到一分钟,我们可以看到MongoDB中的内容如下:
前端展示
准备好数据集后,我们需要可视化地展示诗歌检索功能,我们选择tornado这个框架来实现。诗歌检索功能为:指定一个关键词,检索出包含这个关键词的诗歌。关键词由用户输入,提交HTTP请求,在后台实现诗歌检索功能,然后在前端页面展示出来。
实现的server.py的代码如下:
# -*- coding: utf-8 -*-
import random
import os.path
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
from pymongo import MongoClient
# 连接MongoDB
conn = MongoClient('mongodb://localhost:27017/')
coll = conn["test"].poem
#定义端口为8000
define("port", default=8000, help="run on the given port", type=int)
# GET请求
class QueryHandler(tornado.web.RequestHandler):
# get函数
def get(self):
self.render('query.html')
# POST请求
# POST请求参数:query_string
class ResultHandler(tornado.web.RequestHandler):
# post函数
def post(self):
query = self.get_argument('query_string')
res = list(coll.find({'content': {'$regex': query}}))
if len(res) > 0:
result = random.sample(res, 1)[0]
del result["_id"]
title = result['title']
dynasty = result['dynasty']
poet = result['poet']
content = result['content']
else:
title = ''
dynasty = ''
poet = ''
content = ''
self.render('result.html', query=query, title=title, dynasty=dynasty, poet=poet, content=content)
# 主函数
def main():
tornado.options.parse_command_line()
# 定义app
app = tornado.web.Application(
handlers=[(r'/query', QueryHandler), (r'/result', ResultHandler)], #网页路径控制
template_path=os.path.join(os.path.dirname(__file__), "templates") # 模板路径
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
main()其中,query路径对应的网页query.html的代码如下:
Poem Query
请输入查询
result路径对应的网页result.html如下:
Result
查询词:{{query}}
标题:{{title}}
朝代:{{dynasty}}
诗人:{{poet}}
内容:{{content}}
使用示例
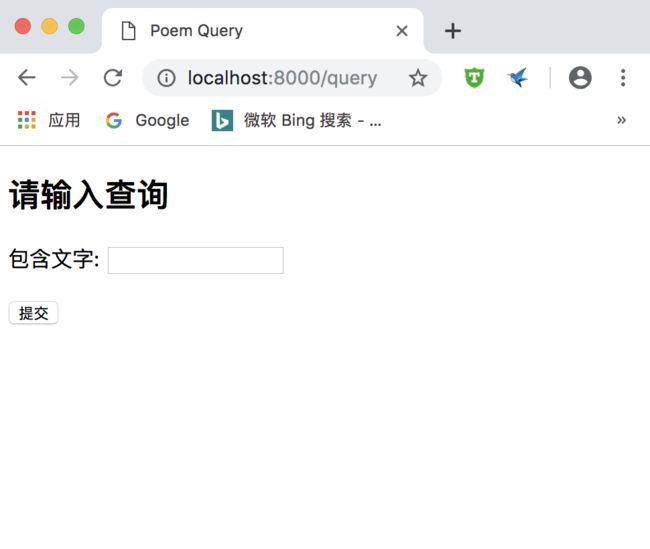
运行server.py, 在浏览器中输入网址:http://localhost:8000/query ,界面如下:
在其中输入搜索关键词,比如“白云”,则会显示一条随机的结果,如下:
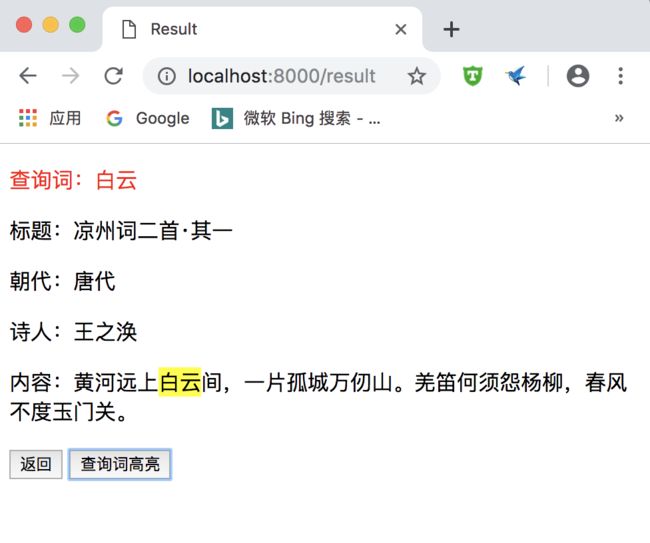
点击“查询词高亮”,则查询词部分会高亮显示。
总结
本项目仅为展示诗歌检索的一种实现思路,仍有许多功能还待完善,后续将进一步补充实现。本项目的github地址为:https://github.com/percent4/Poem-Search 。
注意:本人现已开通微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注哦~~