简介
curator 是一个官方的,可以管理elasticsearch索引的工具,可以实现创建,删除,段合并等等操作。详见官方文档
功能
curator允许对索引和快照执行许多不同的操作,包括:
- 从别名添加或删除索引(或两者!)
- 更改分片路由分配
- 关闭索引
- 创建索引
- 删除索引
- 删除快照
- 打开被关闭的索引
- 对索引执行forcemerge段合并操作
- reindex索引,包括来自远程集群的索引
- 更改索引的每个分片的副本数
- rollover索引
- 生成索引的快照(备份)
- 还原快照
版本
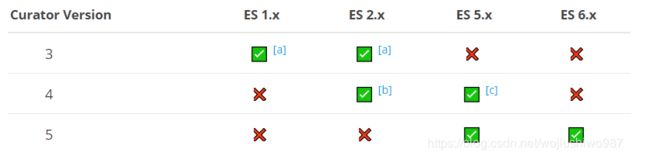
安装
有多种安装方法,本人采用yun安装,官网下载安装包:https://www.elastic.co/guide/en/elasticsearch/client/curator/current/yum-repository.html
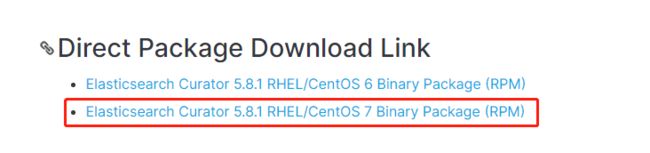
执行以下命令进行安装:
rpm -ivh elasticsearch-curator-5.8.1-1.x86_64.rpm

默认安装路径为:/opt/elasticsearch-curator,且不能移动到其它位置,命令会识别不了。
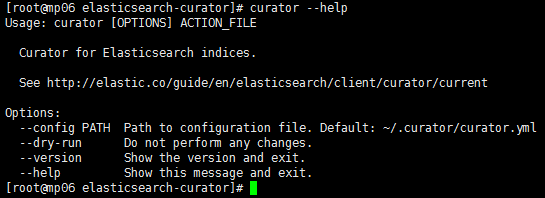
执行以下命令验证是否安装成功:
curator --help
创建配置文件
curator运行需两个配置文件config.yml(用于连接ES集群配置)、action.yml(用于配置要执行的操作),文件名称可以随意命名。
config.yml样例如下: 配置说明参考官网说明:config.yml
# Rmember, leave a key empty if there is no value. None will be a string, # not a Python "NoneType" client: hosts: ["10.0.101.100", "10.0.101.101", "10.0.101.102"] # es集群地址 port: 9200 # es端口 url_prefix: use_ssl: False certificate: client_cert: client_key: ssl_no_validate: False http_auth: timeout: 30 master_only: False logging: loglevel: INFO logfile: /opt/elasticsearch-curator/logs/run.log # 日志路径 logformat: default blacklist: ['elasticsearch', 'urllib3']
action.yml样例如下: 配置说明参考官网说明:action.yml
# Remember, leave a key empty if there is no value. None will be a string, # not a Python "NoneType" # # Also remember that all examples have 'disable_action' set to True. If you # want to use this action as a template, be sure to set this to False after # copying it. actions: 1: action: delete_indices # 这里执行操作类型为删除索引 description: >- Delete metric indices older than 3 days (based on index name), for zou_data-2018-05-01 prefixed indices. Ignore the error if the filter does not result in an actionable list of indices (ignore_empty_list) and exit cleanly. options: ignore_empty_list: True filters: - filtertype: pattern kind: prefix value: business-logs- # 这里是指匹配前缀为 “order_” 的索引,还可以支持正则匹配等,详见官方文档 - filtertype: age # 这里匹配时间 source: name # 这里根据索引name来匹配,还可以根据字段等,详见官方文档 direction: older timestring: '%Y-%m-%d' # 用于匹配和提取索引或快照名称中的时间戳 unit: days # 这里定义的是days,还有weeks,months等,总时间为unit * unit_count unit_count: 3
以上命令删除了3天前,以business-logs-*开头的索引。
执行多个任务
注意:actions: 后面的,依次类推:
2:执行操作 3:执行操作 4:执行操作 N:执行操作
运行curator
单次运行:
curator --config config.yml action.yml
实际生成环境中我们添加一个linux的cron定时任务:
crontab -e
加上如下命令(每天0时运行一次):
0 0 */1 * * curator --config /opt/elasticsearch-curator/config.yml /opt/elasticsearch-curator/action.yml

运行curator_cli
用法举例:curator_cli 关闭全部一天前创建的索引名称为logs_*开头的索引。
curator_cli --host 192.168.1.2 --port 9200 close --filter_list '[{"filtertype":"age","source":"creation_date","direction":"older","unit":"days","unit_count":1},{"filtertype":"pattern","kind":"prefix","value":"logs_"}]'
总结
curator适用于基于时间或者template其他方式创建的索引,不适合单一索引存储N久历史数据的操作的场景。
例如以下场景:
elasticsearch要想实现只保留固定时间的数据,这里以7天为例,要想每个索引的数据都只保留最近7天的数据,大于7天的则删除,有两种方法:
1. 看你的索引是怎么样的,如果你的索引名称中有时间,比如logstash-2019-01-02 这样,就是每天都会生成一个新的索引,这样的话可以使用官方的Curator 工具
2. 如果你的索引中不带时间,比如,如果是根据应用或者服务名来命名的,那么注意,Curator是无法实现删除索中的某一段数据的!! 这里需要特别注意,网上很多说可以实现的,那是因为他们的索引如上面1 所说,是根据时间日期来生成的。
但实际上,很多索引都不是这样的,按正常的思维,更容易用服务名或应用名作为索引,以此来区分日志所属应用,方便日志的分析对应指定的应用。这种时候需要使用elasticsearch的api:delete_by_query来进行删除指定数据。
具体实现请参考:https://blog.csdn.net/weixin_41004350/article/details/85620572
https://juejin.im/post/58e5de06ac502e006c254145
参考:
https://blog.csdn.net/laoyang360/article/details/85882832