一手资料,完全来自官网,直接参考英文过来的,并加了一些自己的理解,希望能让看官君了解点什么,足矣。
环境:Flink1.9.1
难度:新手--战士--老兵--大师
目标:
- 理解Flink的计算模型
- 认识各重要组件
说明:
本篇作为前两篇的补充内容,算是理论篇
步骤:
01-Flink编程模型
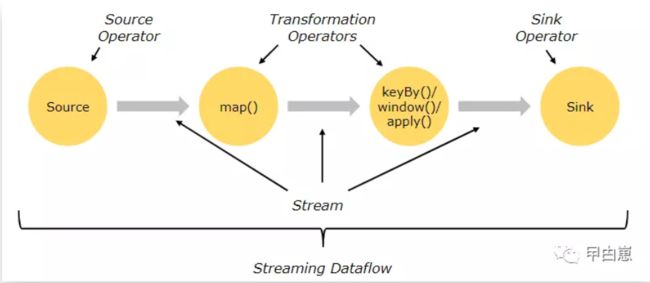
Flink的流计算整体来看都是按照Source -> Transformation -> Sink三步走,即获取流源 -> 进行转换 -> 汇聚(Sink),但“转换 (Transformation)”可能有多个步骤,比如依次进行 KeyBy、Reduce 和 Map 操作等,如下为示意图:
02-并行数据流
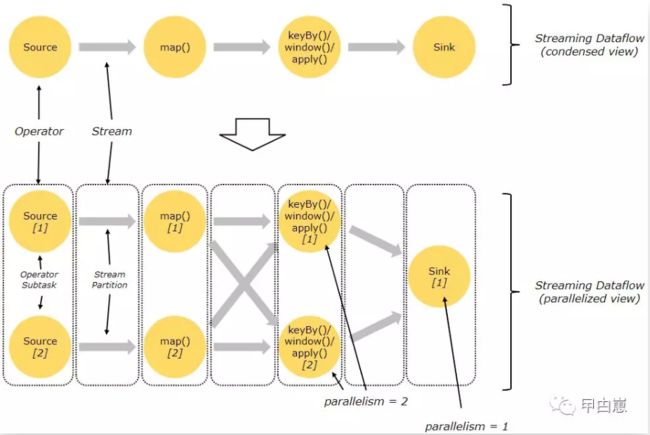
Flink自诞生起即带有并行与分布式特征,数据流在执行过程中,会被“分区(Partition)”,一般为按照Key进行逻辑分区,也可进行物理分区。每个算子(Operator)都有一到多个”算子子任务”,这些算子子任务彼此独立,在不同的线程中执行,分布式环境下,可能在不同的服务器或容器(比如Docker)上执行。
每个算子子任务个数即为该算子的并行度(parallelism),可整体设置执行环境并行度从而作用于该环境下的所有算子,也可单独的算子设置,这样同一程序中不同的算子可以有不同的并行度。具体使用见我前面的文章篇二。并行度通常为生产型算子所具备,如下图Map的并行度为2,Sink的为1:
03-算子间数据分发
“一对一(one-to-one)”:我们再看上图,算子 Source 和 map() 之间就会保留元素的分区和顺序,即map()子任务[1]接收的元素和Source子任务[1]产生的元素顺序一致。
“再分配(Redistributing )”:上图中的 map() 和 keyBy/window 之间,还有keyBy/window 和 Sink 之间,都会改变元素的分区。算子如 keyBy() / broadcast() / rebalance() 都可改变元素分区,结果就是只有上下游的算子子任务中相同分区内的元素顺序不变,比如上图中 map()的 subtask[1] 对接 keyBy/window 的 subtask[2],但是到了Sink算子,汇聚后的顺序是不确定的,因为与各算子子任务的元素到达时间相关,比如上图的的两个算子子任务到Sink算子。
04-状态计算
状态概念见我前篇java steam中有解释,可对比,所谓有状态,就是程序需要记住上下文信息和一些中间计算结果,比如统计流元素个数,就必须有状态。Flink中的状态计算也非常普遍,有的是每次只关注于一个事件Event (事件即域模型的状态改变的声明,可以在流或批处理应用中做为输入/输出。是特殊类型的流元素。),比如event parser。有的是需要存储多个事件的信息,比如Window算子。
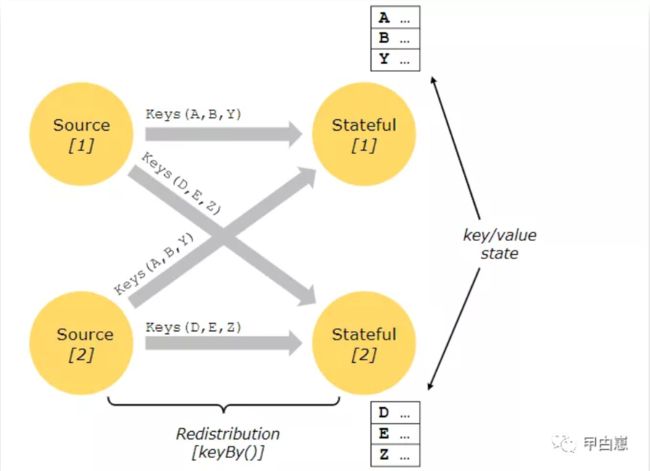
状态可视为通过内嵌的key/value存储来维护。状态会被分区并严格地分发给有状态计算的流,因此状态只能被已key分区( keyBy()之后)的流访问,并且仅限于与当前事件的key有关联的value。流之间keys和状态的协调能保证所有的状态更新都是本地的,从而确保不出现事务型开销。这样,Flink中状态分发和分区调整都能透明的进行。如下图中Source[1]和Source[2]中的相同的keys[DEZ],会保存在一个状态中,并由Flink自动完成状态的更新和协调。
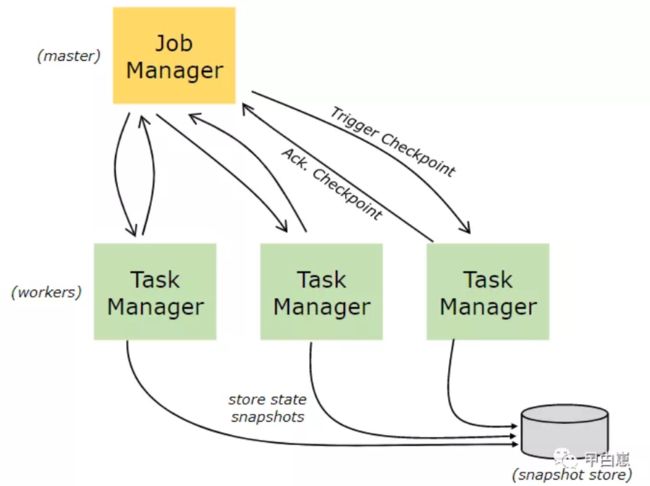
05-检查点(CheckPoint)容错机制
Flink的容错机制通过 stream replay 和 checkpointing组合来实现。检查点就是流中一个特定的包含算子状态的点。流可以从一个检查点恢复,从而确保(exactly-once)语义。检查点时间间隔大小可以调整容错开销和恢复时间两者间的平衡。
06-批处理流:
Flink批处理模式下,即使用DataSet ,每次对一定数量的元素进行批处理,这与流处理基本一样,但有些微区别:
- 批处理模式下不使用检查点(CheckPoint),因为元素个数是确定的,恢复时直接将相关流部分完全恢复,虽然恢复时负载大一些,但通常会使流处理更省资源。
- DataSet API批处理时,使用简化的in-memory/out-of-core数据结构保存状态,而不是key/value存储
- DataSet API批处理独有同步迭代
07-算子链(operator chain)
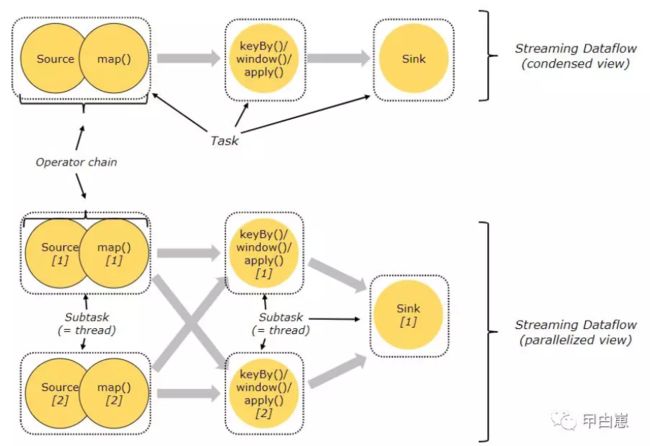
在分布式环境下,算子子任务(subtask)被分成多个任务组(tasks),每个任务组由一个线程执行。Flink进行了运行优化,也即对subtask进行链式操作,链式操作结束之后得到的task,再作为一个调度执行单元,放到一个线程里执行,这样能减少线程间切换和缓存,好处当然是能提高吞吐量和降低延迟。如下图,source/map 两个算子进行了链式连接;keyby/window/apply进行了链式连接,sink单独的一个。从而将有5个任务组,由5个线程并行执行。
08- JobManager和TaskManager
JobManager,也叫主(master)节点,负责协调分布式执行,具体如安排task,协调检查点(checkpoint),协调故障恢复等。集群中至少有一个,高可用架构下会有多个,其中之一为事实上的领导者(leader),其他为候补(standby),leader发送故障时,standby转为leader。
TaskManager ,也叫工人(worker)节点,负责执行数据流的子任务(task),还有缓存和数据交换。必须至少一个TaskManager。JobManager和TaskManager可以在独立服务器、容器或者资源管理框架 YARN or Mesos中运行,然后TaskManager连接JobManager并声明可用,进而被分配具体工作。
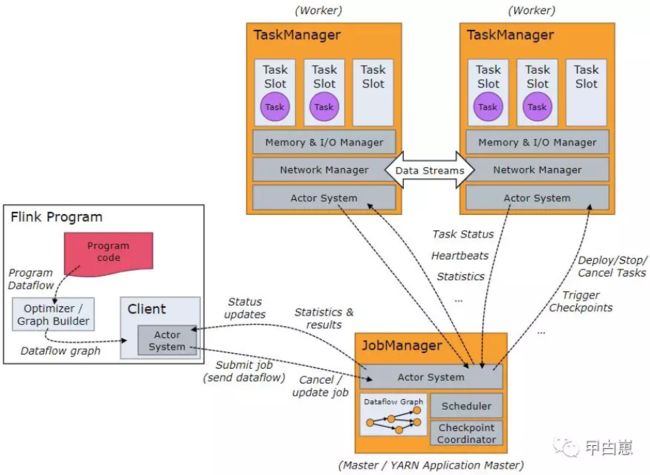
09-任务插槽(task slot)和资源
每个工人(TaskManager)就是一个JVM进程(process),能通过独立线程执行一到多个子任务,子任务的可接收数量就叫任务插槽(task slot),至少得有1个。任务插槽代表TaskManager内的一组固定的资源集,一个TaskManager所有的任务插槽都会均分其控制的内存,比如有3个插槽的TaskManager ,各插槽被分配1/3其管理的内存,这样的好处是为了避免子任务间的资源竞争。但目前这里不涉及CPU资源,仅是内存隔离。
通过调整任务插槽数,可以控制子任务的隔离度。比如TaskManager只有一个任务插槽,即意味着每个任务组运行在独立的JVM(可运行在容器内)中,有多个任务插槽则意味着共享JVM内TCP连接(多路复用方式)和心跳消息,可能还共享数据集和数据结构,从而减少总体负载。
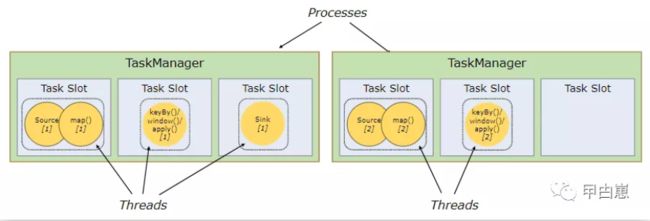
Flink默认对来自于不同Job的子任务都可以共享任务插槽,同一job的就更不用说了。这样一个slot可能执行job的一个完整的管道流(从source到sink),好处有二。
- Flink集群所需的任务插槽数与job中最高的并行度完全一致即可,并不需要去计算并行度各异的任务的总数。(这点的理解很重要,请看官君思考下)
- 优化了资源利用。因为非密集型source/map()的任务组和密集型window 子任务占用同样多的资源。下图中,将前面的图中的例子的并行度由2增加到6,这样在有6个task slot的前提下,资源密集型source/map()任务就会被平均分配到各slot中,从而达到的slot的完全利用。
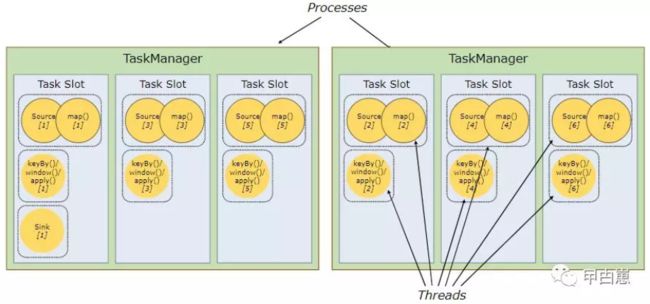
按照经验,CPU核心数作为任务插槽数为最佳实践。超线程场景下,每个slot会运行2到多个硬件线程上下文。
10-状态后端(state backend)
使用key/values存储状态的具体数据结构,依赖于选择的state backend 。一种是在内存hashMap存储,另一种是在 RocksDB中存储。状态后端还将K/V状态的时间点快照保存为检查点(checkpoint)中的部分内容。
11-保存点(savepoint)
使用Data Stream API的程序能从保存点恢复执行(批处理的API无检查点机制),不丢失状态。
保存点实质上就是手动触发的检查点,会将程序快照写入状态后端。Flink的检查点机制会周期性获取woker上的快照并生成检查点。如果为了恢复,只需要一个最新的已完成的检查点,旧的检查点就可以删除了。savepoint和定期的checkpoint 是类似的,区别在于,它们是由用户生成,且当新的checkpoint生成时,它不会自动过期。savepoint 可以通过命令行创建,也可以用REST API取消job时创建,区别总结如下:
- Checkpoint 是增量式的,每次的时间较短,数据量较小,只要在程序里面启用后会自动触发,用户无感知;Checkpoint 是作业 failover 的时候自动使用,不需要用户指定。
- Savepoint 是全量做的,每次的时间较长,数据量较大,需要用户主动去触发。Savepoint 一般用于程序的版本更新(详见文档),Bug 修复,A/B Test 等场景,需要用户指定。
12-window生命周期
Window在属于窗口的第一个元素到来时立即创建,然后在超过最后的时间戳加上设置的延迟后完全移除。Flink只能确定对基于时间特征的window做移除,其他类型的则需视具体环境而定。
每个window都带有一个触发器(Trigger)和一个处理函数。处理函数用于对window中的内容做计算,Trigger则是决定什么条件下函数开始处理。Trigger有每个元素触发的,也有基于注册的时间特征定时器(timer)到达时触发的,还可以自定义。Trigger可以清空window的内容,但不是说删除window元数据,从而window仍然可以接收新元素。
另外,每个window可指定驱逐器(Evictor ),用于在Trigger触发后,也能在函数应用前/后移除一些元素,Evictor 可基于数量,时间戳或Delta算法等。比如只保留指定数量的元素,或移除时间戳超出最大指定值的元素。
此篇完!
总结:Flink内容还有很多,想要看得更全面,直接官网吧。
原创文章,未经本人同意,禁止转载,否则追究法律责任。

往期文章:
- 流式计算(四)-Flink Stream API 篇二
- 流式计算(三)-Flink Stream 篇一
- 流式计算(一)-Java8Stream
- Dubbo学习系列之十六(ELK海量日志分析)