推荐,源码查看工具:
Understand。
重新认识 Binder ,不是三言两语就能讲明白的,学什么基础最重要!所以首先,你要在熟练使用 AIDL 进行跨进程通信的基础上,去熟悉涉及到跨进程通信的类,比如 Parcel, IBinder, Binder 等。
讲到 Parcel 又不得不让人想起 Serialize ,现在终于明白为什么讲Java的人,开头不是直接讲语法,而是喜欢把 Java 的前世今生详细的讲一遍。正文:
一. Serialize 机制
Java Serialize 机制作用是能将数据对象存入字节流中,在需要时重新生成对象。主要应用是利用外部存储设备保存对象状态,以及通过网络传输对象等。
而 Android 系统定位内存受限设备,对性能要求更高,而且系统中采用了 Binder IPC 机制,就需要求性能更出色的对象传输方式。Parcel 定位就是轻量级高效的对象序列化和反序列化机制。
二. Serializable 与 Parcel 的区别
Parcel 是 Android 中不同于 Java Serialize 新的序列化机制,他们的区别如下:
-
Serializable是Java序列化的方式,存取的过程有频繁的IO,性能较差,但是实现简单。 -
Parcelable是Android序列化的方式,采用共享内存的方式实现用户空间和内核空间的交换,性能很好,但是实现方式比较复杂。 -
Serializable可以持久化存储,Parcelable是存储在内存中的,不能持久化存储。
三. Parcel 的使用
向 Parcel 中传入一个 Int 型的数据
parcel.writeInt(int val);
向 Parcel 中传入一个 String 型的数据
parcel.writeString(String val);
这里只以这两种最为常见数据类型的写入作为例子,实际上Parcel所支持的数据类型炒鸡多,如下图:
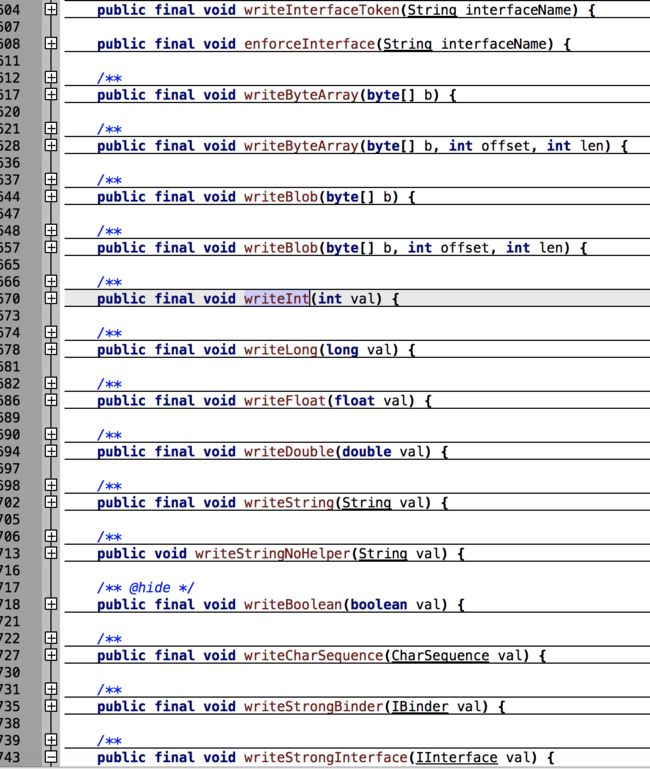
在完成了数据的写入之后,就需要进行数据的序列化:
parcel.marshall();
在经过上一步的处理之后,返回了一个 byte 数组,主要的 IPC 相关的操作主要就是围绕此 byte 数组进行的。同时,由于Parcel 的读写都是一个指针操作的,这一步涉及到 native 的操作,所以,在将数据写入之后,需要将指针手动指向到最初的位置,即如下的操作:
parcel.setDataPosition(0);
到此处,Parcel 的这一步操作还没有收尾,想想前面 Parcel 的获取,我们有理由相信,Parcel 的销毁应该是使用了对应的 recycle() 方法,所以此处有:
parcel.recycle();
将此 Parcel 对象进行释放,完成了 IPC 操作的一半。至于是如何将数据传输过去的,暂不进行展开。此处在 IPC 的另一端的 Parcel 的获取处理。
再进行了 IPC 的操作之后,一般读取出来的就是之前序列化的 byte 数组,所以,首先要进行一个反序列化操作,即如下的操作:
parcel.unmarshall(byte[] data, int offest, int length);
其中的参数分别是这个 byte 数组,以及读取偏移量,以及数组的长度。
此时得到的 Parcel 就是一个正常的 Parcel 对象,这时就可以将之前我们所存入的数据按照顺序进行获取,即:
parcel.readInt();
以及
parcel.readString();
1
读取完毕之后,同样是一个parcel的回收操作:
parcel.recycle();
以上就是 Parcel 的常规使用,或许有些朋友不太知道 Parcel 的使用场景,其实最常见的,在我们编写完 AIDL 的接口之后,IDE 会自动生成一个对应的 .java 文件,这个 java 文件就是实际用来进行 aidl 的通信的,在这个实现里面,数据的传递就是使用的 Parcel,当然还有其他的应用场景,这里只说了一个大家都比较常见的实践。
四. Parcel 源码分析
在进行小伙伴们最喜欢的源码分析之前,咱们先看看在哪里用到了他,还记得创建 aidl 文件时,用编译工具编译之后,在 gen 文件夹下可以得到对应的 .java 类,进到里面去查看,寻找 Parcel 类的影子,代码如下:
/**
* Demonstrates some basic types that you can use as parameters
* and return values in AIDL.
*/// void basicTypes(int anInt, long aLong, boolean aBoolean, float aFloat,
// double aDouble, String aString);
@Override
public double doCalculate(double a, double b) throws android.os.RemoteException {
android.os.Parcel _data = android.os.Parcel.obtain();
android.os.Parcel _reply = android.os.Parcel.obtain();
double _result;
try {
_data.writeInterfaceToken(DESCRIPTOR);
_data.writeDouble(a);
_data.writeDouble(b);
mRemote.transact(Stub.TRANSACTION_doCalculate, _data, _reply, 0);
_reply.readException();
_result = _reply.readDouble();
} finally {
_reply.recycle();
_data.recycle();
}
return _result;
}
}
从上面代码块中,可以看到关于 Parcel 的获取:
android.os.Parcel _data = android.os.Parcel.obtain();
//可以理解为
Parcel parcle = Parcel.Obtain();
注意:这个样子的写法,可以猜测Parcel的初始化也是由其对象池进行初始化的。
之后咱们进入到 Parcel 类中,看看在 Java 层( 地址:\frameworks/base/core/java/android/os/Parcel.java )的实现,首先看到是这一段:
/**
* Container for a message (data and object references) that can
* be sent through an IBinder. A Parcel can contain both flattened data
* that will be unflattened on the other side of the IPC (using the various
* methods here for writing specific types, or the general
* {@link Parcelable} interface), and references to live {@link IBinder}
* objects that will result in the other side receiving a proxy IBinder
* connected with the original IBinder in the Parcel.
大体意思,就是:
Parcel就是一个存放读取数据的容器,
android系统中的binder进程间通信(IPC)就使用了Parcel类来进行客户端与服务端数据的交互,
而且AIDL的数据也是通过Parcel来交互的,
同时支持序列化以及跨进程之后进行反序列化,并提供了很多方法帮助开发者完成这些功能。
在Java空间和C++都实现了Parcel,由于它在C/C++中,直接使用了内存来读取数据,因此,它更效率。
找到获取 Parcel 的 Obtain() 方法,如下:
/**
* Retrieve a new Parcel object from the pool.
* 译:从池中检索新的Parcel对象。
*/
public static Parcel obtain() {
final Parcel[] pool = sOwnedPool;
synchronized (pool) {
Parcel p;
for (int i=0; i
从注释也可以看出,Parcle 的初始化,主要是使用一个对象池进行的,这样可以提高性能以及内存消耗。首先要明确的是,源码中定义的池子有两个:
private static final int POOL_SIZE = 6;
private static final Parcel[] sOwnedPool = new Parcel[POOL_SIZE];
private static final Parcel[] sHolderPool = new Parcel[POOL_SIZE];
从 obtain() 方法看出,sOwnedPool 这个池子主要就是用来存储 Parcel 的,Obtain() 方法首先会去检索池子中的 Parcel 对象,若是能取出 Parcel ,那么先将这个这个 Parcel 返回,同时将这个位置置空。若是现在连池子都不存在的话,那么就直接新建一个 Parcel 对象。这里的实现与 Handler 中的 message 采用同样的处理。
了解了获取之后,比较关心的就是如何去新建一个 Parcel 对象,也就是 new 这个过程,那么看看此处中的 Parcel 构造方法:
private Parcel(long nativePtr) {
if (DEBUG_RECYCLE) {
mStack = new RuntimeException();
}
//Log.i(TAG, "Initializing obj=0x" + Integer.toHexString(obj), mStack);
init(nativePtr);
}
可以看到,在此处参数名称被称为:nativePtr,这个大家都比较熟悉了,ptr 嘛,指的就是一个指针,这里又是一个封装,需要继续深入看实现:
private void init(long nativePtr) {
if (nativePtr != 0) {
mNativePtr = nativePtr;
mOwnsNativeParcelObject = false;
} else {
mNativePtr = nativeCreate();
mOwnsNativeParcelObject = true;
}
}
这里首先对参数进行检查,这里因为初始化传入的参数是 0,那么直接执行 nativeCreate(),并且将标志位 mOwnsNativeParcelObject 置为 true ,表示这个 parcel 已经在 native 进行了创建。
此处的 ativeCreate() 是一个 native 方法,其具体实现已经切换到 native 环境了,那么我们此时的分析就要从 jni ( 地址:/frameworks/base/core/jni/android_os_Parcel.cpp)进行了,经过检索,在 jni 的代码中,其实现为以下函数:

static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
{
Parcel* parcel = new Parcel();
return reinterpret_cast(parcel);
}
这是一个 jni 的实现,首先是调用了 native ( 地址:/frameworks/native/libs/binder/Parcel.cpp)的初始化,并且,返回操作这个对象的指针:
Parcel::Parcel()
{
LOG_ALLOC("Parcel %p: constructing", this);
initState();
}
是一个 c++ 的构造方法,关于析构方法,暂时不管,其中的 init 实现为:
void Parcel::initState()
{
LOG_ALLOC("Parcel %p: initState", this);
mError = NO_ERROR;
mData = nullptr;
mDataSize = 0;
mDataCapacity = 0;
mDataPos = 0;
ALOGV("initState Setting data size of %p to %zu", this, mDataSize);
ALOGV("initState Setting data pos of %p to %zu", this, mDataPos);
mObjects = nullptr;
mObjectsSize = 0;
mObjectsCapacity = 0;
mNextObjectHint = 0;
mObjectsSorted = false;
mHasFds = false;
mFdsKnown = true;
mAllowFds = true;
mOwner = nullptr;
mOpenAshmemSize = 0;
// racing multiple init leads only to multiple identical write
if (gMaxFds == 0) {
struct rlimit result;
if (!getrlimit(RLIMIT_NOFILE, &result)) {
gMaxFds = (size_t)result.rlim_cur;
//ALOGI("parcel fd limit set to %zu", gMaxFds);
} else {
ALOGW("Unable to getrlimit: %s", strerror(errno));
gMaxFds = 1024;
}
}
}
找这个方法的时候真是痛苦,一开始用的 UE 查看代码,但是这个没有跳转,后来换了 Understand,简直是一个爽字了得~
可以看出,对 parcel 的初始化,只是在 native 层初始化了一些数据值。
在完成初始化之后,就将这个操作指针给返回。这样就完成了 parcel 的初始化。
初始化完毕之后,就可以进行数据的写入了,首先写入一个 int 型数据,其 java 层实现如下:
/**
* Write an integer value into the parcel at the current dataPosition(),
* growing dataCapacity() if needed.
*/
public final void writeInt(int val) {
nativeWriteInt(mNativePtr, val);
}
可以看出,在这里 java 层就纯粹是一个对于 native 实现的封装了,这时候的分析来到 jni :

static void android_os_Parcel_writeInt(JNIEnv* env, jclass clazz, jlong nativePtr, jint val) {
Parcel* parcel = reinterpret_cast(nativePtr);
if (parcel != NULL) {
const status_t err = parcel->writeInt32(val);
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
在这里我们要特别注意两个参数,一个是之前传上去的指针以及需要保存的 int 数据,这两个值分别是:
jlong nativePtr, jint val
首先是根据这个指针,这里说一下,指针实际上就是一个整型地址值,所以这里使用强转将 int 值转化为 Parcel 类型的指针是可行的,然后使用这个指针来操作 native 的 Parcel 对象,即:
const status_t err = parcel->writeInt32(val);
这里注意到我们是写入了一个 32 位的 int 值,这个点一定要注意, 32 位, 4 个字节。
深入进去看看实现:
status_t Parcel::writeInt32(int32_t val)
{
return writeAligned(val);
}
可以看出,这里实际上调用了:writeAligned(val) 。 来进行数据的写入,这里理解下 align 的意思,实际上是一个对齐写入,怎么个对齐法,看看:
template
status_t Parcel::writeAligned(T val) {
COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(val)) <= mDataCapacity) {
restart_write:
*reinterpret_cast(mData+mDataPos) = val;
return finishWrite(sizeof(val));
}
status_t err = growData(sizeof(val));
if (err == NO_ERROR) goto restart_write;
return err;
}
在这个方法中首先是一个断言检查,然后对输入的参数取 size 值,再加上之前已经移动的位置,判断是否超过了该 Pacel 所定义的能力值 mDataCapacity 。
若是超过了能力值的话,那么直接将能力值进行扩大,扩大的值是 val 值的大小,比如,int 值是 32bit ,那么就增加 4 个字节,返回的结果是状态值,若是没有出错的话,就利用 goto 语句执行,这里的 goto 的语句只要是一个指针的操作,将指针移动到端点,然后写入 val 的 size 值。这里可以看出这个函数的意义,因为无论是否超过能力值它都会写入 T 类型值的 size 值。
到这里,Parcel 就写入了一个 Int 型的值。
同样的思路,那么其他数据类型呢?
让我们回忆一下基本数据类型的取值范围:
数据类型
bit
Byte
boolean
8bit
1字节
char
16bit
2字节
int
32bit
4字节
long
64bit
8字节
float
32bit
4字节
double
64bit
8字节
如果大家对 C 语言熟悉的话,C 语言中结构体的内存对齐和 Parcel 采用的内存存放机制一样,即读取最小字节为 32bit,也即 4 个字节。高于 4 个字节的,以实际数据类型进行存放,但得为 4 byte 的倍数。基本公式如下:
实际存放字节:
判别一: 32bit (<=32bit) 例如:boolean,char,int
判别二: 实际占用字节(>32bit) 例如:long,float,String,数组等
当我们使用 readXXX() 方法时,读取方法也如上述:
实际读取字节:
判别一: 32bit (<=32bit) 例如:boolean,char,int
判别二: 实际字节大小(>32bit) 例如:long,float,String,数值等
由上可以知道,当我们写入/读取一个数据时,偏移量至少为 4byte(32bit),于是,偏移量的公式如下:
f(x)= 4x (x=0,1,…n)
事实上,我们可以显示的通过 setDataPostion(int postion) 来直接操作我们欲读取数据时的偏移量。毫无疑问,你可以设置任何偏移量,但所读取的值是类型可能有误。因此显示设置偏移量读取值的时候,需要小心。
另外一个注意点就是我们在 writeXXX() 和 readXXX() 时,导致的偏移量是共用的,例如,我们在 writeInt(23) 后,此时的 datapostion=4,如果我们想读取 5,简单的通过 readInt() 是不行的,只能得到 0。这时我们只能通过 setDataPosition(0) 设置为起始偏移量,从起始位置读取四个字节,即 23 。因此,在读取某个值时,可能需要使用 setDataPostion(int postion) 使偏移量装换到我们的值处。
巧用 setDataPosition() 方法,当我们的 Parcel 对象中只存在某一类型时,我们就可以通过这个方法来快速的读取所有值。具体方法如下:
/**
* 前提条件,Parcel存在多个类型相同的对象,本例子以10个float对象说明:
*/
public void readSameType() {
Parcel parcel =Parcel.obtain() ;
for (int i = 0; i < 10; i++) {
parcel.writeDouble(i);
Log.i(TAG, "write double ----> " + getParcelInfo());
}
//方法一 ,显示设置偏移量
int i = 0;
int datasize = parcel.dataSize();
while (i < datasize) {
parcel.setDataPosition(i);
double fvalue = parcel.readDouble();
Log.i(TAG, " read double is=" + fvalue + ", --->" + getParcelInfo());
i += 8; // double占用字节为 8byte
}
// 方法二,由于对象的类型一致,我们可以直接利用readXXX()读取值会产生偏移量
// parcel.setDataPosition(0) ; //
// while(parcel.dataPosition()" + getParcelInfo());
// }
}
由于可能存在读取值的偏差,一个默认的取值规范为:
1、 读取复杂对象时: 对象匹配时,返回当前偏移位置的该对象;
对象不匹配时,返回null对象 ;
2、 读取简单对象时: 对象匹配时,返回当前偏移位置的该对象 ;
对象不匹配时,返回0;
下面,给出一张浅显的 Parcel 的存放空间图,希望大家在理解的同时,更能体味其中滋味。
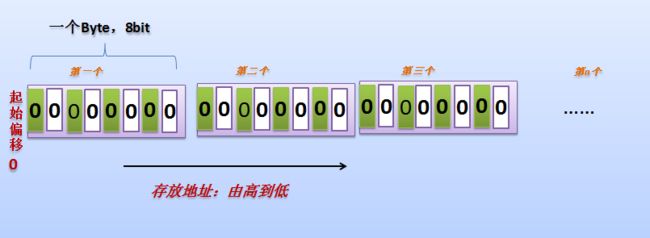
另外,在分析过程中,我对 Android 的 JNI 调用进行一番探索,总之一句话就是说 JVM 环境切换到 Native 环境之中后,Java 如何通过 Java 层声明的 native 方法来查找到对应的 JNI 方法的?因为我对 JVM 的实现这一部分没有太多了解,所以只能从 Android 源码中代码层面上来分析,至少在 Android 中。
在切换到 native 环境之后,实际上,这两种函数的映射是由一个多重数组来进行管理的,具体如下:
static const JNINativeMethod gParcelMethods[] = {
// @CriticalNative
{"nativeDataSize", "(J)I", (void*)android_os_Parcel_dataSize},
// @CriticalNative
{"nativeDataAvail", "(J)I", (void*)android_os_Parcel_dataAvail},
// @CriticalNative
{"nativeDataPosition", "(J)I", (void*)android_os_Parcel_dataPosition},
// @CriticalNative
{"nativeDataCapacity", "(J)I", (void*)android_os_Parcel_dataCapacity},
// @FastNative
{"nativeSetDataSize", "(JI)J", (void*)android_os_Parcel_setDataSize},
// @CriticalNative
{"nativeSetDataPosition", "(JI)V", (void*)android_os_Parcel_setDataPosition},
// @FastNative
{"nativeSetDataCapacity", "(JI)V", (void*)android_os_Parcel_setDataCapacity},
// @CriticalNative
{"nativePushAllowFds", "(JZ)Z", (void*)android_os_Parcel_pushAllowFds},
// @CriticalNative
{"nativeRestoreAllowFds", "(JZ)V", (void*)android_os_Parcel_restoreAllowFds},
{"nativeWriteByteArray", "(J[BII)V", (void*)android_os_Parcel_writeByteArray},
{"nativeWriteBlob", "(J[BII)V", (void*)android_os_Parcel_writeBlob},
// @FastNative
{"nativeWriteInt", "(JI)V", (void*)android_os_Parcel_writeInt},
......
(方法好多,我就不一一列出来了)
这样通过映射就可以将函数给进行对应了,但是还有一点,这个东西是何时,以及何处进行调用的,这个展开说又是一个漫长的故事了。
这是我第一篇象征性总结关于 JNI 以及 Native 层面的知识,把需要的 Android 源码下载到本地,借助别人的“轮子”和自己的一点点见解,虽然是这样,但也是收获颇多,从 Java 层面到 JNI 再到 Native ,完整的跟着走了一圈,那种感觉就像打开了一个异世界的大门,那么好玩,还有的是,理解了大学课程的意义,比如计算机组成原理之类的。
参考链接:
大部分参考:Android Parcel对象详解
小部分参考:Android中Parcel的分析以及使用