1.理论分析
TCP是面向连接的传输层协议,所谓面向连接就是在真正的数据传输开始前要完成连接建立的过程,否则不会进入真正的数据传输阶段。
TCP的连接建立过程通常被称为三次握手(three-way handshake),过程如下:请求端(通常称为客户)发送一个SYN段指明客户打算连接的服务器的端口,以及初始序号(ISN)。这个SYN段为报文段1。 服务器发回包含服务器的初始序号的SYN报文段(报文段2)作为应答。同时,将确认序号设置为客户的ISN加1以对客户的SYN报文段进行确认。一个SYN将占用一个序号。 客户必须将确认序号设置为服务器的ISN加1以对服务器的SYN报文段进行确认(报文段3)。 这三个报文段完成连接的建立。
发送第一个SYN的一端将执行主动打开(active open)。接收这个SYN并发回下一个SYN的另一端执行被动打开(passive open)
当一端为建立连接而发送它的SYN时,它为连接选择一个初始序号。ISN随时间而变化,因此每个连接都将具有不同的ISN。RFC 793 [Postel1981c]指出ISN可看作是一个32比特的计数器,每4 ms加1。这样选择序号的目的在于防止在网络中被延迟的分组在以后又被传送,而导致某个连接的一方对它作错误的解释。
如何进行序号选择? 在4.4 BSD(和多数的伯克利的实现版)中,系统初始化时初始的发送序号被初始化为1。这个变量每0.5秒增加64000,并每隔9.5小时又回到0。另外,每次建立一个连接后,这个变量将增加64000。

struct socket { socket_state state; short type; unsigned long flags; struct socket_wq *wq; struct file *file; struct sock *sk; const struct proto_ops *ops; };
在socket中Proto_ops结构体定义如下:
struct proto_ops { int family; struct module *owner; int (*release) (struct socket *sock); int (*bind) (struct socket *sock, struct sockaddr *myaddr, int sockaddr_len); int (*connect) (struct socket *sock, struct sockaddr *vaddr, int sockaddr_len, int flags); int (*socketpair)(struct socket *sock1, struct socket *sock2); int (*accept) (struct socket *sock, struct socket *newsock, int flags, bool kern); int (*getname) (struct socket *sock, struct sockaddr *addr, int peer); __poll_t (*poll) (struct file *file, struct socket *sock, struct poll_table_struct *wait); int (*ioctl) (struct socket *sock, unsigned int cmd, unsigned long arg); #ifdef CONFIG_COMPAT int (*compat_ioctl) (struct socket *sock, unsigned int cmd, unsigned long arg); #endif int (*listen) (struct socket *sock, int len); int (*shutdown) (struct socket *sock, int flags); int (*setsockopt)(struct socket *sock, int level, int optname, char __user *optval, unsigned int optlen); int (*getsockopt)(struct socket *sock, int level, int optname, char __user *optval, int __user *optlen); #ifdef CONFIG_COMPAT int (*compat_setsockopt)(struct socket *sock, int level, int optname, char __user *optval, unsigned int optlen); int (*compat_getsockopt)(struct socket *sock, int level, int optname, char __user *optval, int __user *optlen); #endif int (*sendmsg) (struct socket *sock, struct msghdr *m, size_t total_len); /* Notes for implementing recvmsg: * =============================== * msg->msg_namelen should get updated by the recvmsg handlers * iff msg_name != NULL. It is by default 0 to prevent * returning uninitialized memory to user space. The recvfrom * handlers can assume that msg.msg_name is either NULL or has * a minimum size of sizeof(struct sockaddr_storage). */ int (*recvmsg) (struct socket *sock, struct msghdr *m, size_t total_len, int flags); int (*mmap) (struct file *file, struct socket *sock, struct vm_area_struct * vma); ssize_t (*sendpage) (struct socket *sock, struct page *page, int offset, size_t size, int flags); ssize_t (*splice_read)(struct socket *sock, loff_t *ppos, struct pipe_inode_info *pipe, size_t len, unsigned int flags); int (*set_peek_off)(struct sock *sk, int val); int (*peek_len)(struct socket *sock); /* The following functions are called internally by kernel with * sock lock already held. */ int (*read_sock)(struct sock *sk, read_descriptor_t *desc, sk_read_actor_t recv_actor); int (*sendpage_locked)(struct sock *sk, struct page *page, int offset, size_t size, int flags); int (*sendmsg_locked)(struct sock *sk, struct msghdr *msg, size_t size); int (*set_rcvlowat)(struct sock *sk, int val); };
在上次是实验中,已经追踪到bind函数之后,在进行安全检查之后,调用了ops结构体中的listen指针指向的方法
在经过单步调试之后,
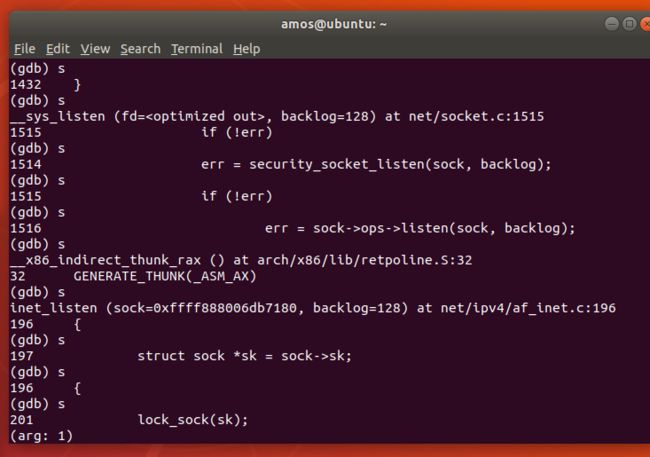
ops结构体中间的各个函数指针指向了net/ipv4/af_inet文件,我们接下来去找找这个文件中的各个方法
对该文件中各个方法打上断点

按照断点运行,可得过程如下:

上图中断点运行步骤展示了服务器端的函数执行顺序如下:
Inet_create->inet_bind ->inet_listen ->accept
因此TCP初始化过程大部分都是在create函数中完成的:
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern) { struct sock *sk; struct inet_protosw *answer; struct inet_sock *inet; struct proto *answer_prot; unsigned char answer_flags; int try_loading_module = 0; int err; if (protocol < 0 || protocol >= IPPROTO_MAX) return -EINVAL; sock->state = SS_UNCONNECTED; /* Look for the requested type/protocol pair. */ lookup_protocol: err = -ESOCKTNOSUPPORT; rcu_read_lock(); list_for_each_entry_rcu(answer, &inetsw[sock->type], list) { err = 0; /* Check the non-wild match. */ if (protocol == answer->protocol) { if (protocol != IPPROTO_IP) break; } else { /* Check for the two wild cases. */ if (IPPROTO_IP == protocol) { protocol = answer->protocol; break; } if (IPPROTO_IP == answer->protocol) break; } err = -EPROTONOSUPPORT; } if (unlikely(err)) { if (try_loading_module < 2) { rcu_read_unlock(); /* * Be more specific, e.g. net-pf-2-proto-132-type-1 * (net-pf-PF_INET-proto-IPPROTO_SCTP-type-SOCK_STREAM) */ if (++try_loading_module == 1) request_module("net-pf-%d-proto-%d-type-%d", PF_INET, protocol, sock->type); /* * Fall back to generic, e.g. net-pf-2-proto-132 * (net-pf-PF_INET-proto-IPPROTO_SCTP) */ else request_module("net-pf-%d-proto-%d", PF_INET, protocol); goto lookup_protocol; } else goto out_rcu_unlock; } err = -EPERM; if (sock->type == SOCK_RAW && !kern && !ns_capable(net->user_ns, CAP_NET_RAW)) goto out_rcu_unlock; sock->ops = answer->ops; answer_prot = answer->prot; answer_flags = answer->flags; rcu_read_unlock(); WARN_ON(!answer_prot->slab); err = -ENOBUFS; sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern); if (!sk) goto out; err = 0; if (INET_PROTOSW_REUSE & answer_flags) sk->sk_reuse = SK_CAN_REUSE; inet = inet_sk(sk); inet->is_icsk = (INET_PROTOSW_ICSK & answer_flags) != 0; inet->nodefrag = 0; if (SOCK_RAW == sock->type) { inet->inet_num = protocol; if (IPPROTO_RAW == protocol) inet->hdrincl = 1; } if (net->ipv4.sysctl_ip_no_pmtu_disc) inet->pmtudisc = IP_PMTUDISC_DONT; else inet->pmtudisc = IP_PMTUDISC_WANT; inet->inet_id = 0; sock_init_data(sock, sk); sk->sk_destruct = inet_sock_destruct; sk->sk_protocol = protocol; sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv; inet->uc_ttl = -1; inet->mc_loop = 1; inet->mc_ttl = 1; inet->mc_all = 1; inet->mc_index = 0; inet->mc_list = NULL; inet->rcv_tos = 0; sk_refcnt_debug_inc(sk); if (inet->inet_num) { /* It assumes that any protocol which allows * the user to assign a number at socket * creation time automatically * shares. */ inet->inet_sport = htons(inet->inet_num); /* Add to protocol hash chains. */ err = sk->sk_prot->hash(sk); if (err) { sk_common_release(sk); goto out; } } if (sk->sk_prot->init) { err = sk->sk_prot->init(sk); if (err) { sk_common_release(sk); goto out; } } if (!kern) { err = BPF_CGROUP_RUN_PROG_INET_SOCK(sk); if (err) { sk_common_release(sk); goto out; } } out: return err; out_rcu_unlock: rcu_read_unlock(); goto out; }
那么Linux的 TCP协议中又是通过什么来切换状态的呢?
在逐步跟踪之后,我们找到了如下状态切换函数
tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure;
tcp_set_state(sk, TCP_SYN_SENT)把套接字的状态从CLOSE切换到SYN_SENT,并进一步调用了 tcp_connect(sk)来实际构造SYN并发送出去。然后调用inet_hash_connect(&tcp_death_row, sk)和
ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk),为套接字绑定一个端口,并记录在TCP的哈希表中。
总的来说,整个过程的函数调用关系是这样的:
tcp_v4_connect -> tcp_connect_init -> tcp_transmit_skb -> icsk->icsk_af_ops->send_check (tcp_v4_send_check)-> icsk->icsk_af_ops->queue_xmit (ip_queue_xmit)-> inet_csk_reset_xmit_timer
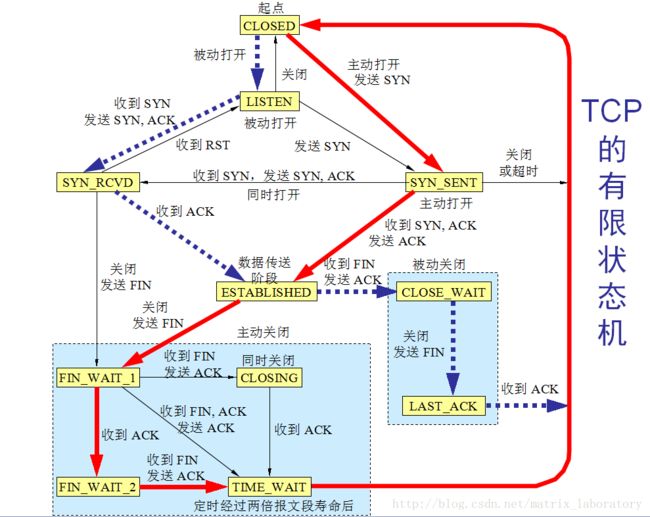
总体来说TCP的初始化过程大概就是如上文所示了,最后放一张TCP状态转换图