一、HBase的RK设计
HBase读写数据大多数是通过RK,MemStore/HFile存储也是按照字典顺序排列的RK存储,所以要关注RK。
RowKey设计原则:
1)长度原则:
RowKey不应该超过16字节,因为若是过长再以KV形式存储,对于HFile和MemStore来说会极大的占用存储空间。
2)唯一原则:
保证RowKey的唯一性,若向HBase中同一张表插入相同RowKey的数据,则原先存在的数据会被新的数据覆盖
3)排序原则:
RowKey是按照字典序排序的。HBase中的数据永远是根据RowKey的字典排序来排序的。
4)散列原则:
设计的RowKey应均匀的分布在各个HBase节点上。能将 RegionServer的负载均衡,否则容易产生所有新数据都在一个 RegionServer 上堆积的现象。
二、HBase如何避免热点
HBase表的数据是按照RowKey来分散到不同的Region,不合理的RowKey设计会导致热点问题,热点问题是大量的客户端直接访问集群中的一个或极少数的节点,而集群中的其他节点却处于相对空闲的状态,从而影响对HBase的读写性能。
1、加盐
在RK前面加添加固定长度的随机数前缀。可以让数据分散在不同的Regin上。
缺点:增加了读的开销。
2、hash
使用将hash(rk)的全部或者只取hash值的长度前4位+rk组成新的RowKey,这里说的hash包含MD5,sha1,sha256,sha512等算法,并不是仅限于Java的Hash值计算。
缺点:同样不利于读。
3、reverse反转

![]()
4、时间戳反转

![]()
字段的选择:
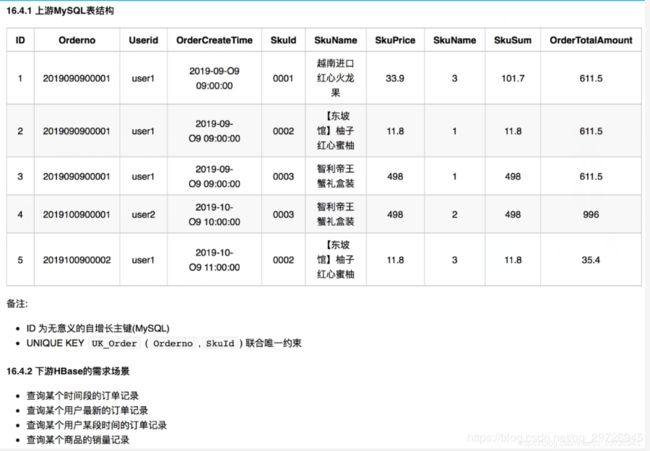
一定取决于你的最大的需求,结合具体的查询条件,高频率的尽可能的放到RK里面,现有如下两列数据以及四种需求,如何设计RowKey?
userid orderno skuname skuprice skunum skusum ordercretime
jepson 0001 西瓜 10 5 50 2019-07-07 12:00:00
jepson 0002 南瓜 10 50 500 2019-07-08 12:00:00# 需求
1)根据用户查询订单最新记录
where userid=jepson order by ordercretime desc limit 12)
where userid=jepson and (ordercretime>='xxx' and ordercretime<='xxxx')3)根据时间段查询订单记录
where (ordercretime>='xxx' and ordercretime<='xxxx')4)根据用户买了西瓜的订单记录
where userid=jepson and skuname='西瓜'根据以上原则及其方法和综上所述,RowKey=hash(userid).substring(0, 4)+userid+ (Long.Max_Value - timestamp),但是要注意 (Long.Max_Value - timestamp)要固定长度用0补齐。
例子:
![]()
最终的rowkey=hash(UserId).substring(0, 4)+UserId+Long.Max_Value - timestamp
调优(region个数):
1个region memstore额外的开销为hbase.hregion.memstore.mslab.chunksize=2m,如果你的一张表有20个region,那么额外开销为40M,一百张表就是100 * 40M = 4G。所以建议小表region个数为1,中表region个数为5,大表为20,1台rs节点的region 是100-200个。