这个叫路由层,实际上是把几个层拼在一块。
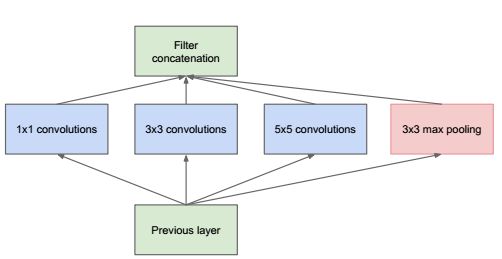
concat layer
这里面提供 4 个函数:
- route_layer make_route_layer(int batch, int n, int *input_layers, int *input_size);
- void forward_route_layer(const route_layer l, network net);
- void backward_route_layer(const route_layer l, network net);
- void resize_route_layer(route_layer *l, network *net);
route_layer make_route_layer(...)##
构建 route_layer,参数详情见 layer
route_layer make_route_layer(int batch, int n, int *input_layers, int *input_sizes)
{
fprintf(stderr,"route ");
route_layer l = {0};
l.type = ROUTE;
l.batch = batch;
l.n = n;// 这是指有多少个层参与拼接
l.input_layers = input_layers;
l.input_sizes = input_sizes;
int i;
int outputs = 0;
for(i = 0; i < n; ++i){
fprintf(stderr," %d", input_layers[i]);
outputs += input_sizes[i];
}
fprintf(stderr, "\n");
l.outputs = outputs;
l.inputs = outputs;
l.delta = calloc(outputs*batch, sizeof(float));
l.output = calloc(outputs*batch, sizeof(float));;
l.forward = forward_route_layer;
l.backward = backward_route_layer;
#ifdef GPU
l.forward_gpu = forward_route_layer_gpu;
l.backward_gpu = backward_route_layer_gpu;
l.delta_gpu = cuda_make_array(l.delta, outputs*batch);
l.output_gpu = cuda_make_array(l.output, outputs*batch);
#endif
return l;
}
resize_route_layer(...)##
改相应的参数, resize
void resize_route_layer(route_layer *l, network *net)
{
int i;
layer first = net->layers[l->input_layers[0]];
l->out_w = first.out_w;
l->out_h = first.out_h;
l->out_c = first.out_c;
l->outputs = first.outputs;
l->input_sizes[0] = first.outputs;
for(i = 1; i < l->n; ++i){
int index = l->input_layers[i];
layer next = net->layers[index];
l->outputs += next.outputs;
l->input_sizes[i] = next.outputs;
if(next.out_w == first.out_w && next.out_h == first.out_h){
l->out_c += next.out_c;
}else{
printf("%d %d, %d %d\n", next.out_w, next.out_h, first.out_w, first.out_h);
l->out_h = l->out_w = l->out_c = 0;
}
}
l->inputs = l->outputs;
l->delta = realloc(l->delta, l->outputs*l->batch*sizeof(float));
l->output = realloc(l->output, l->outputs*l->batch*sizeof(float));
#ifdef GPU
cuda_free(l->output_gpu);
cuda_free(l->delta_gpu);
l->output_gpu = cuda_make_array(l->output, l->outputs*l->batch);
l->delta_gpu = cuda_make_array(l->delta, l->outputs*l->batch);
#endif
}
forward_route_layer##
concat layers,关键 point:
维护 BWHN 四维图像一维化后的顺序位置
void forward_route_layer(const route_layer l, network net)
{
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){
int index = l.input_layers[i];
float *input = net.layers[index].output;
int input_size = l.input_sizes[i];
for(j = 0; j < l.batch; ++j){
copy_cpu(input_size, input + j*input_size, 1, l.output + offset + j*l.outputs, 1);
}
offset += input_size;
}
}
backward_route_layer(...)##
将得到的 delta ,分流到原各个 layer 的 delta 中去
void backward_route_layer(const route_layer l, network net)
{
int i, j;
int offset = 0;
for(i = 0; i < l.n; ++i){
int index = l.input_layers[i];
float *delta = net.layers[index].delta;
int input_size = l.input_sizes[i];
for(j = 0; j < l.batch; ++j){
axpy_cpu(input_size, 1, l.delta + offset + j*l.outputs, 1, delta + j*input_size, 1);
}
offset += input_size;
}
}