欢迎关注我的个人微信公众号:小纸屑
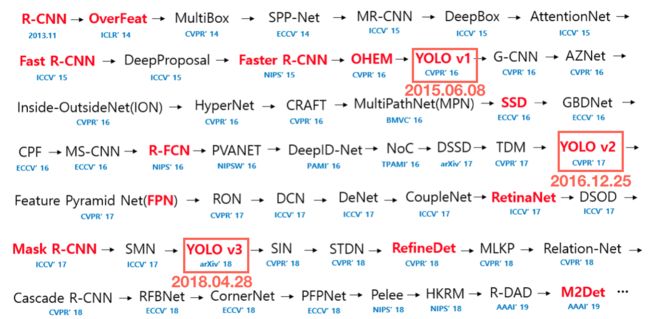
2015年6月,YOLOv1横空出世,标志着一步式物体检测算法时代的到来,同年12月,经典一步式物体检测算法SSD出世,在准确度和速度上均击败了傲娇的YOLOv1。经过一年的探索,2016年12月,YOLOv1作者Joseph Redmon发布YOLOv2,以图扳回一城。
下图是深度学习时代物体检测算法的里程碑,可以看到YOLO系列的相对位置。
效果
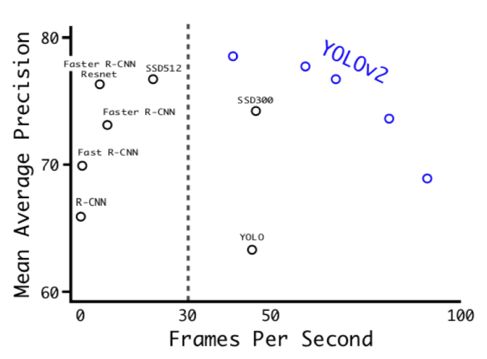
YOLOv2的效果可谓非常理想(貌似没有论文的结果不理想。。。。),如下图,在VOC数据集上准确度做到了当时的SOTA(state of the art),速度上更不用说,YOLOv2肯定是一骑绝尘,别的模型难以望其项背。

十个Trick
具体作者怎么做到的呢?无他,唯有trick而已。作者使用了整十个trick来提升性能,下图是作者给出的各个trick的对比试验,由衷感叹trick的重要性。

1、 batch norm
提升 2.4mPA
Batch Normalization主要用来解决internal covariance shift问题,可以加快训练和收敛速度,同时还有一定的正则化作用。整体上,还可以提升性能,这里提升了2.4mPA,非常多了。现在基本是CV标配,dropout反而用的比较少。
2、hi-res classifier
提升 3.7mPA

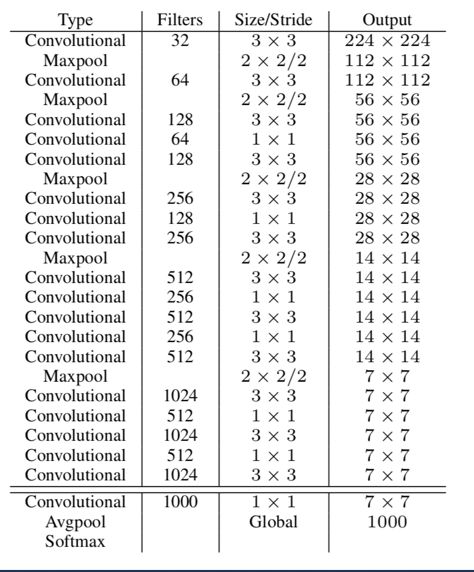
上图是YOLOv1的网络结构,feature extractor network是在ImageNet上训练的,这里的classifier指的就是feature extractor network。
YOLOv1只是在224x224分辨率上训练classifier,但物体检测的图片输入是448x448,存在分辨率不匹配的情况,所以YOLOv2采用的训练策略是,先在224x224分辨率上训练,最后10个epoch在448x448分辨率上训练。性能提升3.7mPA,提升显著。
3、convolutional 和4、anchor boxes
提升 -0.3mPA,但recall从81%提升到87%
1)convolutional
从YOLOv1的网络结构可以看出,YOLOv1输入是448x448x3,输出是7x7x30,YOLOv1输出前的object detection layers是两层全连接层。但明显的7x7x30这种结构与卷积的输出形式一致,因此用卷积实现更方便,也即将上图中的两个全连接层直接改为卷积层即可。
全卷积实现还有个非常大的好处,输入图片尺寸不再固定,可以任意变化,只要大于整体步长即可。这也是YOLOv2可以在准度和速度之间做权衡的本质。当图片分辨率高,输出的分辨率也高,一般更准,但计算量也更大,速度会变慢。当图片分辨率较小时,输出的分辨率也较小,准度下降,但计算量更小,速度更快。
改为全卷积实现后,输入图片的分辨率也从448x448变为418x418,整体分辨率缩减步长从64变为32,增强位置语义,相对应的输出分辨率也就从7x7变为13x13,输出的框更多。
2)anchor boxes
YOLOv1没有使用anchor box,借鉴Faster R-CNN和SSD,YOLOv2也使用了anchor box,3个ratio,3个scale,总共9个anchor box,增强学习的多样性,降低学习难度。
YOLOv2最终的输出为13x13x9x25。
用convolutional实现,并使用anchor box,最终导致准度下降0.3mAP,但recall从81%提升到87%,为其他trick提升准确度奠定基础。
5、new network
提升0.4mAP
借鉴Inception、VGG和Network in Network等网络模型优点,作者重新设计了特征提取网络Darknet19。网络结构如下图。
最终准度提升0.4mAP,并不算多,但网络速度更快,这才是作者的主要目的。
6、dimension priors和7、location prediction
提升4.8mAP
1)dimension priors
第四项trick中,作者使用了3个固定ratio和3个固定scale,总共9个anchor box来提高框的多样性。anchor box其实是先验框,网络最终回归的是anchor box与GT之间的差异,很显然,如果anchor box与GT约接近,则学习难度会更小。一个常用方法是,将真实的GT聚类产生anchor box。dimension priors就是通过聚类产生anchor box尺寸。
聚类中,每一个样本到中心点的距离一般用欧式距离,但这并不适合先验框尺寸的回归,因为先验框聚类是寻找与所有样本框的平均IOU最大的中心点,也即1-IOU最小的中心点。因此作者把聚类的距离定义为下式:
d(box,controid) = 1 - IOU(box,controid)
最终平均IOU与类簇数量之间的关系如下图:
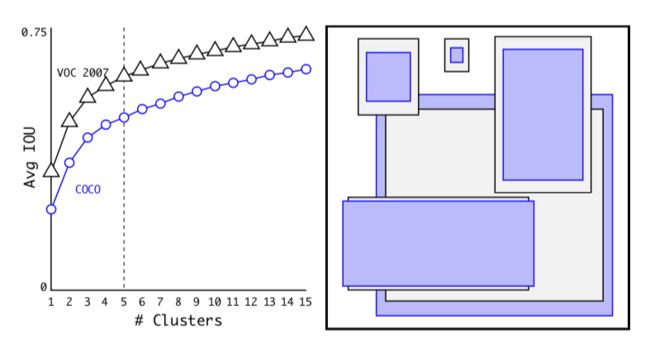
可以看出取5个Anchor Box比较合适。上图中右图是聚类后的Anchor Box尺寸,明显,数据集中高瘦的样本更多,宽矮的样本不多。
2)location prediction
Faster R-CNN预测中心点坐标,预测的是相对与anchor box长宽的相对值。
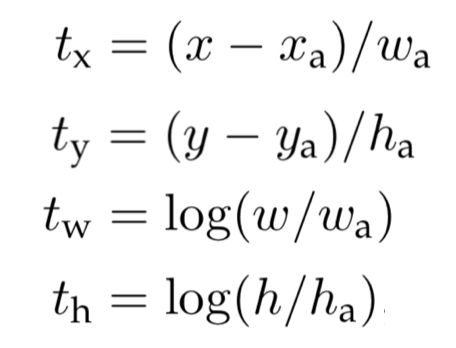
上式是Faster R-CNN中模型输出与预测框中心坐标、长宽的关系,x、y、w、h是预测框的中心点坐标和长宽,x_a、y_a、w_a、h_a是GT框的中心点坐标和长宽,t_x、t_y、t_w、t_h是模型输出。
明显的,t_x、t_y、t_w、t_h预测的都是相对值。

上图是YOLOv2中模型输出与预测框中心坐标、长宽的关系。t_x、t_y、t_w、t_h是模型输出,b_x、b_y、b_w、b_h是预测框的中心点坐标和长宽,p_h、p_w是先验框的长宽。
明显的,t_w、t_h预测的都是相对值,与Faster R-CNN相同。但t_x、t_y预测是GT框相对于所在cell左上角的绝对坐标。
这两项改进的提升效果是极其显著的,性能增加了4.8mAP。
8、passthrough
提升1.0mAP
SSD使用多分辨率输出,YOLOv2则采用了另外一个思路,将高分辨率的特征融合到输出所用的分辨率的feature map。这其实离低分辨率特征融合到高分辨率特征的FPN非常近了,可惜可惜。
具体怎么做的呢?如下图

将最后一个26x26x512的feature map,reshape成13x13x2048,再与最后一个13x13x1024的feature map Concatenate。然后再进行物体检测。
最终性能提升1.0mAP。
9、multi-scale
提升1.4mAP
再进行物体检测训练时(是在VOC或者COO上,不是在ImageNet),输入图片的分辨率不固定,而是随机从{320, 352, …, 608}中选取一个。这样使整个网络具有分辨率自适应的能力,避免过拟合于一个分辨率。
10、hi-res detector
提升1.8mAP
因为全卷积实现,YOLOv2输入的分辨率可以任意调整,输入分辨率越高,准度也越大。因此high resolution detector也可以提升性能。
COCO上的性能表现
不幸的是,YOLOv2在COCO上的表现都很差,都不如SSD300。
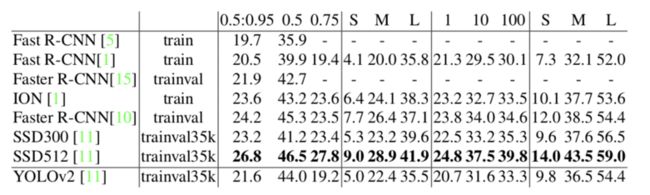
主要是YOLOv2对小物体检测不给力,backbone也不够强大。这个问题在YOLOv3上有所改善,但还是有所欠缺。
不过没关系,快而且准度OK就行了,生产环境场景没有COCO那么复杂。
结论
YOLOv2充分展示了各个trick累计产生的巨大能量。昭示我们,不要小看任何一个小trick的作用。
YOLOv2在COCO上的表现依旧差强人意,主要是YOLOv2对小物体检测不给力,backbone也不够强大。
真心希望看到一个又快又准的YOLOv4?
