穷竭搜索是将所有的可能性罗列出来,在其中寻找答案的方法。主要有深度优先搜索和广度优先搜索这两种方法
1.递归函数
在一个函数中再次调用该函数自身的行为叫做递归,这样的函数被称作递归函数。
阶乘:
int fact(int n) {
if (n == 0) return 1;
return n * fact(n - 1);
}
斐波那契数列:
int memo[MAX_N + 1];
int fib(int n) {
if (n <= 1) return n;
if (memo[n] != 0) return memo[n];
return memo[n] = fib(n - 1) + fib(n - 2);
}
2.栈
C++的标准库中,stack::pop完成的仅仅是移除最顶端的数据。如果要访问最顶端的数据,需要使用stack::top函数(这个操作通常也被称为peek)。
递归函数的递归过程也可以改用栈上的操作来实现。现实中需要如此改写的场合并不多,不过作为使用栈的练习试试看也是不错的。以下是使用stack的例子:
#include
#include
using namespace std;
int main() {
stack s; // 声明存储int类型数据的栈
s.push(1); // {} → {1}
s.push(2); // {1} → {1,2}
s.push(3); // {1,2} → {1,2,3}
printf("%d\n", s.top()); // 3
s.pop(); // 从栈顶移除 {1,2,3}→{1,2}
printf("%d\n", s.top()); // 2
s.pop(); // {1,2} → {1}
printf("%d\n", s.top()); // 1
s.pop(); // {1} → {}
return 0;
}
3.队列
在C++中queue::front是用来访问最底端数据的函数。以下是使用queue的例子:
#include
#include
using namespace std;
int main() {
queue que; // 声明存储int类型数据的队列
que.push(1); // {} → {1}
que.push(2); // {1} → {1,2}
que.push(3); // {1,2} → {1,2,3}
printf("%d\n", que.front()); // 1
que.pop(); // 从队尾移除 {1,2,3}→{2,3}
printf("%d\n", que.front()); // 2
que.pop(); // {2,3} → {3}
printf("%d\n", que.front()); // 3
que.pop(); // {3} → {}
return 0;
}
4.深度优先搜索
深度优先搜索(DFS,Depth-First Search)是搜索的手段之一。它从某个状态开始,不断地转移状态直到无法转移,然后回退到前一步的状态,继续转移到其他状态,如此不断重复,直至找到最终的解。例如求解数独,首先在某个格子内填入适当的数字,然后再继续在下一个格子内填入数字,如此继续下去。如果发现某个格子无解了,就放弃前一个格子上选择的数字,改用其他可行的数字。根据深度优先搜索的特点,采用递归函数实现比较简单。
部分和问题
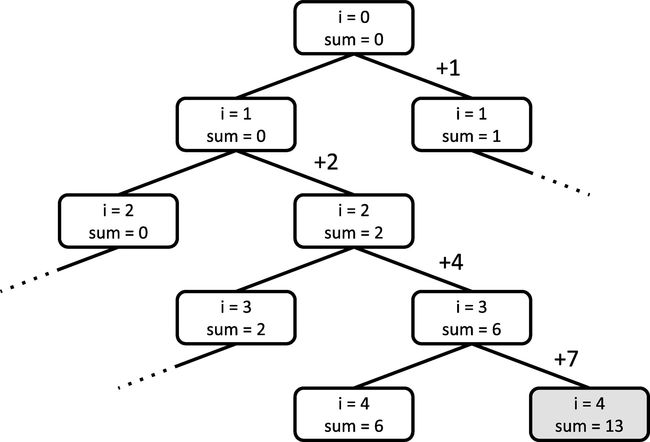
给定整数a1、a2、…、an,判断是否可以从中选出若干数,使它们的和恰好为k。
样例1
n=4
a={1,2,4,7}
k=13
输入
n=4
a={1,2,4,7}
k=13
输出
Yes (13 = 2 + 4 + 7)
样例2
输入
n=4
a={1,2,4,7}
k=15
输出
No
// 输入
int a[MAX_N];
int n, k;
// 已经从前i项得到了和sum,然后对于i项之后的进行分支
bool dfs(int i, int sum) {
// 如果前n项都计算过了,则返回sum是否与k相等
if (i == n) return sum == k;
// 不加上a[i]的情况
if (dfs(i + 1, sum)) return true;
// 加上a[i]的情况
if (dfs(i + 1, sum + a[i])) return true;
// 无论是否加上a[i]都不能凑成k就返回false
return false;
}
void solve() {
if (dfs(0, 0)) printf("Yes\n");
else printf("No\n");
}
Lake Counting (POJ No.2386)
有一个大小为N×M的园子,雨后积起了水。八连通的积水被认为是连接在一起的。请求出园子里总共有多少水洼?(八连通指的是下图中相对W的*的部分)
输入
N=10, M=12
园子如下图('W'表示积水,'.'表示没有积水)
W........WW.
.WWW.....WWW
....WW...WW.
.........WW.
.........W..
..W......W..
.W.W.....WW.
W.W.W.....W.
.W.W......W.
..W.......W.
输出
3
从任意的W开始,不停地把邻接的部分用'.'代替。1次DFS后与初始的这个W连接的所有W就都被替换成了'.',因此直到图中不再存在W为止,总共进行DFS的次数就是答案了。8个方向共对应了8种状态转移,每个格子作为DFS的参数至多被调用一次,所以复杂度为O(8×N×M)=O(N×M)。
// 输入
int N, M;
char field[MAX_N][MAX_M + 1]; // 园子
// 现在位置(x,y)
void dfs(int x, int y) {
// 将现在所在位置替换为.
field[x][y] = '.';
// 循环遍历移动的8个方向
for (int dx = -1; dx <= 1; dx++) {
for (int dy = -1; dy <= 1; dy++) {
// 向x方向移动dx,向y方向移动dy,移动的结果为(nx,ny)
int nx = x + dx, ny = y + dy;
// 判断(nx,ny)是不是在园子内,以及是否有积水
if (0 <= nx && nx < N && 0 <= ny && ny < M && field[nx][ny] == 'W') dfs(nx, ny);
}
}
return ;
}
void solve() {
int res = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (field[i][j] == 'W') {
// 从有W的地方开始dfs
dfs(i, j);
res++;
}
}
}
printf("%d\n", res);
}
5.宽度优先搜索
与深度优先搜索的不同之处在于搜索的顺序,宽度优先搜索总是先搜索距离初始状态近的状态。也就是说,它是按照开始状态→只需1次转移就可以到达的所有状态→只需2次转移就可以到达的所有状态→……这样的顺序进行搜索。对于同一个状态,宽度优先搜索只经过一次,因此复杂度为O(状态数×转移的方式)。
深度优先搜索(隐式地)利用了栈进行计算,而宽度优先搜索则利用了队列。搜索时首先将初始状态添加到队列里,此后从队列的最前端不断取出状态,把从该状态可以转移到的状态中尚未访问过的部分加入队列,如此往复,直至队列被取空或找到了问题的解。通过观察这个队列,我们可以就知道所有的状态都是按照距初始状态由近及远的顺序被遍历的。
迷宫的最短路径
给定一个大小为N×M的迷宫。迷宫由通道和墙壁组成,每一步可以向邻接的上下左右四格的通道移动。请求出从起点到终点所需的最小步数。请注意,本题假定从起点一定可以移动到终点。
输入
N=10, M=10(迷宫如下图所示。'#','.','S','G'分别表示墙壁、通道、起点和终点)
#S######.#
......#..#
.#.##.##.#
.#........
##.##.####
....#....#
.#######.#
....#.....
.####.###.
....#...G#
输出
22
const int INF = 100000000;
// 使用pair表示状态时,使用typedef会更加方便一些
typedef pair P;
// 输入
char maze[MAX_N][MAX_M + 1]; // 表示迷宫的字符串的数组
int N, M;
int sx, sy; // 起点坐标
int gx, gy; // 终点坐标
int d[MAX_N][MAX_M]; // 到各个位置的最短距离的数组
// 4个方向移动的向量
int dx[4] = {1, 0, -1, 0}, dy[4] = {0, 1, 0, -1};
// 求从(sx, sy)到(gx, gy)的最短距离
// 如果无法到达,则是INF
int bfs() {
queue que;
// 把所有的位置都初始化为INF
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++) d[i][j] = INF;
// 将起点加入队列,并把这一地点的距离设置为0
que.push(P(sx, sy));
d[sx][sy] = 0;
// 不断循环直到队列的长度为0
while (que.size()) {
// 从队列的最前端取出元素
P p = que.front(); que.pop();
// 如果取出的状态已经是终点,则结束搜索
if (p.first == gx && p.second == gy) break;
// 四个方向的循环
for (int i = 0; i < 4; i++) {
// 移动之后的位置记为(nx, ny)
int nx = p.first + dx[i], ny = p.second + dy[i];
// 判断是否可以移动以及是否已经访问过(d[nx][ny]!=INF即为已经访问过)
if (0 <= nx && nx < N && 0 <= ny && ny < M && maze[nx][ny] != '#' &&
d[nx][ny] == INF) {
// 可以移动的话,则加入到队列,并且到该位置的距离确定为到p的距离+1
que.push(P(nx, ny));
d[nx][ny] = d[p.first][p.second] + 1;
}
}
}
return d[gx][gy];
}
void solve() {
int res = bfs();
printf("%d\n", res);
}
宽度优先搜索与深度优先搜索一样,都会生成所有能够遍历到的状态,因此需要对所有状态进行处理时使用宽度优先搜索也是可以的。但是递归函数可以很简短地编写,而且状态的管理也更简单,所以大多数情况下还是用深度优先搜索实现。反之,在求取最短路时深度优先搜索需要反复经过同样的状态,所以此时还是使用宽度优先搜索为好。
宽度优先搜索会把状态逐个加入队列,因此通常需要与状态数成正比的内存空间。反之,深度优先搜索是与最大的递归深度成正比的。一般与状态数相比,递归的深度并不会太大,所以可以认为深度优先搜索更加节省内存。
此外,也有采用与宽度优先搜索类似的状态转移顺序,并且注重节约内存占用的迭代加深深度优先搜索(IDDFS,Iterative Deepening Depth-First Search)。IDDFS是一种在最开始将深度优先搜索的递归次数限制在1次,在找到解之前不断增加递归深度的方法
6.特殊状态的枚举
虽然生成可行解空间多数采用深度优先搜索,但在状态空间比较特殊时其实可以很简短地实现。比如,C++的标准库中提供了next_permutation这一函数,可以把n个元素共n!种不同的排列生成出来。又或者,通过使用位运算,可以枚举从n个元素中取出k个的状态或是某个集合中的全部子集等。
bool used[MAX_N];
int perm[MAX_N];
// 生成{0,1,2,3,4,...,n-1}的n!种排列
void permutation1(int pos, int n) {
if (pos == n) {
/*
* 这里编写需要对perm进行的操作
*/
return ;
}
// 针对perm的第pos个位置,究竟使用0~n-1中的哪一个进行循环
for (int i = 0; i < n; i++) {
if (!used[i]) {
perm[pos] = i;
// i已经被使用了,所以把标志设置为true
used[i] = true;
permutation1(pos + 1, n);
// 返回之后把标志复位
used[i] = false;
}
}
return ;
}
#include
// 即使有重复的元素也会生成所有的排列
// next_permutation是按照字典序来生成下一个排列的
int perm2[MAX_N];
void permutation2(int n) {
for (int i = 0; i < n; i++) {
perm2[i] = i;
}
do {
/*
* 这里编写需要对perm2进行的操作
*/
} while (next_permutation(perm2, perm2 + n));
// 所有的排列都生成后,next_permutation会返回false
return ;
}
7.剪枝
顾名思义,穷竭搜索会把所有可能的解都检查一遍,当解空间非常大时,复杂度也会相应变大。
比如n个元素进行排列时状态数总共有n!个,复杂度也就成了O(n!)。这样的话,即使n=15计算也很难较早终止。这里简单介绍一下此类情形要如何进行优化。
深度优先搜索时,有时早已很明确地知道从当前状态无论如何转移都不会存在解。这种情况下,不再继续搜索而是直接跳过,这一方法被称作剪枝。
我们回想一下深度优先搜索的例题“部分和问题”。这个问题中的限制条件如果变为0≤ai≤108,那么在递归中只要sum超过k了,此后无论选择哪些数都不可能让sum等于k,所以此后没有必要继续搜索。