一、分布式数据库诞生背景
随着互联网的飞速发展,业务量可能在短短的时间内爆发式地增长,对应的数据量可能快速地从几百 GB 涨到几百个TB,传统的单机数据库提供的服务,在系统的可扩展性、性价比方面已经不再适用。比如MySQL数据库,可以说绝大部分公司核心的数据都存储在MySQL中。MySQL的优点不用多说,缺点是没法做到水平扩展。MySQL要想能做到水平扩展,唯一的方法就业务层的分库分表或者使用中间件等方案。因此几年前就出现了各大公司重复造轮子,不断涌现出中间层分库分表解决方案,比如百度的DDBS,淘宝的 TDDL,360 的Atlas,及MyCAT,以爱可生基于MyCAT二次改造的DBLE等。但是,这些中间层方案也有很大局限性,执行计划不是最优,分布式事务,跨节点join,扩容复杂等。
随着业界相关分布式数据库论文的发布,分布式数据库应运而生,可以预见分布式数据库必将成为海量数据处理技术发展的又一个核心。目前业界最流行的分布式数据库有两类,一个是以Google Spanner为代表,一个是以AWS Auraro为代表。
Spanner 是 shared nothing 的架构,内部维护了自动分片、分布式事务、弹性扩展能力,数据存储还是需要sharding,plan计算也需要涉及多台机器,也就涉及了分布式计算和分布式事务。主要产品代表为TiDB、CockroachDB、OceanBase等;这三个产品可以说目前话题量不相下,TiDB属于国产PingCAP公司的、CockroachDB比TiDB早出来一年、OceanBase阿里团队的,2017年双11交出4200万/秒的处理能力。Auraro主要思想是计算和存储分离架构,使用共享存储技术,这样就提高了容灾和总容量的扩展。但是在协议层,只要是不涉及到存储的部分本质还是单机实例的MySQL,不涉及分布式存储和分布式计算,这样就和 MySQL 兼容性非常高。主要产品代表为 PolarDB。
二、TiDB简介
TiDB 是 PingCAP 公司基于 GoogleSpanner/F1论文实现的开源分布式 NewSQL 数据库。实现了自动的水平伸缩,强一致性的分布式事务,基于 Raft 算法的多副本复制等重要 NewSQL 特性。 TiDB 结合了 RDBMS 和 NoSQL 的优点,部署简单,在线弹性扩容和异步表结构变更不影响业务, 真正的异地多活及自动故障恢复保障数据安全,同时兼容 MySQL 协议,使迁移使用成本降到极低。
TiDB 具备如下 NewSQL 核心特性:
SQL支持 (TiDB 是 MySQL 兼容的)
水平线性弹性扩展
分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
三、TiDB整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。

TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与TiKV 交互获取数据,最终返回结果。 TiDB Server是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务 ID。PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是Region(区域),每个Region 负责存储一个 Key Range (从 StartKey 到 EndKey的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由PD 调度,这里也是以 Region 为单位进行调度。
核心特性
水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
四、TiDB原理与实现
三篇文章了解 TiDB 技术内幕:
说存储
说计算
谈调度
TiDB 架构是 SQL 层和 KV 存储层分离,相当于 InnoDB 插件存储引擎与 MySQL的关系。从下图可以看出整个系统是高度分层的,最底层选用了当前比较流行的存储引擎 RocksDB,RockDB性能很好但是是单机的,为了保证高可用所以写多份(一般为 3 份),上层使用 Raft 协议来保证单机失效后数据不丢失不出错。保证有了比较安全的KV 存储的基础上再去构建多版本,再去构建分布式事务,这样就构成了存储层 TiKV。有了TiKV,TiDB 层只需要实现 SQL 层,再加上MySQL 协议的支持,应用程序就能像访问 MySQL 那样去访问 TiDB 了。

这里还有个非常重要的概念叫做 Region。MySQL分库分表是将大的数据分成一张一张小表然后分散在多个集群的多台机器上,以实现水平扩展。同理,分布式数据库为了实现水平扩展,就需要对大的数据集进行分片,一个分片也就成为了一个Region。数据分片有两个典型的方案:一是按照 Key 来做 Hash,同样 Hash 值的 Key 在同一个 Region 上,二是Range,某一段连续的 Key 在同一个 Region 上,两种分片各有优劣,TiKV 选择了 Range partition。TiKV 以Region 作为最小调度单位,分散在各个节点上,实现负载均衡。另外 TiKV 以 Region 为单位做数据复制,也就是一个 Region保留多个副本,副本之间通过 Raft 来保持数据的一致。每个 Region 的所有副本组成一个 Raft Group,整个系统可以看到很多这样的 Raft groups。

最后简单说一下调度。 TiKV 节点会定期向 PD 汇报节点的整体信息,每个 Region Raft Group 的 Leader 也会定期向 PD 汇报信息,PD 不断的通过这些心跳包收集信息,获得整个集群的详细数据,从而进行调度,实现负载均衡。
五、TiDB软硬件环境
TiDB 作为一款开源分布式 NewSQL 数据库,可以很好的部署和运行在 Intel 架构服务器环境及主流虚拟化环境,并支持绝大多数的主流硬件网络。作为一款高性能数据库系统,TiDB 支持主流的 Linux 操作系统环境。
TiDB 支持部署和运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对于开发,测试,及生产环境的服务器硬件配置有以下要求和建议:
开发及测试环境
组件CPU内存本地存储网络实例数量(最低要求)
TiDB16核+16 GB+SAS, 200 GB+千兆网卡1
PD16核+16 GB+SAS, 200 GB+千兆网卡-
TiKV16核+32 GB+SAS, 200 GB+千兆网卡3
服务器总计4
生产环境
组件CPU内存硬盘类型硬盘数量单块硬盘大小网络实例数量(最低要求)
TiDB32核+128 GB+SSD最低2块500 GB+2块+ 万兆网卡2
PD16核+32 GB+SSD最低2块200 GB+2块+ 万兆网卡3
TiKV32核+128 GB+SSD最低2块200~500 GB2块+ 万兆网卡3
监控16核+32 GB+SAS最低4块200 GB+2块+ 千兆网卡1
服务器总计9
对于生产环境,这个配置要求还是挺高的,光硬件费用都是一笔不小的开销。再说目前TiDB还属于小步慢跑阶段,一般拿来都是在非核心业务使用,积累运维经验,所以这个配置对于现实环境来说还是有点高了,所以刚开始试水也是可以折中。
比如,因 TiDB 和 PD 对磁盘 IO 要求不高,所以只需要普通磁盘即可。TiKV 对磁盘 IO 要求较高,可以选择SSD,另官方建议 TiKV 硬盘大小建议不超过 500G,以防止硬盘损害时,数据恢复耗时过长。其TiDB 节点和 PD节点也可以部署在同台服务器上,而 TiKV 节点独立部署在服务上,最少 3 台,保持 3 副本,根据容量大小进行扩展。如对性能和可靠性有更高的要求,应尽可能分开部署。强烈建议使用万兆网卡。
网络环境
TiDB其正常运行需要网络环境提供如下的网络端口配置要求,管理员可根据实际环境中 TiDB 组件部署的方案,在网络侧和主机侧启用相关端口:
组件默认端口说明
TiDB4000应用及 DBA 工具访问通信端口
TiDB10080TiDB 状态信息上报通信端口
TiKV20160TiKV 通信端口
PD2379提供 TiDB 和 PD 通信端口
PD2380PD 集群节点间通信端口
Prometheus9090Prometheus 服务通信端口
Pushgateway9091TiDB, TiKV, PD 监控聚合和上报端口
Node_exporter9100TiDB 集群每个节点的系统信息上报通信端口
Grafana3000Web 监控服务对外服务和客户端(浏览器)访问端口
六、TiDB部署方案
Ansible 是一款自动化运维工具,TiDB-Ansible是 PingCAP 基于 Ansible playbook 功能编写的集群部署工具。使用 TiDB-Ansible 可以快速部署一个完整的 TiDB 集群(包括 PD、TiDB、TiKV 和集群监控模块)。
本部署工具可以通过配置文件设置集群拓扑,一键完成以下各项运维工作:
初始化操作系统,包括创建部署用户、设置 hostname 等
部署组件
滚动升级,滚动升级时支持模块存活检测
数据清理
环境清理
配置监控模块
TiDB-Ansible 工具还支持扩容及缩容操作。另外, TiDB也同样支持二进制部署、Docker部署、跨机房部署等不同方案。
七、TiDB监控方案
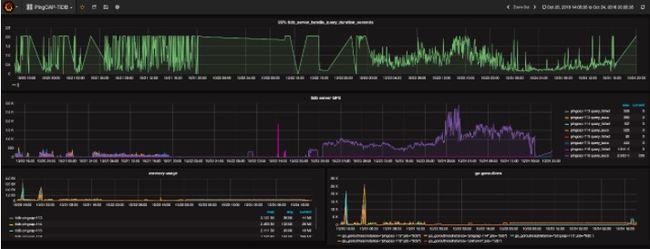
Pincap 团队给 TiDB 提供了一整套监控的方案,他们使用开源时序数据库 Prometheus 作为监控和性能指标信息存储方案,使用Grafana 作为可视化组件进行展示。具体如下图,在 client 端程序中定制需要的 Metric 。Push GateWay 来接收Client Push 上来的数据,统一供 Prometheus 主服务器抓取。AlertManager 用来实现报警机制,使用 Grafana来进行展示。

Grafana 是一个开源的 metric 分析及可视化系统。使用 Grafana 来展示 TiDB 的各项性能指标 。如下图所示:
八、TiSpark助力OLAP
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。借助 Spark 平台,同时融合 TiKV分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/AnalyticalProcessing)需求。 TiSpark 依赖于 TiKV 集群和 Placement Driver(PD)。当然,TiSpark也需要您搭建一个 Spark 集群。
TiSpark 是将 Spark SQL 直接运行在分布式存储引擎 TiKV 上的 OLAP 解决方案。其架构图如下:
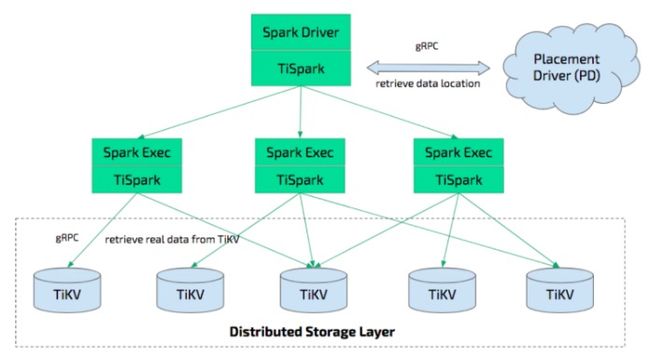
TiSpark 深度整合了 Spark Catalyst 引擎, 可以对计算提供精确的控制,使 Spark 能够高效的读取 TiKV 中的数据,提供索引支持以实现高速的点查。通过多种计算下推减少 Spark SQL 需要处理的数据大小,以加速查询;利用 TiDB 的内建的统计信息选择更优的查询计划。从数据集群的角度看,TiSpark + TiDB 可以让用户无需进行脆弱和难以维护的 ETL,直接在同一个平台进行事务和分析两种工作,简化了系统架构和运维。
除此之外,用户借助 TiSpark 项目可以在 TiDB 上使用 Spark 生态圈提供的多种工具进行数据处理。例如使用 TiSpark 进行数据分析和 ETL;使用 TiKV 作为机器学习的数据源;借助调度系统产生定时报表等等。
九、TiDB周边工具
mydumper/loader
备份恢复工具,使用 mydumper 从 TiDB 导出数据进行备份,然后用 loader 将其导入到 TiDB 里面进行恢复。虽然TiDB 也支持使用 MySQL 官方的 mysqldump 工具来进行数据的备份恢复工作,但相比于 mydumper /loader,性能会慢很多,大量数据的备份恢复会花费很多时间,因此并不推荐。
其mydumper/myloader是Percona开源产品,多线程MySQL逻辑备份和恢复工具。那为什么PingCAP还开发loader工具呢?官方是这么说的:在使用过程中,mydumper问题不大,但是 myloader 由于缺乏出错重试、断点续传这样的功能,使用起来很不方便。所以我们开发了 loader,能够读取mydumper 的输出数据文件,通过 mysql protocol 向 TiDB/MySQL 中导入数据。
syncer
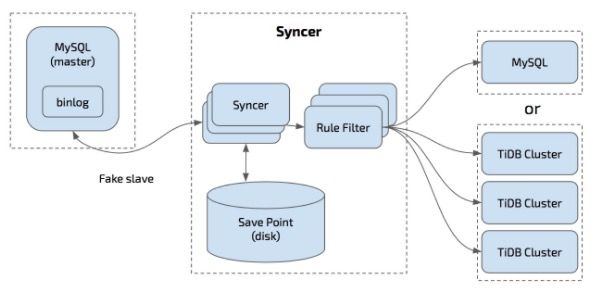
根据MySQL binlog增量同步工具,Syncer 可以部署在任一台可以连通对应的 MySQL 和 TiDB 集群的机器上,推荐部署在 TiDB 集群。
架构图如下:
TiDB-Binlog
TiDB-Binlog 用于收集 TiDB 的 Binlog,并提供实时备份和同步功能的商业工具。
TiDB-Binlog 支持以下功能场景:
数据同步: 同步 TiDB 集群数据到其他数据库
实时备份和恢复: 备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复
PD Control
PD Control 是 PD 的命令行工具,用于获取集群状态信息和调整集群。
TiDB官方:https://pingcap.com
该文转载自 http://www.ywnds.com/?p=12418