
摘要:本文详细讲解了 python 网络爬虫,并介绍抓包分析等技术,实战训练三个网络爬虫案例,并简单补充了常见的反爬策略与反爬攻克手段。通过本文的学习,可以快速掌握网络爬虫基础,结合实战练习,写出一些简单的爬虫项目。
本次的分享主要围绕以下五个方面:
一、数据采集与网络爬虫技术简介
二、网络爬虫技术基础
三、抓包分析
四、挑战案例
五、推荐内容
一、数据采集与网络爬虫技术简介
网络爬虫是用于数据采集的一门技术,可以帮助我们自动地进行信息的获取与筛选。从技术手段来说,网络爬虫有多种实现方案,如 PHP、Java、Python ...。那么用 python 也会有很多不同的技术方案(Urllib、requests、scrapy、selenium...),每种技术各有各的特点,只需掌握一种技术,其它便迎刃而解。同理,某一种技术解决不了的难题,用其它技术或方依然无法解决。网络爬虫的难点并不在于网络爬虫本身,而在于网页的分析与爬虫的反爬攻克问题。希望在本次课程中大家可以领会爬虫中相对比较精髓的内容。
二、网络爬虫技术基础
在本次课中,将使用 Urllib 技术手段进行项目的编写。同样,掌握了该技术手段,其他的技术手段也不难掌握,因为爬虫的难点不在于技术手段本身。本知识点包括如下内容:
·Urllib 基础
· 浏览器伪装
· 用户代理池
· 糗事百科爬虫实战
需要提前具备的基础知识:正则表达式
1)Urllib 基础
爬网页
打开 python 命令行界面,两种方法:ulropen() 爬到内存,urlretrieve() 爬到硬盘文件。
>>> import urllib.request#open百度,读取并爬到内存中,解码(ignore可忽略解码中的细微错误), 并赋值给data>>> data=urllib.request.ulropen("http://www.baidu.com").read().decode("utf-8”, “ignore")#判断网页内的数据是否存在,通过查看data长度>>> len(data)提取网页标题#首先导入正则表达式, .*?代表任意信息,()代表要提取括号内的内容>>> import re#正则表达式>>> pat="(.*?)"#re.compile()指编译正则表达式#re.S是模式修正符,网页信息往往包含多行内容,re.S可以消除多行影响>>> rst=re.compile(pat,re.S).findall(data)>>> print(rst)#[‘百度一下,你就知道’]
同理,只需换掉网址可爬取另一个网页内容
>>> data=urllib.request.ulropen("http://www.jd.com").read().decode("utf-8", "ignore")>>> rst=re.compile(pat,re.S).findall(data)>>> print(rst)
上面是将爬到的内容存在内存中,其实也可以存在硬盘文件中,使用 urlretrieve() 方法
>>> urllib.request.urlretrieve("http://www.jd.com",filename="D:/我的教学/Python/阿里云系列直播/第2次直播代码/test.html")
之后可以打开 test.html,京东网页就出来了。由于存在隐藏数据,有些数据信息和图片无法显示,可以使用抓包分析进行获取。
2)浏览器伪装
尝试用上面的方法去爬取糗事百科网站 url="https://www.qiushibaike.com/",会返回拒绝访问的回复,但使用浏览器却可以正常打开。那么问题肯定是出在爬虫程序上,其原因在于爬虫发送的请求头所导致。
打开糗事百科页面,如下图,通过 F12,找到 headers,这里主要关注用户代理 User-Agent 字段。User-Agent 代表是用什么工具访问糗事百科网站的。不同浏览器的 User-Agent 值是不同的。那么就可以在爬虫程序中,将其伪装成浏览器。

将 User-Agent 设置为浏览器中的值,虽然 urlopen() 不支持请求头的添加,但是可以利用 opener 进行 addheaders,opener 是支持高级功能的管理对象。代码如下:
#浏览器伪装url="https://www.qiushibaike.com/"#构建openeropener=urllib.request.build_opener()#User-Agent设置成浏览器的值UA=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")#将UA添加到headers中opener.addheaders=[UA]urllib.request.install_opener(opener)data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
3)用户代理池
在爬取过程中,一直用同样一个地址爬取是不可取的。如果每一次访问都是不同的用户,对方就很难进行反爬,那么用户代理池就是一种很好的反爬攻克的手段。
第一步,收集大量的用户代理 User-Agent
#用户代理池uapools=[ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", ]
第二步,建立函数 UA(),用于切换用户代理 User-Agent
def UA(): opener=urllib.request.build_opener() #从用户代理池中随机选择一个 thisua=random.choice(uapools) ua=("User-Agent",thisua) opener.addheaders=[ua] urllib.request.install_opener(opener) print("当前使用UA:"+str(thisua))
for 循环,每访问一次切换一次 UA
for i in range(0,10): UA() data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
每爬 3 次换一次 UA
for i in range(0,10): if(i%3==0): UA() data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
(* 每几次做某件事情,利用求余运算)
4)第一项练习 - 糗事百科爬虫实战
目标网站:https://www.qiushibaike.com/
需要把糗事百科中的热门段子爬取下来,包括翻页之后内容,该如何获取?
第一步,对网址进行分析,如下图所示,发现翻页之后变化的部分只是 page 后面的页面数字。

第二步,思考如何提取某个段子?查看网页代码,如下图所示,可以发现
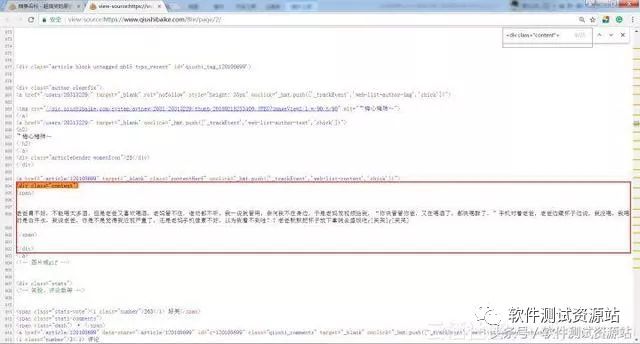
第三步,利用上面所提到的用户代理池进行爬取。首先建立用户代理池,从用户代理池中随机选择一项,设置 UA。
import urllib.requestimport reimport random#用户代理池uapools=[ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", ]def UA(): opener=urllib.request.build_opener() thisua=random.choice(uapools) ua=("User-Agent",thisua) opener.addheaders=[ua] urllib.request.install_opener(opener) print("当前使用UA:"+str(thisua))#for循环,爬取第1页到第36页的段子内容for i in range(0,35): UA() #构造不同页码对应网址 thisurl="http://www.qiushibaike.com/8hr/page/"+str(i+1)+"/" data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore") #利用
还可以定时的爬取:
Import time#然后在后面调用time.sleep()方法
换言之,学习爬虫需要灵活变通的思想,针对不同的情况,不同的约束而灵活运用。
三、抓包分析
抓包分析可以将网页中的访问细节信息取出。有时会发现直接爬网页时是无法获取到目标数据的,因为这些数据做了隐藏,此时可以使用抓包分析的手段进行分析,并获取隐藏数据。
1)Fiddler 简介
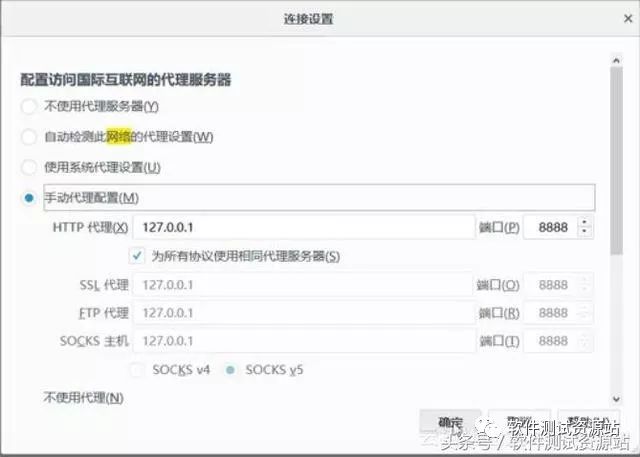
抓包分析可以直接使用浏览器 F12 进行,也可以使用一些抓包工具进行,这里推荐 Fiddler。Fiddler 下载安装。假设给 Fiddler 配合的是火狐浏览器,打开浏览器,如下图,找到连接设置,选择手动代理设置并确定。
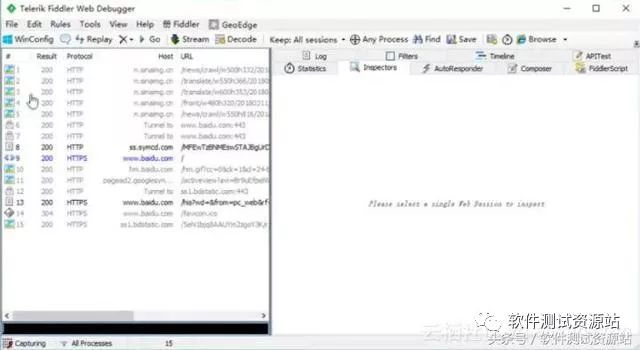
假设打开百度,如下图,加载的数据包信息就会在 Fiddler 中左侧列表中列出来,那么网站中隐藏相关的数据可以从加载的数据包中找到。
2)第二项练习 - 腾讯视频评论爬虫实战
目标网站:https://v.qq.com/
需要获取的数据:某部电影的评论数据,实现自动加载。
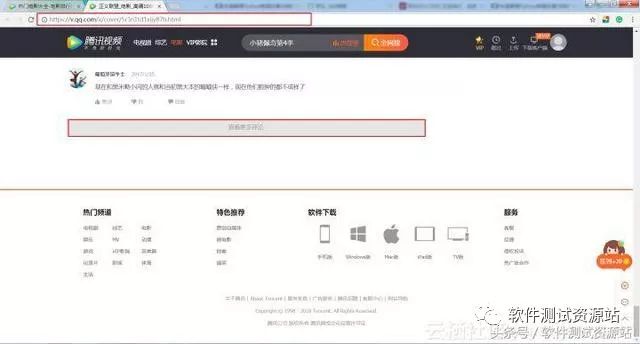
首先可以发现腾讯视频中某个视频的评论,在下面的图片中,如果点击” 查看更多评论”,网页地址并无变化,与上面提到的糗事百科中的页码变化不同。而且通过查看源代码,只能看到部分评论。即评论信息是动态加载的,那么该如何爬取多页的评论数据信息?
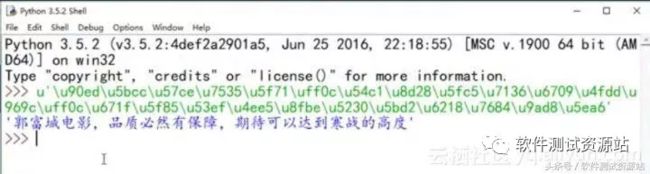
第一步,分析腾讯视频评论网址变化规律。点击” 查看更多评论”,同时打开 Fiddler,第一条信息的 TextView 中,TextView 中可以看到对应的 content 内容是 unicode 编码,刚好对应的是某条评论的内容。
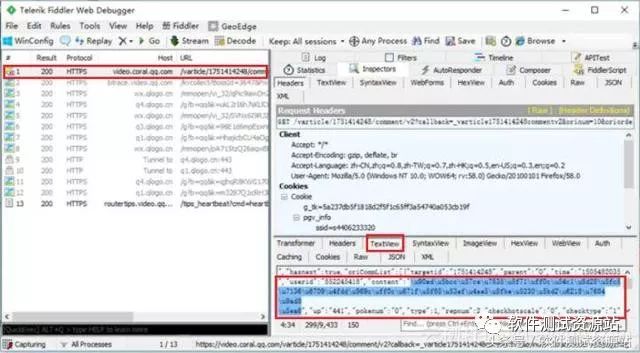
解码出来可以看到对应评论内容。
将第一条信息的网址复制出来进行分析,观察其中的规律。下图是两个紧连着的不同评论的 url 地址,如下图,可以发现只有 cursor 字段发生变化,只要得到 cursor,那么评论的地址就可以轻松获得。如何找到 cursor 值?
第二步,查找网址中变化的 cursor 字段值。从上面的第一条评论信息里寻找,发现恰好在 last 字段值与后一条评论的 cursor 值相同。即表示 cursor 的值是迭代方式生成的,每条评论的 cursor 信息在其上一条评论的数据包中寻找即可。
第三步,完整代码
a. 腾讯视频评论爬虫: 获取” 深度解读” 评论内容(单页评论爬虫)
#单页评论爬虫import urllib.requestimport re#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]#视频idvid="j6cgzhtkuonf6te"#评论idcid="6233603654052033588"num="20"#构造当前评论网址url="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+"&reqnum="+numheaders={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0", "Content-Type":"application/javascript", }opener=urllib.request.build_opener()headall=[]for key,value in headers.items(): item=(key,value) headall.append(item)opener.addheaders=headallurllib.request.install_opener(opener)#爬取当前评论页面data=urllib.request.urlopen(url).read().decode("utf-8")titlepat='"title":"(.*?)"'commentpat='"content":"(.*?)"'titleall=re.compile(titlepat,re.S).findall(data)commentall=re.compile(commentpat,re.S).findall(data)for i in range(0,len(titleall)): try: print("评论标题是:"+eval('u"'+titleall[i]+'"')) print("评论内容是:"+eval('u"'+commentall[i]+'"')) print("------") except Exception as err: print(err)
b. 腾讯视频评论爬虫: 获取” 深度解读” 评论内容(自动切换下一页评论的爬虫)
#自动切换下一页评论的爬虫import urllib.requestimport re#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]vid="j6cgzhtkuonf6te"cid="6233603654052033588"num="3"headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0", "Content-Type":"application/javascript", }opener=urllib.request.build_opener()headall=[]for key,value in headers.items(): item=(key,value) headall.append(item)opener.addheaders=headallurllib.request.install_opener(opener)#for循环,多个页面切换for j in range(0,100): #爬取当前评论页面 print("第"+str(j)+"页")#构造当前评论网址thisurl="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+"&reqnum="+numdata=urllib.request.urlopen(thisurl).read().decode("utf-8")titlepat='"title":"(.*?)","abstract":"'commentpat='"content":"(.*?)"'titleall=re.compile(titlepat,re.S).findall(data)commentall=re.compile(commentpat,re.S).findall(data)lastpat='"last":"(.*?)"'#获取last值,赋值给cid,进行评论id切换cid=re.compile(lastpat,re.S).findall(data)[0]for i in range(0,len(titleall)): try: print("评论标题是:"+eval('u"'+titleall[i]+'"')) print("评论内容是:"+eval('u"'+commentall[i]+'"')) print("------") except Exception as err: print(err)
四、挑战案例
1) 第三项练习 - 中国裁判文书网爬虫实战
目标网站:http://wenshu.court.gov.cn/
需要获取的数据:2018 年上海市的刑事案件接下来进入实战讲解。
第一步,观察换页之后的网页地址变化规律。打开中国裁判文书网 2018 年上海市刑事案件的第一页,在换页时,如下图中的地址,发现网址是完全不变的,这种情况就是属于隐藏,使用抓包分析进行爬取。

第二步,查找变化字段。从 Fiddler 中可以找到,获取某页的文书数据的地址:http://wenshu.court.gov.cn/List/ListContent
可以发现没有对应的网页变换,意味着中国裁判文书网换页是通过 POST 进行请求,对应的变化数据不显示在网址中。通过 F12 查看网页代码,再换页操作之后,如下图,查看 ListContent,其中有几个字段需要了解:
Param: 检索条件
Index: 页码
Page: 每页展示案件数量
...
重要的是最后三个字段(vl5x,number,guid)该如何获取?首先,guid 即 uuid,叫全球唯一标识,是利用 python 中的 uuid 随机生成的字段。其次是 number 字段,找到 ListContent 上面的 GetCode 请求,恰好其 Response 中包含了 number 字段的值。而 GetCode 又是通过 POST 请求的,发现请求的字段只要 guid 这一项, 那么问题便迎刃而解。
最后,难点在于 vl5x 字段如何获取?打开 Fiddler,在换页操作后,查看 ListContent 中的 vl5x 的值,并在此次 ListContent 之前出现的数据包中的 TextView 里寻找这个字段或值,一般的网站可以很容易找到,但中国裁判文书网是政府网站,反爬策略非常高明,寻找的过程需要极高的耐心。
事实上,中国裁判文书网的 vl5x 字段可以从某个 js 包中获得,获取的方式是通过 getKey() 函数。从网页源代码中找到 getKey() 函数的 js 代码,由于代码是 packed 状态,用 unpacked 工具, 将其进行解码,后利用 js 界面美观工具可以方便理解。
但无关紧要,只需直接将 getKey() 函数 s 代码复制到 unpack_js.html 中,就可以解出 vl5x 字段的值,其中需要用到 Cookie 中的 vjkl5 字段值。需要注意提前下载好 base64.js 和 md5.js,并在 unpack_js.html 加载。
第三步,以下是中国裁判文书网爬虫完整代码:
import urllib.requestimport reimport http.cookiejarimport execjsimport uuid#随机生成guidguid=uuid.uuid4()print("guid:"+str(guid))fh=open("./base64.js","r")js1=fh.read()fh.close()fh=open("./md5.js","r")js2=fh.read()fh.close()fh=open("./getkey.js","r")js3=fh.read()fh.close()#将完整js代码都加载进来js_all=js1+js2+js3#在生成的CookieJar添加到opner中cjar=http.cookiejar.CookieJar()opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))#Referer常用于反爬,指来源网址opener.addheaders=[("Referer","http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82")]urllib.request.install_opener(opener)#用户代理池import randomuapools=[ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",]#访问首页urllib.request.urlopen("http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82").read().decode("utf-8","ignore")#将Cookie中的vjkl5字段提取出来pat="vjkl5=(.*?)s"vjkl5=re.compile(pat,re.S).findall(str(cjar))if(len(vjkl5)>0): vjkl5=vjkl5[0]else: vjkl5=0print("vjkl5:"+str(vjkl5))#将js代码中的旧Cookie的值替换为新的vjkl5的值js_all=js_all.replace("ce7c8849dffea151c0179187f85efc9751115a7b",str(vjkl5))#使用python执行js代码,请提前安装好对应模块(在命令行中执行pip install pyexejs)compile_js=execjs.compile(js_all)#获得vl5x字段值vl5x=compile_js.call("getKey")print("vl5x:"+str(vl5x))url="http://wenshu.court.gov.cn/List/ListContent"#for循环,切换第1页到10页for i in range(0,10):try: #从GetCode中获取number字段值 codeurl="http://wenshu.court.gov.cn/ValiCode/GetCode" #上面提到,GetCode中,只要guid一个字段,将其获取到 codedata=urllib.parse.urlencode({ "guid":guid, }).encode('utf-8') codereq = urllib.request.Request(codeurl,codedata) codereq.add_header('User-Agent',random.choice(uapools)) codedata=urllib.request.urlopen(codereq).read().decode("utf-8","ignore") #print(codedata) #构造请求的参数 postdata =urllib.parse.urlencode({ "Param":"案件类型:刑事案件,裁判年份:2018,法院地域:上海市", "Index":str(i+1), "Page":"20", "Order":"法院层级", "Direction":"asc", "number":str(codedata), "guid":guid, "vl5x":vl5x, }).encode('utf-8') #直接发送POST请求 req = urllib.request.Request(url,postdata) req.add_header('User-Agent',random.choice(uapools)) #获得ListContent中的文书ID值 data=urllib.request.urlopen(req).read().decode("utf-8","ignore") pat='文书ID.*?".*?"(.*?)."' allid=re.compile(pat).findall(data) print(allid) except Exception as err: print(err)
如此便可批量获取中国裁判文书网中的案件信息。友情提示,如果频繁爬取该网站,需扩充用户代理池。
五、推荐内容
1)常见反爬策略与反爬攻克手段介绍
数据的隐藏可以算是一种反爬策略之一,抓包分析是该反爬策略常见的反爬攻克手段。
当然,反爬还有很多手段,比如通过 IP 限制、UA 限制、验证码限制... 等等.
2)如何深入学习 Python 网络爬虫(深入学习路线介绍)
通过上述的介绍,相信对网络爬虫已经有了基础的了解,以及能够写出一些简单的爬虫项目。
以下项目可以提供练习:
淘宝商品图片爬虫项目
淘宝商品爬虫项目
…
3)关于 Python 爬虫,推荐书籍
《Python 程序设计基础实战教程》 . 清华大学出版社. 2018 年
《精通 Python 网络爬虫》. 机械工业出版社. 2017 年 4 月
4)所有项目代码我都放打包放到了后台,私信回复关键词【资料包】获取
作者:西边人
程序爬虫各种有用资源分享给大家
私人微信:mcfmcfmcf