一、前言
主要来讲述一下Kibana使用以及上生产时候的一些配置,要是大家对这块比较感兴趣我到时候也可以在结合Grafana做一些图表方面的介绍,后面等介绍完Beats以后我去阿里云租几台机器,给大家来个ELK方面的实战,然后要是时间充分在和大家一起学习下Elasticsearch源码,废话不多说开始喽;
二、Kibana配置
主要介绍一些常用的配置,剩下一些冷门的大家可以查看下官方配置;
server.port:
默认值: 5601 该配置指定Kibana 使用的端口号;
server.host:
默认值: "localhost" 指定后端服务器的主机地址;
server.maxPayloadBytes:
默认值: 1048576 服务器请求的最大负载,单位字节;
server.name:
默认值: "主机名" Kibana 实例对外展示的名称;
elasticsearch.url:
默认值: "http://localhost:9200" 用来处理所有查询的 Elasticsearch 实例的 URL ;
kibana.index:
默认值: ".kibana" Kibana 使用 Elasticsearch 中的索引来存储保存的检索,可视化控件以及仪表板。如果没有索引,Kibana 会创建一个新的索引;
elasticsearch.requestTimeout:
默认值: 30000 等待后端或 Elasticsearch 的响应时间,单位微秒,该值必须为正整数;
logging.dest:
默认值: stdout指定 Kibana 日志输出的文件;
以上基本就是常用的甚至一些都用不到,如果大家想启用SSL大家去参考下官方配置,我将这块的都已经默认关闭了;接下来我们主要来介绍下生产线上一些相关方面的配置,之前我们介绍Elasticsearch 的时候只介绍两种主要的节点,还有一个节点类型没有介绍,他就是协调节点,该节点作用负载平衡器,该节点处理传入的HTTP请求,根据需要将操作重定向到群集中的其他节点,并收集并返回结果;我们主要利用这个特性来搭建Kibana生产的部署架构,当然你直接配置也是可以,这个只是推荐,我们主要利用这个节点来协调Kibana 的请求,获取返回我们需要数据,官方有个名字Coordinating only node,整体架构如下图:
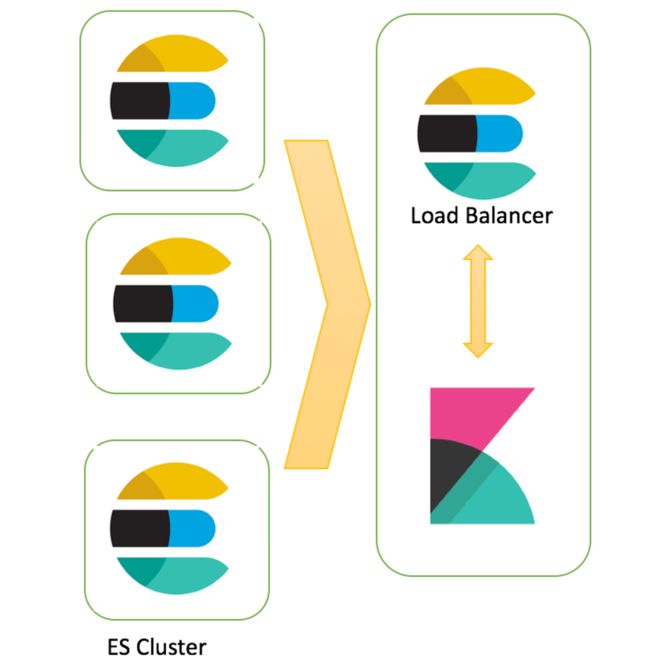
接下来我们结合上面架构我们需要如何配置Elasticsearch,
1.在与Kibana相同的计算机上安装Elasticsearch客户端节点;
2.通过设置将节点配置为仅协调节点:
node.master: false;
node.data: false;
node.ingest: false;
3.将客户端节点添加到elasticsearch集群;
cluster.name: "my_cluster";
4.配置network.host(对Kibana HTTP连接)和transport.host(需要连接的到集群上的节点):
network.host: localhost;
http.port: 9200;
transport.host: YOUR_IP;
transport.tcp.port: 9300;
5.配置kibana;
elasticsearch.url: "http://localhost:9200";
接下来我们思考下这样架构的好处,协调节点不参与选主环节,减少了选主时间,通过协调节点专门处理监控或者我们需要的一些数据的请求,使其他节点专注于线上请求,提升了效率,要说有什么不好,那就是需要多一台机器;接下来我们来通过Kibana做一些图表;
三、Kibana入门实战
Elasticsearch集群搭建和Logstash相关下载和安装就不讲解了,我们主要借助Kibana来分析120年奥运会运动员或者国家一些情况,数据我是在这个网址下载的,准确性方面我没去核对,我们主要借助这些数据来学习Kibana就好了。整体流程是通过Logstash讲CSV文件导入到Elasticsearch,然后借助Kibana分析,我把Logstash配置粘贴到下面,通过使用logstash.bat -f ../config/logstash.conf启动起来就可以将文件导入到Elasticsearch中,在启动起来之前我们还需要在Elasticsearch建立模板,当然也可以通过Logstash指定模板这个有兴趣自己百度下,我也将Mapping模板放到下面;
input { file{ path => ["C:/Users/wangt/Desktop/athlete_events.csv"] # 设置多长时间检测文件是否修改(单位:秒) stat_interval => 1 # 监听文件的起始位置,默认是end start_position => beginning # 设置多长时间会写入读取的位置信息(单位:秒) sincedb_write_interval => 5 } } filter { #去除每行记录中需要过滤的NA,替换为空字符串 mutate{ gsub => [ "message", "NA", "" ] } csv { # 每行记录的字段之间以,分隔 separator => "," columns => ["name","sex","age","height","weight","team","noc","games","year","season","city","sport","event","medal"] # 过滤掉默认加上的字段 remove_field => ["host", "path","message"] } } output { elasticsearch { hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"] index => "olympicawards" } }
{ "mappings":{ "doc":{ "properties":{ "@timestamp":{ "type":"date" }, "@version":{ "type":"keyword" }, "name":{ "type":"keyword" }, "sex":{ "type":"keyword" }, "age":{ "type":"integer" }, "weight":{ "type":"float" }, "team":{ "type":"keyword" }, "noc":{ "type":"keyword" }, "games":{ "type":"keyword" }, "year":{ "type":"integer" }, "season":{ "type":"keyword" }, "sport":{ "type":"keyword" }, "event":{ "type":"keyword" }, "medal":{ "type":"keyword" } } } } }
以上就是大家需要的模板,这里不做特别复杂仪表盘等ELK实战的时候我们来做一些比较复杂东西,但是本质上是不变的,只要对DSL足够了解,构建仪表盘都是分分钟的事,我们先来整体介绍下Kibana的整体界面,然后在做一个简单的仪表盘就完成这篇博客;
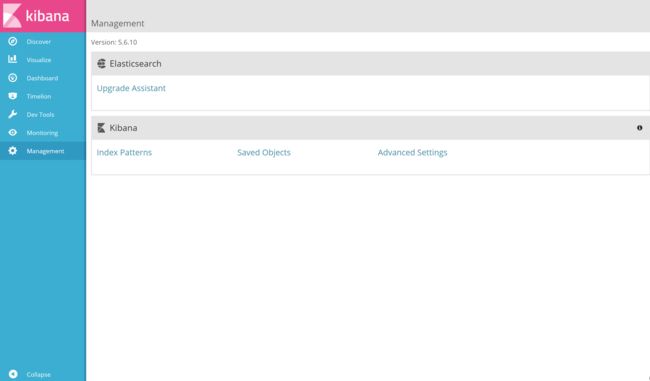
主要有7大模块,介绍下每个模块的作用:
Discover:以页面的形式展示Elasticsearch中的数据,可以做一些过滤、搜索等等操作;
Visualize:根据Elasticsearch创建可视化的界面;
Dashboard:仪表盘可以将可视化界面组合在一些,类似现在的比较流行的大屏界面一样;
Timelion:时间序列数据可视化工具,按照时间检索数据;
Dev Tools:通过DSL进行查询数据的工具;
Monitoring:监控数据Elasticsearch、Logstash和Beats运行状况的工具;
Management:Kibana管理索引以及一些参数配置地方;
接下来我们使用Visualize和Dashboard做图表,通过Visualize构建相关类型的图表,有如下类型:
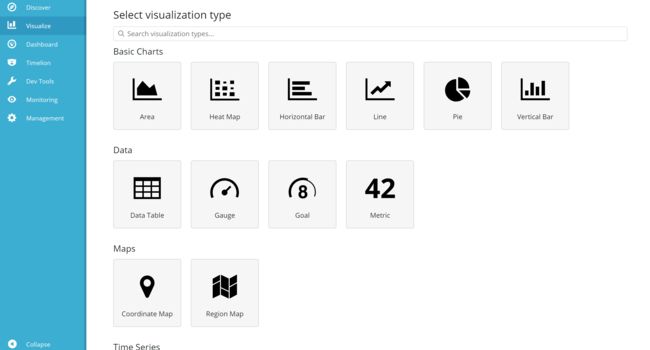
选中想要构建类型,通过添加一些类型或者增加一些过滤条件来展示数据;
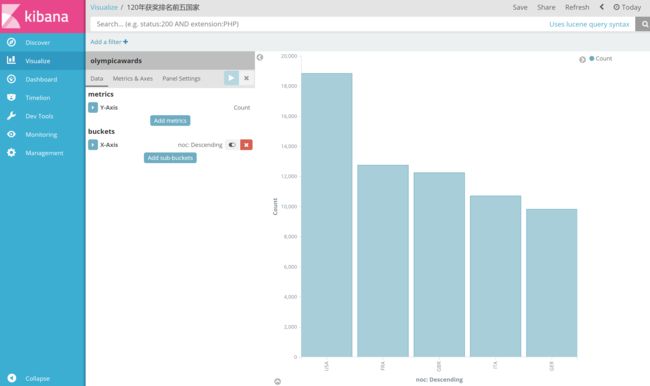
最终通过保存按钮保存起来,在构建Dashboard时候使用,
点击增加按钮,选择在Visualize保存的图表,然后通过调整位置得到自己想要的界面,最终保存下来;
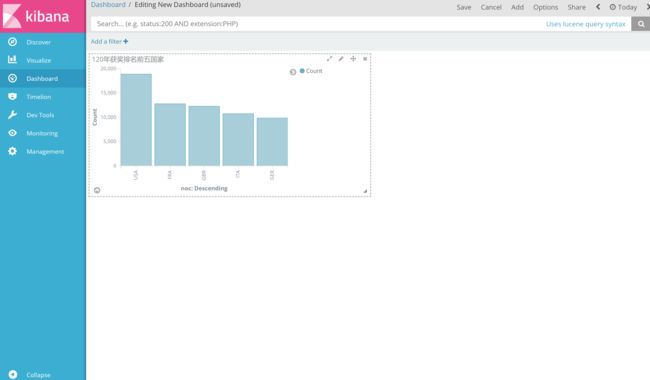
最终就完成对整个索引信息的图表化展示。
四、结束
欢迎大家加群438836709,欢迎大家关注我!
