前言
因为在做nodejs程序的性能分析的时候,了解到了Perf和FlameGraph这两个神奇的工具,接着就知道了Brendan D. Gregg这个大神,跪着拜读了他的博客和他写的System Performance。从前写程序和调优只知道从设计的思路去思考,读完大神的文章,感觉真的给自己打开了一个全新的世界。
把自己的程序看做一个黑盒,它运行的时候到底占多少内存,多少CPU?这个问题看起来不难,那么它多少时间在等待I/O,多少时间在计算,如果CPU是多核,它是否很好的平衡了负载?它访问文件系统频率多少,每次的相应时间多少?它运行中的热点是哪里,瓶颈是哪里?
再复杂点,它在运行时内存是否足够,page cache和CPU cache命中率如何?有没有导致系统发生swap等非常耗时的操作?现在如果程序运行不稳定,如何去观察定位和调优?
目前为止我还在每天跪着阅读大神的文章中,这篇笔记会按一定顺序记录我的很多理解。
Perf
Perf是一个神奇的工具,主要用于事件监测。
每当linux内核调用某一个函数时,可以视作一个事件,Perf可以记录这些事件发生的时间和内核调用栈。
基本用法
perf command [options] [execute]
举个例子:
perf stat -e sched:sched_switch -a sleep 5
统计5s之内,操作系统一共调用了多少个sched_switch。对linux熟悉的朋友应该知道这个表示进程切换。下面我的虚拟机里返回的结果
Performance counter stats for 'system wide':
1,170 sched:sched_switch
5.001593514 seconds time elapsed
也就是5秒钟之内发生了1170次进程切换。
这里解释下这个命令,perf stat是统计事件次数,-e sched:sched_switch表示统计sched:sched_switch事件,然后本来应该只统计sleep 5这个process内部的事件的,加上-a表示统计整个系统内的事件,由于sleep 5要在5s后结束,所以这个命令的实际功能就是统计了系统5s内发生的sched:sched_switch事件个数。
再举个栗子:
perf record -e block:block_rq_complete --filter 'nr_sector > 200'
block_rq_complete是块设备请求完成的事件,该条命令会统计所有涉及到200扇区以上的设备I/O事件。
命令:
perf record -e page-faults -ag
则会统计所有缺页中断。
事件列表
调用perf list (注意root权限可以看到更多)可以查看当前支持的事件列表。
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
iTLB-load-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
cycles-ct OR cpu/cycles-ct/ [Kernel PMU event]
cycles-t OR cpu/cycles-t/ [Kernel PMU event]
el-abort OR cpu/el-abort/ [Kernel PMU event]
el-capacity OR cpu/el-capacity/ [Kernel PMU event]
Perf可以监控的事件类型很多,甚至连L1 cache miss这种都可以。
Perf 命令
-
perf stat
stat命令用于简单统计次数- 统计PID进程的事件
perf stat -p PID - 统计整个系统的事件
perf stat -a sleep [seconds] - 统计command内的事件
perf stat [command]
- 统计PID进程的事件
-
perf record & report/script
stat命令只会统计事件发生次数,如果想查看更详细的信息,比如事件发生时的堆栈,就需要用到record命令了。
perf record把统计结果放到当前目录内perf.data文件,用perf report/script命令可以解析展示统计结果。- 以固定频率对程序进行抽样,并且记录堆栈
perf record -F [freq] [command] [-p PID] -g -- sleep [sec]
//-g 表示统计stack, sec表示统计时长
例如
perf record -F 99 -a -g -- sleep 2 //统计两秒内的默认事件 (cpu clock事件) perf script swapper 0 [000] 19822.660852: 10101010 cpu-clock: 7fff810665d6 native_safe_halt ([kernel.kallsyms]) 7fff8103ad7e default_idle ([kernel.kallsyms]) 7fff8103b58f arch_cpu_idle ([kernel.kallsyms]) 7fff810c5faa default_idle_call ([kernel.kallsyms]) 7fff810c6311 cpu_startup_entry ([kernel.kallsyms]) 7fff818239dc rest_init ([kernel.kallsyms]) 7fff81f5d011 start_kernel ([kernel.kallsyms]) 7fff81f5c339 x86_64_start_reservations ([kernel.kallsyms]) 7fff81f5c485 x86_64_start_kernel ([kernel.kallsyms]) swapper 0 [001] 19822.660853: 10101010 cpu-clock: 7fff810665d6 native_safe_halt ([kernel.kallsyms]) 7fff8103ad7e default_idle ([kernel.kallsyms]) 7fff8103b58f arch_cpu_idle ([kernel.kallsyms]) 7fff810c5faa default_idle_call ([kernel.kallsyms]) 7fff810c6311 cpu_startup_entry ([kernel.kallsyms]) 7fff810536e4 start_secondary ([kernel.kallsyms]) swapper 0 [001] 19822.671003: 10101010 cpu-clock: 7fff810665d6 native_safe_halt ([kernel.kallsyms]) 7fff8103ad7e default_idle ([kernel.kallsyms]) 7fff8103b58f arch_cpu_idle ([kernel.kallsyms]) 7fff810c5faa default_idle_call ([kernel.kallsyms]) 7fff810c6311 cpu_startup_entry ([kernel.kallsyms]) 7fff810536e4 start_secondary ([kernel.kallsyms]) swapper 0 [000] 19822.671003: 10101010 cpu-clock: 7fff810665d6 native_safe_halt ([kernel.kallsyms]) 7fff8103ad7e default_idle ([kernel.kallsyms]) 7fff8103b58f arch_cpu_idle ([kernel.kallsyms]) 7fff810c5faa default_idle_call ([kernel.kallsyms]) - 以固定频率对程序进行抽样,并且记录堆栈
由于我统计期间没有做任何事,所以每次时钟中断发生时,CPU都停留在native_safe_halt函数这里。
nodejs对perf的支持
由于nodejs等虚机语言通常采用了JIT技术在运行时改写函数,其堆栈符号表会在运行时变动。
为了能让perf命令监测运行过程,nodejs提供了--perf_basic_prof参数,当加上此参数运行时,node会在/tmp目录下生成perf-PID.map文件,里面给出了地址到函数名称的映射。
perf record通过-p PID抽样程序时,会自动去/tmp目录下找对应的map文件并加载。
FlameGraph
查看perf script的报告仍然不够直观,大神给出了一个工具,可以将perf统计结果转化成SVG图,并且会将相同的堆栈合并,这样可以很直观的看出来程序在那些调用上花费了大量时间。
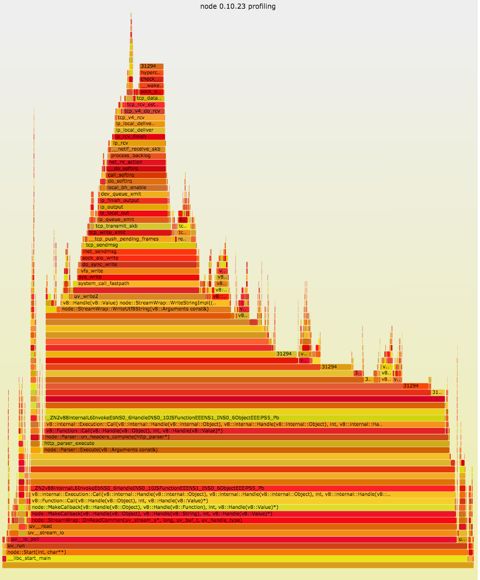
Markdown好像不支持SVG,只能截个图表示效果,实际的SVG是可以交互的了解具体细节。
这样对程序的运行过程会有非常直观的了解。
用FlameGraph调查nodejs程序内存使用
接下来是一个用FlameGraph来检查nodejs程序的例子。
- 启动nodejs程序,带上 --perf-basic-prof 选项
这里我启动了一个简单的deeplearning程序。
node --perf-basic-prof main.js &
进程ID为25586,于是node会在/tmp/目录下生成/tmp/perf-25586.map文件,其实文件内容就是地址和函数名的映射表。 - 启动perf监控程序
这里我监控所有的缺页中断程序
perf record -e kmem:mm_page_alloc -g -p 25586
监控了一段时间后就Ctrl+c断开监控,此时目录下生成了perf.data文件。 - 输出perf记录
调用perf script把结果存在一个临时文件中
perf script > node.tmp - 调用Flamegraph工具将其生成SVG热点图
stackcollapse-perf.pl node.tmp | flamegraph.pl > flamegrapsh.svg -
用浏览器打开svg就可以看到热点图了
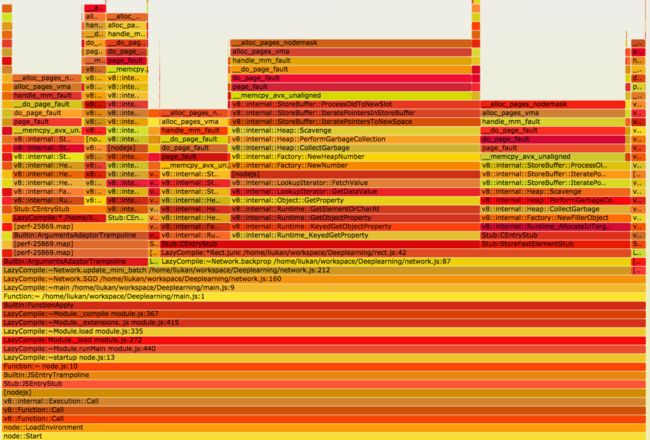 flame_graph
flame_graph
可以查看具体细节:

可以看到Rect.junc函数导致了大量的ProcessOldToNewSlot,紧接着导致了大量的缺页中断,接下来就可以调研下ProcessOldToNewSlot是什么,以及如何可以避免这种情况了。
ftrace
ftrace是linux提供的一个tracing工具,同perf一样可以监控很多系统的事件。
ftrace
Dtrace & Systemtap
==========
比起Perf,Dtrace和Systemtap更为强大,它们除了可以检测事件之外,还可以在事件发生时运行指定的命令去调查更详细的信息,比如函数参数等。
Dtrace貌似在ubuntu上的支持并不好,接下来我会花些时间去学习Systemtap。
Linux系统提供的监测工具
vmstat
vmstat提供了关于系统虚拟内存的使用统计信息。
用法是
vmstat [options] [delay [count]]
delay表示刷新频率,count表示统计次数。
重点是options
options
- a
统计active和inactive memory,正被程序引用的page为active。 - m, slabs
统计slab系统信息 - s
展示一些计数信息, - d
统计硬盘信息
vmstat 统计的信息包括
-
进程
- r
状态为RUNNABLE的进程,运行中或者等待CPU。 - b
状态为UNINTERRUPTIBLE SLEEP的进程,一般是在等待I/O操作。
- r
-
内存
- swpd
使用的swap内存 - free
空闲内存数量 - buff
被用作buffers的内存数量 - cache
被用作cache的内存数量 - inact
- active
inactive/active内存数量
- swpd
-
Swap
- si
从disk swap进来的内存数量(每秒) - so
换出到disk的内存数量(每秒)
- si
-
I/O
- bi
每秒收到的blocks数量 - bo
每秒发送出去的blocks数量
- bi
-
system
- in
每秒收到的interrupt数量,包括时钟中断 - cs
每秒的context switch数量
- in
-
cpu
这里统计的是百分比,按CPU核数平均之后的结果- us
非内核态时间占比 - sy
内核态时间占比 - id
空闲时间占比,注意这里包括了wa时间 - wa
等待I/O时间占比 - st
Time stolen from virtual machine
- us
-
Disk Mode
- Reads
total: 完成的Read总数
merged: 被merge的Read次数
sectors: 完成的Read sector数量
ms: 花费在read上的时间总数 - Writes
total: 完成的Write总数
merged: 被合并的Write次数
sectors: 完成的write扇区总数
ms: 花费在write上的时间总数 - IO
cur: 正在进行的I/O
s: 花费在I/O上的时间
- Reads
使用vmstat的时候,有几个很重要的概念需要理清楚:
- active/inactive memory
active memory指的是被某个process使用在的memory。
inactive memory指的是被曾经运行的process使用的memory - buffer/cache
有关buffer和cache的区别,我到现在还没有完全弄清楚,就目前的理解而言,buffer是供给I/O来保存传输数据块的page,而cache是用来做文件内容缓存的page。
iostat
iostat统计了系统运行的一些io数据。
iostat [options] [interval [count]]
重点仍然是options
options
- c
展示CPU统计报告 - d
展示device统计报告 - x
展示扩展统计信息(很有用) - z
忽略不活跃device
iostat展示的信息包括
- CPU报告
- %user
平均后的用户态时间占比 - %system
平均后的内核态时间占比 - %iowait
io等待时间的占比 - %idle
空闲时间占比
- %user
- Device报告
- Device:
device name - tps:
transfers per second,每秒传输请求次数 - Blk_read/s (kB_read/s, MB_read/s):
每秒读取Block数量或者数据量 - Blk_wrtn/s (kB_wrtn/s, MB_wrtn/s):
每秒写入的Block数量或者数据量 - rrqm/s:
每秒merged read request数量 - wrqm/s:
每秒merged write request数量 - r/s:
merge之后的每秒read request数量 - w/s:
merge之后的每秒write request数量 - rsec/s (rkB/s, rMB/s):
每秒读入数据量 - wsec/s (wkB/s, wMB/s):
每秒写入数据量 - avgrq-sz:
平均每个request的size,一般以sector为单位,每个sector是512字节
所以一般来说:(avgrq-sz * 0.5 * (r/s + w/s) = rkB/s + wkB/s) - avgqu-sz:
device的request queue的平均长度 - await:
平均I/O时间,从发出request到request完成 - r_await: w_await:
r/w 平均等待时间 - %util:
I/O时间占比,也就是整个系统有多少的时间是处于I/O中,当100%时,该device就接近饱和了
- Device:
mpstat
vmstat,iostat给出的都是根据CPU核数平均之后的数据,mpstat可以统计per kernel的数据。
vmstat [options] [delay [count]]
options
- A
显示每个核的统计信息 - I
显示中断统计 - u
显示CPU统计数据
一般的用法是
mpstat -p ALL [interval]
mpstat报告内容
- CPU统计信息
- CPU
CPU核序号 - %usr
- %sys
- %iowait
- %irq
CPU服务硬件中断时间占比 - %soft
CPU服务软中断占比
- CPU
uptime
uptime主要是以15,5,1分钟为单位统计了过去这段时间CPU的负荷。
free
free是查看当前内存使用量的工具,它可以查看:
- total
- used
- free
- shared
- buff/cache
- available
total = used + free + buff/cache
ps
ps命令会按进程为单位显示一些统计数据。事实上ps命令的实现就是去proc文件系统查询对应的数据。
- %CPU
- %MEM
- VSZ
virtual size - RSS
resident set size
pmap
proc文件系统
proc文件系统是linux提供的内核文件系统,在linux源码Documentation/filesystems/proc.txt里有详细介绍。
proc根目录
proc/[PID]目录
cmdline
cmdline给出了该process的运行命令。
/usr/lib/at-spi2-core/at-spi2-registryd^@--use-gnome-session^@
以^@(null)分割
cwd
指向当前工作目录的软链接
environ
环境变量,同cmdline一样是null分隔的字符串
exe
指向执行程序的软链接
fd
文件描述符目录,里面是全部file descriptor
maps
maps文件描述了程序的线性地址映射列表,看这个文件可以了解到程序当前的地址空间分布
mem
root
stat
stat文件很有意思,就是一列数字,具体的含义需要去查文档。
statm
statm提供了进程的内存统计数据,包括:
- total memory
- resident set size
- shared pages
status
status提供了很多进程的监测数据,其中比较有用的有:
- FDSize
当前的file descriptor数量 - VmSize
进程线性空间大小 - VmRss
进程实际占用物理内存大小 - VmPeak
进程线性空间大小峰值
当进程向linux系统请求一些内存空间的时候,linux系统并不会立刻给进程分配物理页面,它只是做了一个mark,增加了一下进程的线性空间(vm_area_struct),表示这个进程又多了一块可访问地址,这些值会被统计在VmSize里,因此VmSize表示进程逻辑上的内存大小。
当进程真正访问到请求的地址时,linux才会因为page fault去给进程真正分配物理page,这个实际分配的大小记录在VmRss里。同样,当进程内存不够用时,系统可能将其它进程的物理page断开然后swap到交换设备上,这时候,其它进程的VmRss是减小的,参见stackoverflow上的回答。
pagemap
meminfo
meminfo里有内存的很多信息
diskstats
diskstats文件包含了以下数据:
1 - major number
2 - minor mumber
3 - device name
4 - reads completed successfully
5 - reads merged
6 - sectors read
7 - time spent reading (ms)
8 - writes completed
9 - writes merged
10 - sectors written
11 - time spent writing (ms)
12 - I/Os currently in progress
13 - time spent doing I/Os (ms)
14 - weighted time spent doing I/Os (ms)
根据这些数据可以猜想iostat没准就是通过/proc/diskstats文件来计算监测数据的,strace iostat果然证明了这个猜想
loadavg
看名字也能看出来大概是说啥了
性能分析方法:
CPU
CPU分析太细级别的不一定有特别大的意义,统计工具有:
uptime
观察CPU load average = number of [runnable, uninterruptable] processesvmstat
vmstat提供了user,system以及id的时间比率,以及r(run queue)的长度mpstat
mpstat -P ALL可以观测每一个CPU核的统计数据,如果很不均匀,可以考虑多线程来提高CPU利用率pidstat
pidstat根据CPU或者进程来统计使用情况。-
time
/usr/bin/time,注意不是直接的time,加上-v可以显示一个程序的统计信息。包括- Majo (I/O) page faults
- Minor (reclaiming a frame) page faults
- Swaps
要理解上述参数可以参阅, Minor page faults表示程序访问了可以复用的page,而Major page faults表示程序访问了需要通过I/O调入的page。
一个简单的实验就是调用两次/usr/bin/time -v firefox,第一次调用启动时间较长,400多个major page faults, 35481个minor,第二次调用就快多了,而且是0个major page faults, 34434个minor。因为linux page cache系统缓存了firefox的执行文件内容。 htop
htop也是一个实时监测工具,可以用来初步判断问题所在。-
getdelay.c
linux源代码里Document目录下有一个getdelay.c,编译后可以通过-p PID的方式来读取某一个程序的delay信息,包括:- Scheduler Latency
进程花了多少时间等待CPU调度 - Block I/O
进程花了多少时间等待I/O完成 - Swapping
进程花了多少时间等待页面调入 - Memory reclaim
进程花了多少时间等待cache页面分配
- Scheduler Latency
profiling
通过perf,systemtap等profiling工具,可以查看CPU热点,分析CPU耗费在哪里。
perf sched还可以统计scheduler latency,也就是进程切换导致的延时。(这个值我现在读的有点疑问)
B神提到user:system CPU时间比反应了这个程序的类型,高user time说明是计算密集型。
在B神的业务服务器上(IO密集型,大概100K syscall每秒),一般负载系数在2到8(线程数/cpu核数),user/system时间比大概是60/40。
Memory
Memory监测一般是跟使用语言绑定,不过也有一些从系统层级观测memory使用情况的工具。
概念
了解Memory工具前最好先了解linux系统里的几个概念:
- Main Memory
也就是物理内存 - Virtual Memory
进程所看到的线性地址内存 - Resident Memory
有实际物理内存对应的virtual memory - Anonymous Memory
没有文件系统page对应的内存,一般就是进程的数据部分,包括stack和heap - Paging
主存和存储设备之间的page转移 - Anonymous Paging
Anonymous Paging意味着把进程的stack或者heap swap出去,当再次运行的时候又会需要把它们从磁盘上读回来,这是非常hurting的现象 - Page States
- Unallocated
- Allocated, unmapped
- Allocated, mapped to main memory
- Allocated, mapped to swap device
- Linux Page System
当一个page request来的时候,linux按照以下顺序分配内存page- Free List
free page列表 - Page Cache
从文件系统用作cache的page中分配 - Swapping
kswapd系统线程通过swap一些page出去来腾出空间 - OOM Killer
杀死一些进程来空出空间 - Page回收
Linux将page分为以下几类:- 不可回收页:
空闲页,保留页(PG_reserved),内核分配页,进程内核态堆栈页,临时锁定页(PG_locked) - 可交换页
用户态anonymous页(堆栈,堆),回收时将内容保存到交换区 - 可同步页
用户态地址空间(映射文件),有对应磁盘文件页,回收时需要做同步操作
- 不可回收页:
- Free List
检测工具及方法
- vmstat
- swpd
总共swap出去的memory - free
当前free memory - si, so
swapped in swapped out memory,这两个值反应了系统memory压力
- swpd
- slabtop
slabtop可以了解linux kernel slab系统的内存使用情况 - Systemtap, perf
这些tracer可以监控系统事件了解内存使用情况
File System
同样,首先需要大致了解一些File system的概念
File system
-
Page Cache
Linux使用统一的Page Cache系统来做磁盘和块设备的Cache。Page Cache中的page内包含的内容可能有:- 普通文件的内容,page cache通过文件inode中的address_space结构对应起来
- 目录内容,linux像处理普通文件一样处理目录文件
- 从块设备直接读出的内容(绕过文件系统)
- 用户process被swap out的内容,虽然被swap out,但是有些内容会被先cache起来
- 特殊的文件系统文件,比如shm文件系统
-
Linux系统是如何读取一个文件的(非Direct I/O, Memory Mapping, Asynchronous)
- read调用,最后到generic_file_read(filep, buf, count, ppos),参数分别表示文件句柄,存放内容的数组,读取内容数量和起始偏移量。
- generic_file_read初始化一个iovec,存放buf和count和一个kiocb,用来控制I/O过程,然后call __generic_file_aio_read:
- 检查缓冲区有效
- 建立一个read_descriptor_t,表示读取操作状态
- do_generic_file_read(filp, ppos, read_descriptor_t, &file_read_actor)
- do_generic_file_read会执行实际的拷贝,过程如下:
- 取得filep->f_mapping,address_space对象
- 将文件看过页数组,算出起止序号
- 循环读入页,(read_page方法):
* 处理预读页 * 在页缓存中寻找页,找不到则申请空白页 * 在页缓存中找到页的话,读取结束 * 调用address_space->readpage方法读取数据到页缓存 * 调用file_read_actor把数据拷贝到用户缓存- 修改文件inode的update_atime,mark this inode dirty
read_page方法:
普通文件read_page: 首先计算文件在磁盘上的块号,如果是连续的,发出一个block I/O请求,否则用一次一块的方法读取。
块设备文件read_page: 将page看做块缓冲区,逐块读取。
-
Linux系统如何写入一个文件
- generic_file_write(filep, buf, count, ppos)
- 获取文件inode->i_sem信号量用以控制同步写入
- 创建kiocb, iovec,调用__generic_file_aio_write_block:
- 首先在page cache中搜索对应页
- 如果没有对应页,新建一个页框,调用address_space->prepare_write
- 拷贝写入内容到页中,调用address_space->commit_write,标记页dirty
- 释放inode->i_sem
- 如果需要sync,调用address_space的writepages方法
- 到这一步,write操作已经返回了。标记为dirty的page最终写到磁盘上,则是延迟执行的,调用address_space->writepages方法
内存映射mmap
内存映射简单的说,就是直接把文件内容读入page cache,并通过修改进程的mm_struct中的vm_area_struct来让一部分线性空间指向page cache中的page的物理地址。这样进程如果只需要读取,就相对read调用少了一次往user buffer里拷贝的过程,但如果进程要把数据复制出来的话,其实跟直接调用read区别不大。
同样,文件内容读取也是延后的,直到进程访问地址产生page fault时,操作系统才会去读入文件内容到对应page frame。
所以修改内存数据会直接修改page cache中的page内容,导致page为dirty,操作系统之后会将脏page写入磁盘,更新本地文件。Direct I/O
Linux还提供一个Direct I/O,数据直接从设备传递到用户空间,绕过文件缓存系统,好处是少了一次数据从系统内核到用户空间的拷贝。坏处是用户空间的页将会被锁定不能换出,这是与linux系统内存使用理念相悖的。
检测工具
Network
- netstat -s
- netstat -i
- tcpdump
- stap/perf