简介
airflow是airbnb家的基于DAG(有向无环图)的任务管理系统, 最简单的理解就是一个高级版的crontab。它解决了crontab无法解决的任务依赖问题。
类似产品比较
| 系统 | 介绍 |
|---|---|
| Apache Oozie | 使用XML配置, Oozie任务的资源文件都必须存放在HDFS上. 配置不方便同时也只能用于Hadoop. |
| Linkedin Azkaban | web界面尤其很赞, 使用java properties文件维护任务依赖关系, 任务资源文件需要打包成zip, 部署不是很方便. |
| airflow | 具有自己的web任务管理界面,dag任务创建通过python代码,可以保证其灵活性和适应性 |
web界面使用介绍
DAGS
启动web任务管理需要执行airflow websever -D命令,默认端口是8080
http://10.191.76.31:8080/admin/
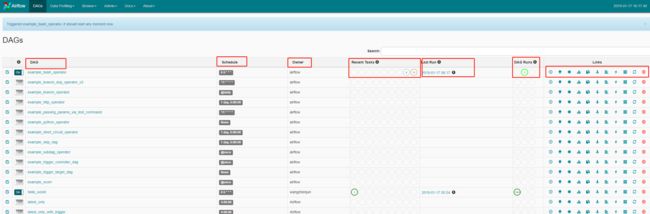
- DAG
dag_id - Schedule
调度时间 - Owner
dag拥有者 - Recent Tasks
这里包含9个圆圈,每个圆圈代表task的执行状态和次数
圈1 success:现实成功的task数,基本上就是该tag包含多少个task,这里基本上就显示几。
圈2 running:正在运行的task数
圈3 failed:失败的task数
圈4 unstream_failed:
圈5 skipped:跳过的task数
圈6 up_for_retry:执行失败的task,重新执行的task数
圈7 queued:队列,等待执行的task数
圈8 :
圈9 scheduled:刚开始调度dag时,这一次执行总共调度了dag下面多少个task数,并且随着task的执行成功,数值逐渐减少。 - Last Run
dag最后执行的时间点 - DAG Runs
这里显示dag的执行信息,包括3个圆圈,每个圆圈代表dag的执行状态和次数
圈1 success:总共执行成功的dag数,执行次数
圈2 runing:正在执行dag数
圈3 faild:执行失败的dag数 - Links
| link | 说明 |
|---|---|
| Trigger Dag | 人为执行触发 |
| Tree View | 当dag执行的时候,可以点入,查看每个task的执行状态(基于树状视图),状态:success,running,failed,skipped,retry,queued,no status |
| Graph View | 同上,基于图视图(有向无环图),查看每个task的执行状态,状态:success,running,failed,skipped,retry,queued,no status |
| Tasks Duration | 每个task的执行时间统计,可以选择最近多少次执行(number of runs) |
| Task Tries | 每个task的重试次数 |
| Landing Times | |
| Gantt View | 基于甘特图的视图,每个task的执行状态 |
- Code View
查看任务执行代码 - Logs
查看执行日志,比如失败原因 - Refresh
刷新dag任务
-Delete Dag
删除该dag任务
当某dag执行失败,可以通过3个View视图去查看是哪个task执行失败。
Data Profiling 数据分析

-
Ad Hoc Query:特殊查询
通过UI界面对一些数据库,数据仓库的进行简单的SQL交互操作.
 Ad Hoc Query
Ad Hoc Query
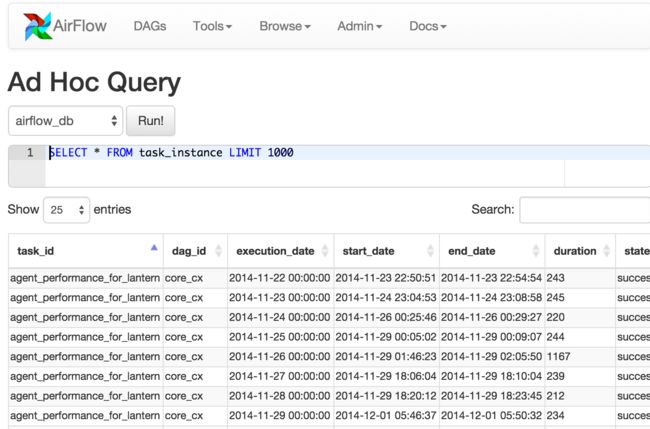 image.png
image.png Charts:图表
实现数据可视化和图表的工作。通过SQL去源数据库检索一些数据,保存下来,供后续使用。
These charts are basic, but they’re easy to create, modify and share

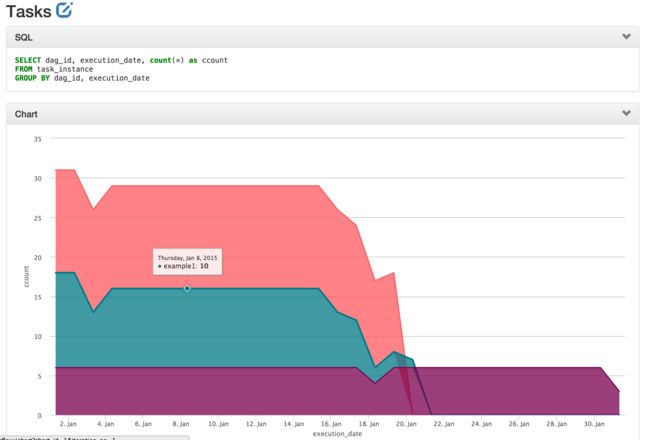
You can even use the same templating and macros available when writing airflow pipelines, parameterizing your queries and modifying parameters directly in the URL.

-
Known Events:已知的事件
 Known Events
Known Events
Browse 浏览
SLA Misses
-
Task Instances:查看每个task实例执行情况
 Task Instances
Task Instances -
Logs:查看所有dag下面对应的task的日志,并且包含检索
 image.png
image.png -
Jobs:查看dag的执行状态,开始时间和结束时间等指标
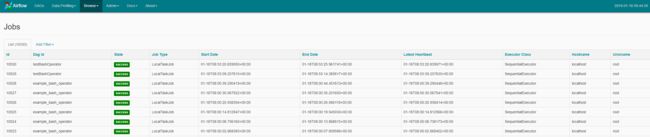 image.png
image.png DAG Runs
Admin:管理员
Pools:
Configuration:查看airflow的配置,即:./airflow_home/airflow.cfg
Users:查看用户列表,创建用户,删除用户
Connections
我们的Task需要通过Hook访问其他资源, Hook仅仅是一种访问方式, 就像是JDBC driver一样, 要连接DB, 我们还需要DB的IP/Port/User/Pwd等信息. 这些信息不太适合hard code在每个task中, 可以把它们定义成Connection, airflow将这些connection信息存放在后台的connection表中. 我们可以在WebUI的Admin->Connections管理这些连接.Variables
Variable 没有task_id/dag_id属性, 往往用来定义一些系统级的常量或变量, 我们可以在WebUI或代码中新建/更新/删除Variable. 也可以在WebUI上维护变量.
Variable 的另一个重要的用途是, 我们为Prod/Dev环境做不同的设置, 详见后面的开发小节.XComs
XCom和Variable类似, 用于Task之间共享一些信息. XCom 包含task_id/dag_id属性, 适合于Task之间传递数据, XCom使用方法比Variables复杂些. 比如有一个dag, 两个task组成(T1->T2), 可以在T1中使用xcom_push()来推送一个kv, 在T2中使用xcom_pull()来获取这个kv.
Docs

- 官方文档
- Github地址
Dag提交-python配置任务
- DAG 基本参数配置
default_args = {
'owner': 'airflow',
'depends_on_past': False, # 是否依赖上一个自己的执行状态
'start_date': datetime.datetime(2019, 1, 1),
'email': ['[email protected]'], # 需要在airflow.cfg中配置下发件邮箱
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
# 'end_date': datetime(2020, 1, 1), # 结束时间,注释掉也就会一直执行下去
}
- DAG对象
设置dag的执行周期:schedule_interval.该参数可以接收cron 表达式和datetime.timedelta对象,另外airflow还预置了一些调度周期。
| preset | Description | cron |
|---|---|---|
| None | Don’t schedule, use for exclusively “externally triggered” DAGs | |
| @once | Schedule once and only once | |
| @hourly | Run once an hour at the beginning of the hour | 0 * * * * |
| @daily | Run once a day at midnight | 0 0 * * * |
| @weekly | Run once a week at midnight on Sunday morning | 0 0 * * 0 |
| @monthly | Run once a month at midnight of the first day of the month | 0 0 1 * * |
| @yearly | Run once a year at midnight of January 1 | 0 0 1 1 * |
dag = DAG(
'tutorial',
default_args=default_args,
schedule_interval='* * * * *' # 执行周期,crontab形式
)
- 定义任务
在定义这个任务的过程,就像是在写一个 shell 脚本,只是这个脚本的每个操作可以有依赖。 不同的操作对应了不同的 Operator,比如 shell 就需要用 BashOperator 来执行。
t1 = BashOperator( #任务类型是bash
task_id='echoDate', #任务id
bash_command='echo date > /home/datefile', #任务命令
dag=dag)
- 完整样例
# coding: utf-8
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# 定义默认参数
default_args = {
'owner': 'wangzhenjun', # 拥有者名称
'depends_on_past': False, # 是否依赖上一个自己的执行状态
'start_date': datetime(2019, 1, 15, 10, 00), # 第一次开始执行的时间,为格林威治时间,为了方便测试,一般设置为当前时间减去执行周期
'email': ['[email protected]'], # 接收通知的email列表
'email_on_failure': True, # 是否在任务执行失败时接收邮件
'email_on_retry': True, # 是否在任务重试时接收邮件
'retries': 3, # 失败重试次数
'retry_delay': timedelta(seconds=5) # 失败重试间隔
}
# 定义DAG
dag = DAG(
dag_id='hello_world', # dag_id
default_args=default_args, # 指定默认参数
# schedule_interval="00, *, *, *, *" # 执行周期,依次是分,时,天,月,年,此处表示每个整点执行
schedule_interval=timedelta(minutes=1) # 执行周期,表示每分钟执行一次
)
"""
1.通过PythonOperator定义执行python函数的任务
"""
# 定义要执行的Python函数1
def hello_world_1():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_1.txt', 'a') as f:
f.write('%s\n' % current_time)
assert 1 == 1 # 可以在函数中使用assert断言来判断执行是否正常,也可以直接抛出异常
# 定义要执行的Python函数2
def hello_world_2():
current_time = str(datetime.today())
with open('/root/tmp/hello_world_2.txt', 'a') as f:
f.write('%s\n' % current_time)
# 定义要执行的task 1
t1 = PythonOperator(
task_id='hello_world_1', # task_id
python_callable=hello_world_1, # 指定要执行的函数
dag=dag, # 指定归属的dag
retries=2, # 重写失败重试次数,如果不写,则默认使用dag类中指定的default_args中的设置
)
# 定义要执行的task 2
t2 = PythonOperator(
task_id='hello_world_2', # task_id
python_callable=hello_world_2, # 指定要执行的函数
dag=dag, # 指定归属的dag
)
t2.set_upstream(t1) # t2依赖于t1;等价于 t1.set_downstream(t2);同时等价于 dag.set_dependency('hello_world_1', 'hello_world_2')
# 表示t2这个任务只有在t1这个任务执行成功时才执行,
# 或者
t1 >> t2
"""
2.通过BashOperator定义执行bash命令的任务
"""
hello_operator = BashOperator( #通过BashOperator定义执行bash命令的任务
task_id='sleep_task',
depends_on_past=False,
bash_command='echo `date` >> /home/py/test.txt',
dag=dag
)
"""
其他任务处理器:
3.EmailOperator : 发送邮件
4.HTTPOperator : 发送 HTTP 请求
5.SqlOperator : 执行 SQL 命令
"""
分布式部署
CeleryExecutor is one of the ways you can scale out the number of workers. For this to work, you need to setup a Celery backend (RabbitMQ, Redis, …) and change your airflow.cfg to point the executor parameter to CeleryExecutor and provide the related Celery settings.
我们的生产环境:
每台机器运行的任务所属应用各不相同,不同应用运行环境也不相同,另外不同应用也希望达到集群隔离的目的。如果要实现这个功能,需要自己提供队列的管理,指定队列的任务节点会被调度到相应队列的机器上,相应队列的机器也只会运行指定队列的任务节点。
大部分都是集中在2-3台机器提交,环境类似,各自提交任务,但是任务通过主节点去随机分发到各结点执行,并不能保证环境的满足。
现在情况:如果是组内使用,各位的环境差异比较大,首先需要保证各环境的统一性
面临的问题:
- 官方文档+网上的关于分布式的资料不多,官方文档更多是一笔带过。

