Flink初体验
安装
官网:http://flink.apache.org/downloads.html
可以看到flink Last stable release是1.4..0
看下根据安装的hadoop版本下载对应的flink版本,由于我安装的hadoop是2.7.2的,所以选择下图进行安装。
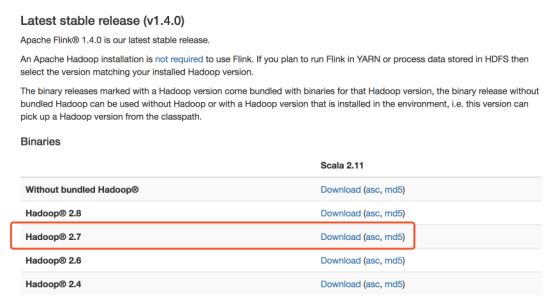
执行wget命令下载flink:
➜ wget http://mirror.bit.edu.cn/apache/flink/flink-1.4.0/flink-1.4.0-bin-hadoop27-scala_2.11.tgz
配置Flink_home环境变量:

查看配置的环境变量
➜ bin more ~/.bash_profile
#maven
export M2_HOME=/Users/zzy/Downloads/apache-maven-3.5.0
export PATH=$PATH:$M2_HOME/bin
#java1.8
JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
#java1.7
JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.7.0_79.jdk/Contents/Home
CLASSPAHT=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH:
export JAVA_HOME
export CLASSPATH
export PATH
#hadoop
export HADOOP_HOME=/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
#pig
export PIG_HOME=/Users/zzy/Documents/zzy/software/bigdata/pig-0.16.0
export PATH=$PATH:$PIG_HOME/bin
#scala
export SCALA_HOME=/Users/zzy/Documents/zzy/software/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
#flink
export FLINK_HOME=/Users/zzy/Documents/zzy/software/flink-1.4.0
export PATH=$PATH:$FLINK_HOME/bin
#mysql alias
alias mysql='/usr/local/mysql/bin/mysql'
alias mysqladmin='/usr/local/mysql/bin/mysqladmin'
#git
export GIT_HOME=/usr/local/bin
export PATH=$PATH:$GIT_HOME/git
#ES
export ELASTICSEARCH_HOME=/Users/zzy/Documents/zzy/software/bigdata/elasticsearch-5.5.2
export PATH=$PATH:$ELASTICSEARCH_HOME/bin
#kibana
export KIBANA_HOME=/Users/zzy/Documents/zzy/software/bigdata/kibana-5.5.2-darwin-x86_64
export PATH=$PATH:$KIBANA/bin
#added by Anaconda2 4.4.0 installer
export PATH="/Users/zzy/anaconda/bin:$PATH"
可以看到flink-1.4.0要求scala是2.11的所以要安装2.11的scala
到scala官网安装即可。
配置scala_home:

QuickStart:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/quickstart/setup_quickstart.html
Start a Local Flink Cluster
$ ./bin/start-local.sh # Start Flink
Check the **JobManager’s web frontend**at [http://localhost:8081](http://localhost:8081) and make sure everything is up and running. The web frontend should report a single available TaskManager instance.
看到启动的进程有:
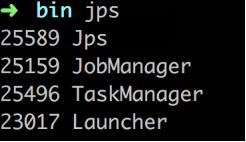
➜ bin ps -ef |grep 25159
501 25159 1 0 11:27上午 ttys007 0:14.66 /Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home/bin/java -Xms1024m -Xmx1024m -Dlog.file=/Users/zzy/Documents/zzy/software/flink-1.4.0/log/flink-zzy-jobmanager-0-zzydeMBP.log -Dlog4j.configuration=file:/Users/zzy/Documents/zzy/software/flink-1.4.0/conf/log4j.properties -Dlogback.configurationFile=file:/Users/zzy/Documents/zzy/software/flink-1.4.0/conf/logback.xml -classpath /Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-python_2.11-1.4.0.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-shaded-hadoop2-uber-1.4.0.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/log4j-1.2.17.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/slf4j-log4j12-1.7.7.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-dist_2.11-1.4.0.jar::/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop::/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/contrib/capacity-scheduler/*.jar org.apache.flink.runtime.jobmanager.JobManager --configDir /Users/zzy/Documents/zzy/software/flink-1.4.0/conf --executionMode cluster
501 25596 16218 0 11:40上午 ttys007 0:00.00 grep --color=auto 25159
➜ bin ps -ef |grep 25496
501 25496 1 0 11:27上午 ttys007 0:13.58 /Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home/bin/java -XX:+UseG1GC -Xms1024M -Xmx1024M -XX:MaxDirectMemorySize=8388607T -Dlog.file=/Users/zzy/Documents/zzy/software/flink-1.4.0/log/flink-zzy-taskmanager-0-zzydeMBP.log -Dlog4j.configuration=file:/Users/zzy/Documents/zzy/software/flink-1.4.0/conf/log4j.properties -Dlogback.configurationFile=file:/Users/zzy/Documents/zzy/software/flink-1.4.0/conf/logback.xml -classpath /Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-python_2.11-1.4.0.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-shaded-hadoop2-uber-1.4.0.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/log4j-1.2.17.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/slf4j-log4j12-1.7.7.jar:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/flink-dist_2.11-1.4.0.jar::/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop::/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/contrib/capacity-scheduler/*.jar org.apache.flink.runtime.taskmanager.TaskManager --configDir /Users/zzy/Documents/zzy/software/flink-1.4.0/conf
501 25603 16218 0 11:40上午 ttys007 0:00.00 grep --color=auto 25496
启动日志:
➜ log ll
total 144
-rw-r--r-- 1 zzy staff 27935 1 9 11:27 flink-zzy-jobmanager-0-zzydeMBP.log
-rw-r--r-- 1 zzy staff 532 1 9 11:27 flink-zzy-jobmanager-0-zzydeMBP.out
-rw-r--r-- 1 zzy staff 33783 1 9 11:27 flink-zzy-taskmanager-0-zzydeMBP.log
-rw-r--r-- 1 zzy staff 532 1 9 11:27 flink-zzy-taskmanager-0-zzydeMBP.out
➜ log tail flink-zzy-jobmanager-0-zzydeMBP.log
2018-01-09 11:27:26,252 INFO org.apache.flink.runtime.jobmanager.JobManager - Starting JobManager actor
2018-01-09 11:27:26,258 INFO org.apache.flink.runtime.blob.BlobServer - Created BLOB server storage directory /var/folders/3x/csj5l35n7pl73rr_m94nwfzm0000gn/T/blobStore-4bef70e0-90fe-4372-849b-23c71255c92a
2018-01-09 11:27:26,259 INFO org.apache.flink.runtime.blob.BlobServer - Started BLOB server at 0.0.0.0:56665 - max concurrent requests: 50 - max backlog: 1000
2018-01-09 11:27:26,345 INFO org.apache.flink.runtime.jobmanager.MemoryArchivist - Started memory archivist akka://flink/user/archive
2018-01-09 11:27:26,346 INFO org.apache.flink.runtime.jobmanager.JobManager - Starting JobManager at akka.tcp://flink@localhost:6123/user/jobmanager.
2018-01-09 11:27:26,357 INFO org.apache.flink.runtime.jobmanager.JobManager - JobManager akka.tcp://flink@localhost:6123/user/jobmanager was granted leadership with leader session ID Some(00000000-0000-0000-0000-000000000000).
2018-01-09 11:27:26,369 INFO org.apache.flink.runtime.clusterframework.standalone.StandaloneResourceManager - Trying to associate with JobManager leader akka.tcp://flink@localhost:6123/user/jobmanager
2018-01-09 11:27:26,375 INFO org.apache.flink.runtime.clusterframework.standalone.StandaloneResourceManager - Resource Manager associating with leading JobManager Actor[akka://flink/user/jobmanager#2017012179] - leader session 00000000-0000-0000-0000-000000000000
2018-01-09 11:27:27,695 INFO org.apache.flink.runtime.clusterframework.standalone.StandaloneResourceManager - TaskManager 062219ce0d130bd05ad322f1a584c7de has started.
2018-01-09 11:27:27,707 INFO org.apache.flink.runtime.instance.InstanceManager - Registered TaskManager at zzydembp (akka.tcp://flink@zzydembp:56667/user/taskmanager) as 164d7b2a6f48f6fc278ac43e15a28d20. Current number of registered hosts is 1. Current number of alive task slots is 1.
➜ log tail flink-zzy-taskmanager-0-zzydeMBP.log
2018-01-09 11:27:27,494 INFO org.apache.flink.runtime.filecache.FileCache - User file cache uses directory /var/folders/3x/csj5l35n7pl73rr_m94nwfzm0000gn/T/flink-dist-cache-94e5fe4a-f4af-416c-9b38-9cb16e321c09
2018-01-09 11:27:27,504 INFO org.apache.flink.runtime.taskmanager.TaskManager - Starting TaskManager actor at akka://flink/user/taskmanager#-266437785.
2018-01-09 11:27:27,504 INFO org.apache.flink.runtime.taskmanager.TaskManager - TaskManager data connection information: 062219ce0d130bd05ad322f1a584c7de @ zzydembp (dataPort=56668)
2018-01-09 11:27:27,504 INFO org.apache.flink.runtime.taskmanager.TaskManager - TaskManager has 1 task slot(s).
2018-01-09 11:27:27,506 INFO org.apache.flink.runtime.taskmanager.TaskManager - Memory usage stats: [HEAP: 111/1024/1024 MB, NON HEAP: 35/36/-1 MB (used/committed/max)]
2018-01-09 11:27:27,513 INFO org.apache.flink.runtime.taskmanager.TaskManager - Trying to register at JobManager akka.tcp://flink@localhost:6123/user/jobmanager (attempt 1, timeout: 500 milliseconds)
2018-01-09 11:27:27,735 INFO org.apache.flink.runtime.taskmanager.TaskManager - Successful registration at JobManager (akka.tcp://flink@localhost:6123/user/jobmanager), starting network stack and library cache.
2018-01-09 11:27:27,741 INFO org.apache.flink.runtime.taskmanager.TaskManager - Determined BLOB server address to be localhost/127.0.0.1:56665. Starting BLOB cache.
2018-01-09 11:27:27,745 INFO org.apache.flink.runtime.blob.PermanentBlobCache - Created BLOB cache storage directory /var/folders/3x/csj5l35n7pl73rr_m94nwfzm0000gn/T/blobStore-610b6734-e828-4232-b69a-a489e7737580
2018-01-09 11:27:27,749 INFO org.apache.flink.runtime.blob.TransientBlobCache - Created BLOB cache storage directory /var/folders/3x/csj5l35n7pl73rr_m94nwfzm0000gn/T/blobStore-94f069a9-43d2-47de-9947-aefef5604339
➜ log
Demo01
- 1.在maven中添加flink相关依赖:
http://flink.apache.org/downloads.html
org.apache.flink
flink-java
1.4.0
org.apache.flink
flink-streaming-java_2.11
1.4.0
org.apache.flink
flink-clients_2.11
1.4.0
运行官网的例子
- First of all, we use netcat to start local server via
$ nc -l 9000
- Submit the Flink program:
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
- 日志如下:
➜ flink-1.4.0 ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/contrib/capacity-scheduler/*.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/slf4j-log4j12-1.7.7.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Cluster configuration: Standalone cluster with JobManager at localhost/127.0.0.1:6123
Using address localhost:6123 to connect to JobManager.
JobManager web interface address http://localhost:8081
Starting execution of program
Submitting job with JobID: 0e40acff6c8a90508fb640d6643e4e58. Waiting for job completion.
Connected to JobManager at Actor[akka.tcp://flink@localhost:6123/user/jobmanager#2017012179] with leader session id 00000000-0000-0000-0000-000000000000.
01/09/2018 11:56:21 Job execution switched to status RUNNING.
01/09/2018 11:56:21 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED
01/09/2018 11:56:21 TriggerWindow(TumblingProcessingTimeWindows(5000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@5004a829, reduceFunction=org.apache.flink.streaming.examples.socket.SocketWindowWordCount$1@4d518b32}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to SCHEDULED
01/09/2018 11:56:21 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING
01/09/2018 11:56:21 TriggerWindow(TumblingProcessingTimeWindows(5000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@5004a829, reduceFunction=org.apache.flink.streaming.examples.socket.SocketWindowWordCount$1@4d518b32}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to DEPLOYING
01/09/2018 11:56:22 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING
01/09/2018 11:56:22 TriggerWindow(TumblingProcessingTimeWindows(5000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@5004a829, reduceFunction=org.apache.flink.streaming.examples.socket.SocketWindowWordCount$1@4d518b32}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to RUNNING
查看8081端口,可以看到有一个Running job里有一个job在运行
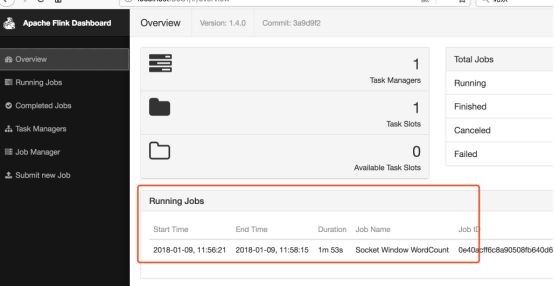
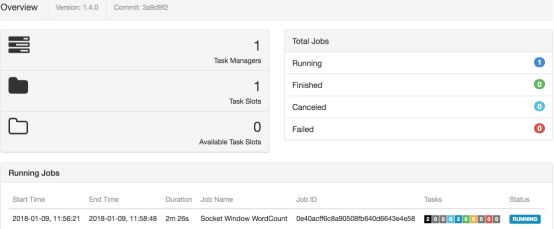
Flink提交任务的方式
抛砖引玉:
在Spark集群提交作业时候可以使用--deploy参数指定client或者cluster方式提交作业到集群,前者是客户端模式,后者是集群模式,两者主要区别就是Driver的运行位置,在客户端模式下,Driver运行在提交作业的客户端机器上负责与集群进行资源申请调度等工作。而集群模式下Driver运行在集群中的某一个节点上负责资源申请以及调度。
一般的,客户端模式适合程序的调试,这种模式下,程序中的print等类似控制台打印方法可以在提交作业的控制台打印输出,后者由于Driver运行在集群中的某一节点上,所以不会将打印信息在提交的客户端上进行打印。spark默认提交方式是客户端方式Flink的提交作业方式:
https://www.2cto.com/net/201706/644062.html
flink同样支持两种提交方式,默认不指定就是客户端方式。如果需要使用集群方式提交的话。可以在提交作业的命令行中指定-d或者--detached 进行进群模式提交。
-d,--detached If present, runs the job indetached mode(分离模式)
客户端提交方式:FLINK_HOME/bin/flink run -d -c com.daxin.batch.App flinkwordcount.jar 程序提交完毕退出客户端,不在打印作业进度等信息!
./bin/flink run -c cn.com.xxx.zzy.SocketWindowWordCount ./lib_code/flink_learn-1.0-SNAPSHOT.jar --port 9000
打印日志如下:
➜ flink-1.4.0 ./bin/flink run -c cn.com.xxx.zzy.SocketWordCount ./lib_code/flink_learn-1.0-SNAPSHOT.jar --port 9000
Using the result of 'hadoop classpath' to augment the Hadoop classpath: /Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/etc/hadoop:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/hdfs/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/yarn/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/lib/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/mapreduce/*:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/contrib/capacity-scheduler/*.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/zzy/Documents/zzy/software/flink-1.4.0/lib/slf4j-log4j12-1.7.7.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/zzy/Documents/zzy/software/bigdata/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Cluster configuration: Standalone cluster with JobManager at localhost/127.0.0.1:6123
Using address localhost:6123 to connect to JobManager.
JobManager web interface address http://localhost:8081
Starting execution of program
Submitting job with JobID: c49b234b0e32d093ba0c93de53e18345. Waiting for job completion.
Connected to JobManager at Actor[akka.tcp://flink@localhost:6123/user/jobmanager#-1717984141] with leader session id 00000000-0000-0000-0000-000000000000.
01/10/2018 12:49:02 Job execution switched to status RUNNING.
01/10/2018 12:49:02 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED
01/10/2018 12:49:02 TriggerWindow(SlidingProcessingTimeWindows(5000, 1000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@90a81510, reduceFunction=cn.com.xxx.zzy.SocketWordCount$1@4c012563}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to SCHEDULED
01/10/2018 12:49:02 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING
01/10/2018 12:49:02 TriggerWindow(SlidingProcessingTimeWindows(5000, 1000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@90a81510, reduceFunction=cn.com.xxx.zzy.SocketWordCount$1@4c012563}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to DEPLOYING
01/10/2018 12:49:03 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING
01/10/2018 12:49:03 TriggerWindow(SlidingProcessingTimeWindows(5000, 1000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@90a81510, reduceFunction=cn.com.xxx.zzy.SocketWordCount$1@4c012563}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241)) -> Sink: Unnamed(1/1) switched to RUNNING
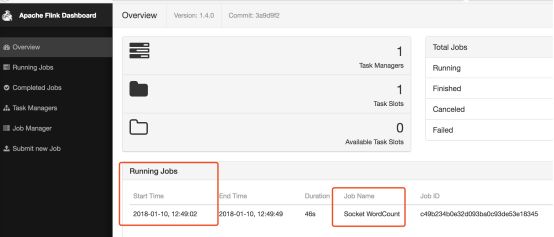
在flink界面可以看到多了一个Running的job
http://localhost:8081/#/overview

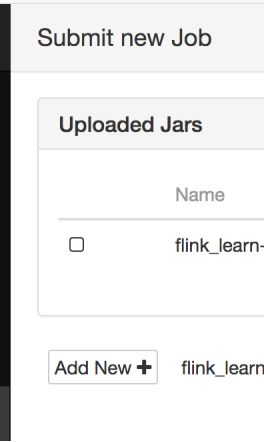
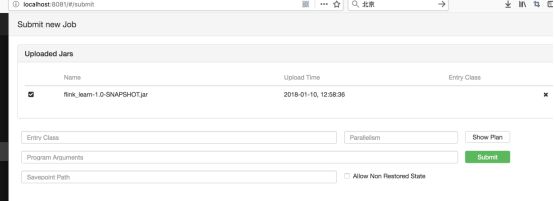
可以通过add jar的方式来Run一个job
flink结果:
Words are counted in time windows of 5 seconds (processing time, tumbling windows) and are printed to stdout. Monitor the TaskManager’s output file and write some text in nc (input is sent to Flink line by line after hitting ):
$ nc -l 9000
lorem ipsum
ipsum ipsum ipsum
bye
The .out file will print the counts at the end of each time window as long as words are floating in, e.g.:
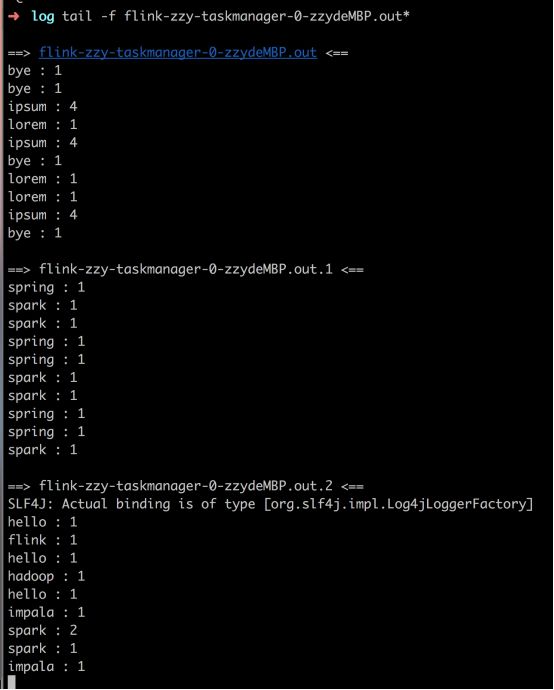
$ tail -f log/flink-*-taskmanager-*.out
lorem : 1
bye : 1
ipsum : 4
结果存到.out文件中了(flink的结果没有直接打印在终端上)
附上代码:
package cn.com.xxx.zzy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Created with IntelliJ IDEA.
* To change this template use File | Settings | File Templates.
*/
public class SocketWordCount {
public static void main(String[] args) throws Exception {
// the port to connect to
final int port;
try {
final ParameterTool params = ParameterTool.fromArgs(args);
port = params.getInt("port");
} catch (Exception e) {
System.err.println("No port specified. Please run 'SocketWordCount --port '");
return;
}
// get the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data by connecting to the socket
DataStream text = env.socketTextStream("localhost", port, "\n");
// parse the data, group it, window it, and aggregate the counts
DataStream windowCounts = text
.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out) {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
})
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.reduce(new ReduceFunction() {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) {
return new WordWithCount(a.word, a.count + b.count);
}
});
// print the results with a single thread, rather than in parallel
windowCounts.print().setParallelism(1);
env.execute("Socket WordCount");
}
// Data type for words with count
public static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
参考:
[https://www.2cto.com/net/201706/644062.html]
flink官网