本文为 Apache Flink 新版本重大功能特性解读之 Flink SQL 系列文章的开篇,Flink SQL 系列文章由其核心贡献者们分享,涵盖基础知识、实践、调优、内部实现等各个方面,带你由浅入深地全面了解 Flink SQL。
1. 发展历程
今年的8月22日 Apache Flink 发布了1.9.0 版本(下文简称1.9),在 Flink 1.9 中,Table 模块迎来了核心架构的升级,引入了阿里巴巴Blink团队贡献的诸多功能,本文对Table 模块的架构进行梳理并介绍如何使用 Blink Planner。
Flink 的 Table 模块 包括 Table API 和 SQL,Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便;SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手,Flink Table API 和 SQL 的实现上有80%左右的代码是公用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的,但在 Flink 1.9 之前,Flink API 层 一直分为DataStream API 和 DataSet API, Table API & SQL 位于 DataStream API 和 DataSet API 之上。

Flink 1.8 Table 架构
在 Flink 1.8 架构里,如果用户需要同时流计算、批处理的场景下,用户需要维护两套业务代码,开发人员也要维护两套技术栈,非常不方便。 Flink 社区很早就设想过将批数据看作一个有界流数据,将批处理看作流计算的一个特例,从而实现流批统一,阿里巴巴的 Blink 团队在这方面做了大量的工作,已经实现了 Table API & SQL 层的流批统一。 幸运的是,阿里巴巴已经将 Blink 开源回馈给 Flink 社区。为了实现 Flink 整个体系的流批统一,在结合 Blink 团队的一些先行经验的基础上,Flink 社区的开发人员在多轮讨论后,基本敲定了Flink 未来的技术架构。
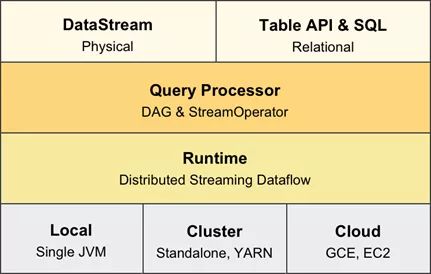
Flink 未来架构
在Flink 的未来架构中,DataSet API将被废除,面向用户的API只有 DataStream API 和 Table API & SQL,在实现层,这两个API共享相同的技术栈,使用统一的 DAG 数据结构来描述作业,使用统一的 StreamOperator 来编写算子逻辑,以及使用统一的流式分布式执行引擎,实现彻底的流批统一。 这两个API都提供流计算和批处理的功能,DataStream API 提供了更底层和更灵活的编程接口,用户可以自行描述和编排算子,引擎不会做过多的干涉和优化;Table API & SQL 则提供了直观的Table API、标准的SQL支持,引擎会根据用户的意图来进行优化,并选择最优的执行计划。
2.Flink 1.9 Table 架构
Blink 的 Table 模块的架构在开源时就已经实现了流批统一,向着 Flink 的未来架构迈进了第一步,走在了 Flink 社区前面。 因此在 Flink 1.9 合入 Blink Table 代码时,为了保证 Flink Table 已有架构和 Blink Table的架构能够并存并朝着 Flink 未来架构演进,社区的开发人员围绕FLIP-32(FLIP 即 Flink Improvement Proposals,专门记录一些对Flink 做较大修改的提议。FLIP-32是:Restructure flink-table for future contributions) 进行了重构和优化,从而使得 Flink Table 的新架构具备了流批统一的能力,可以说 Flink 1.9 是 Flink 向着流批彻底统一这个未来架构迈出的第一步。
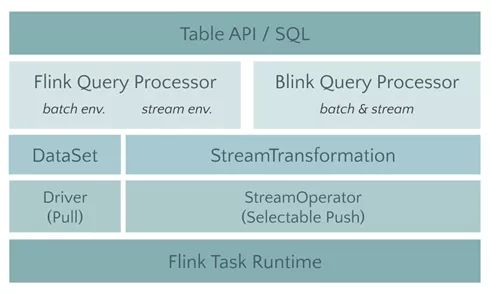
Flink 1.9 Table 架构
在 Flink Table 的新架构中,有两个查询处理器:Flink Query Processor 和 Blink Query Processor,分别对应两个Planner,我们称之为 Old Planner 和 Blink Planner。查询处理器是 Planner 的具体实现, 通过parser(解析器)、optimizer(优化器)、codegen(代码生成技术)等流程将 Table API & SQL作业转换成 Flink Runtime 可识别的 Transformation DAG (由Transformation组成的有向无环图,表示作业的转换逻辑),最终由 Flink Runtime 进行作业的调度和执行。
Flink 的查询处理器针对流计算和批处理作业有不同的分支处理,流计算作业底层的 API 是 DataStream API, 批处理作业底层的 API 是 DataSet API;而 Blink 的查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation。
3.Flink Planner 与 Blink Planner
Flink Table 的新架构实现了查询处理器的插件化,社区完整保留原有 Flink Planner (Old Planner),同时又引入了新的 Blink Planner,用户可以自行选择使用 Old Planner 还是 Blink Planner。
在模型上,Old Planner 没有考虑流计算作业和批处理作业的统一,针对流计算作业和批处理作业的实现不尽相同,在底层会分别翻译到 DataStream API 和 DataSet API 上。而 Blink Planner 将批数据集看作 bounded DataStream (有界流式数据) ,流计算作业和批处理作业最终都会翻译到 Transformation API 上。 在架构上,Blink Planner 针对批处理和流计算,分别实现了BatchPlanner 和 StreamPlanner ,两者共用了大部分代码,共享了很多优化逻辑。 Old Planner 针对批处理和流计算的代码实现的是完全独立的两套体系,基本没有实现代码和优化逻辑复用。
除了模型和架构上的优点外,Blink Planner 在阿里巴巴集团内部的海量业务场景下沉淀了许多实用功能,集中在三个方面:
- Blink Planner 对代码生成机制做了改进、对部分算子进行了优化,提供了丰富实用的新功能,如维表 join、Top N、MiniBatch、流式去重、聚合场景的数据倾斜优化等新功能。
- Blink Planner 的优化策略是基于公共子图的优化算法,包含了基于成本的优化(CBO)和基于规则的优化(CRO)两种策略,优化更为全面。同时,Blink Planner 支持从 catalog 中获取数据源的统计信息,这对CBO优化非常重要。
- Blink Planner 提供了更多的内置函数,更标准的 SQL 支持,在 Flink 1.9 版本中已经完整支持 TPC-H ,对高阶的 TPC-DS 支持也计划在下一个版本实现。
整体看来,Blink 查询处理器在架构上更为先进,功能上也更为完善。出于稳定性的考虑,Flink 1.9 默认依然使用 Flink Planner,用户如果需要使用 Blink Planner,可以作业中显式指定。
4.如何启用 Blink Planner
在IDE环境里,只需要引入两个 Blink Planner 的相关依赖,就可以启用 Blink Planner。
org.apache.flink
flink-table-api-scala-bridge_2.11
1.9.0
org.apache.flink
flink-table-planner-blink_2.11
1.9.0
对于流计算作业和批处理作业的配置非常类似,只需要在 EnvironmentSettings 中设置 StreamingMode 或 BatchMode 即可,流计算作业的设置如下:
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
bsTableEnv.sqlUpdate(…);
bsTableEnv.execute();
批处理作业的设置如下 :
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
bbTableEnv.sqlUpdate(…)
bbTableEnv.execute()
如果作业需要运行在集群环境,打包时将 Blink Planner 相关依赖的 scope 设置为 provided,表示这些依赖由集群环境提供。这是因为 Flink 在编译打包时, 已经将 Blink Planner 相关的依赖打包,不需要再次引入,避免冲突。
5. 社区长远计划
目前,TableAPI & SQL 已经成为 Flink API 的一等公民,社区也将投入更大的精力在这个模块。在不远的将来,待 Blink Planner 稳定之后,将会作为默认的 Planner ,而 Old Planner 也将会在合适的时候退出历史的舞台。目前社区也在努力赋予 DataStream 批处理的能力,从而统一流批技术栈,届时 DataSet API 也将退出历史的舞台。
▼ Apache Flink 社区推荐 ▼
Apache Flink 及大数据领域顶级盛会 Flink Forward Asia 2019 重磅开启,目前正在征集议题,限量早鸟票优惠ing。了解 Flink Forward Asia 2019 的更多信息,请查看:
https://developer.aliyun.com/special/ffa2019
首届 Apache Flink 极客挑战赛重磅开启,聚焦机器学习与性能优化两大热门领域,40万奖金等你拿,加入挑战请点击:
https://tianchi.aliyun.com/markets/tianchi/flink2019
关注 Flink 官方社区微信公众号,了解更多 Flink 资讯!
