
引子
上篇解析过的hashmap不是线程安全的,因此并发大师Doug Lea在jdk1.5增加了concurrenthashmap类以满足开发者在多线程环境安全使用map的需要。concurrenthashmap作为多线程环境常使用的类,它是如何实现线程安全的?但是又为什么说它不能完全替代hashtable?弱一致性又是怎样一回事?读完这篇解析concurrenthashmap的文章,我相信你会对concurrenthashmap的方方面面有一定的了解。
涉及到源码的分析,一般我们都是先分析数据结构,然后在分析算法,数据结结构和算法都理解了,那么你就了解了大部分内容。类似上篇hashmap,对concurrenthashmap的分析也分为三个部分:
- 第一部分:分析探究concurrenthashmap的数据结构。
- 第二部分:分析concurrenthashmap的重要算法实现。
- 第三部分:探究concurrenthashmap值得探讨的问题。
为了简单,跟hashmap类似的部分本文将一笔带过,如果没看过hashmap源码可以看上篇文章集合源码之hashmap,hashmap是concurrenthashmap的基础,不建议没读过hashmap直接看本篇文章。本文分析的源码采用的是concurrenthashmap较为简单的jdk1.6版本。
concurrentHashMap的数据结构
首先我们来看concurrenthashmap数据结构的图示,有个整体的认识。
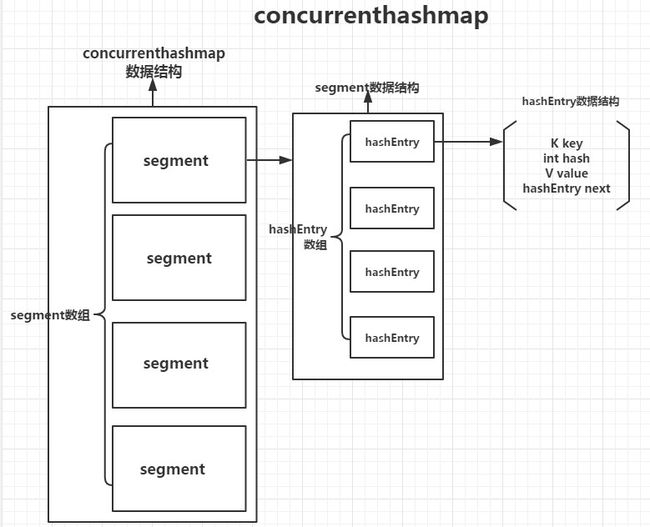
图里的是主要组成表示,我们更加具体的去分析concurrenthashmap的数据结构要分为concurrenthashmap的数据结构、segment的数据结构以及hashEntry的数据结构。重要的数据结构我们会解析用途以便大家更好的理解算法实现部分。
常量
- DEFAULT_INITIAL_CAPACITY:默认初始容量16,与hashmap相同。
- DEFAULT_LOAD_FACTOR:默认装填因子0.75
- DEFAULT_CONCURRENCY_LEVEL:默认并发级别16。其实就是segment个数,那为什么叫并发级别而不是segment数量呢?这里有必要细讲一下,我们知道concurrenthashmap是通过分段锁来实现高效并发的,这里的锁就是指segment,每个segment持有一把锁管理自身的数据。所以有几个segment就有几把锁,也就是几的并发级别。另外,segment初始化之后数量不会再改变。
- MAXIMUM_CAPACITY:最大容量。
- MAX_SEGMENTS:最大并发级别。
- RETRIES_BEFORE_LOCK:查询操作无锁获取尝试次数。即某些查询操作先不加锁获取,如果获取的结果不对(获取期间concurrenthashmap值变化)重试,如果超过尝试次数,再进行加锁获取操作。
实例变量
- segmentMask/segmentShift:计算对应的segment索引使用。
- segments:对应的segment数组。
- keySet/entrySet/values:对应的key、entry set集合。值的values集合。
segment
我们有必要对segment单独的进行数据结构分析,因为主要的算法实现都是在segment中,segment是concurrenthashmap的灵魂。可以把segment看做是线程安全的hashmap,因为数据结构与hashmap非常相似。
- 继承 ReentrantLock:因此segment具有锁的特性,可以对自身进行加锁解锁等操作。
- count/modCount/threshold/loadfactor:数量、修改次数、扩容临界值、装填因子。
- hashEntry[]:真正存储数据的节点类数组。数据结构如开篇图示。
concurrenthashmap重要算法实现
正如上文提到的,concurrenthashmap的灵魂是segment,segment的算法实现是整个concurrenthashmap的基础,我们会着重分析segment的实现。
构造方法
多个构造方法,只讨论最核心的构造方法。主要分为下面几个步骤:
- 校验参数:校验入参初始容量、装填因子、并发级别合法性。
- 根据并发级别确定segment数组大小:segment也得是2的指数大小。segmentmask为segment的大小-1,segmentshift为32减去调整并发级别次数。
- 初始化segment:这里有段代码值得讨论。
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment(cap, loadFactor);
这段代码计算cap的最终目的是为了确认初始化segment大小,让cap与segment总数的乘积要大于等于初始容量的大小。
重要算法
需要说明的是除了全局的算法,大部分算法都是确定是哪个segment,然后调用segment方法。分为四类探讨增删改查,另外不接受null的value。
查
- isEmpty():需要校验所有的segment,所有算法实现要考虑的比hashmap要多。主要分为两步:初次校验、再次校验。这两步很多方法用到,需要着重理解。
- 初次校验: 遍历所有segment,如果count不为0返回false,并记录每个segment的modcount以及所有的modcount以便再次校验。
- 再次校验:总modcount为0说明为空。不为0说明有值,那么就可能存在初次校验时发生值修改的情况,需要再次校验。遍历segment,如果count不为0以及每个modcount发生修改就返回false。
- size():即所有segment的count和。先不加锁获取,失败加锁获取。
- 不加锁获取:循环次数由RETRIES_BEFORE_LOCK决定。先遍历segment记录和、每个modcount以及总modcount。如果modcount不为0需要再次校验,校验时modcount不符则强制加锁读取,否则获取第二次校验和。两次和相同即为size,不同再次循环。
- 加锁获取:两次的和不同的前提。遍历segment加锁、遍历取和、遍历解锁。返回和值。
- get(key):根据hash值找到对应的segment,然后调用segment的get方法。
- segment---get(key,hash):如果count为0直接返回null。根据hash值得到对应entry的首节点,遍历节点,没找到返回null,找到了返回对应的value。但是这里需要注意的是get是不加锁操作,可能get时有线程修改value导致对应key的value为null,这时候需要加锁读取了(readValueUnderLock(e))
- containskey(key):根据hash值找到对应segment,调用contain方法
- segment---containsKey(key,hash):如果count为0直接返回false。根据hash值得到对应entry数组索引的首节点。遍历节点,存在返回true,否则返回false。
- containsValue(value):因为value存在的segment不确定,需要遍历所有的segment。与size的操作相同,先不加锁执行,然后如果需要在加锁执行。主要分为三步:
- 不加锁读取:遍历segment,调用segment的containsvalue方法,包含返回true,否则执行不加锁校验方法。
- 不加锁校验:总modcount不为0,校验每个segment的modcount,如果有不相同说明值发生改变需要加锁读取,如果modcount没变说明不包含指定value,返回false。
- 加锁读取:遍历segment加锁。遍历segment调用containsvalue,存在返回true,否则返回false,遍历解锁。
增(put(key,value)/putIfAbsent(key,value))
增加方法也是调用segment的put(key,hash,value,boolean onlyIfAbsent)。onlyifabsent如果为true,则如果segment存在key不替换value。put默认替换value。put方法先lock,然后进行put操作。put方法跟hashmap类似,此处不赘述。
删(remove(key)/remove(key,value))
删除方法也是调用segment的remove(key,hash,value)方法。先找到要删除的节点,找到后删除节点,但是这里的删除跟hashmap中的有所不同,因为hashentry的next是final的不可改变,所以只能新建节点,next指向删除节点的next,然后克隆删除节点前继节点,这样就完成了删除操作。
另外clear方法是遍历segment,调用segment的clear方法。clear方法加锁,遍历hashentry数组置null。
改
修改方法有两个,一个是replace(key,value)调用segment的replace(key,hash,value),另一个是replace(key,oldvalue,newvalue)调用segment的replace(key,hash,oldvalue,newvalue)。
- segment---replace(key, hash, value):先加锁,然后遍历节点找到对应的节点,替换value。如果不存在key对应的节点就返回null。
- segment---replace(key, hash,oldvalue,newvalue):跟上面的方法类似,不同的是如果节点里的value跟传入的oldvalue不同也不进行替换。
深入探讨
concurrenthashmap的弱一致性
什么叫弱一致性?理想的强一致性就是放入一个元素后,立即获取元素就是刚放入的元素,但是concurrenthashmap可能某时间段看不到这个元素。如下图两个线程执行顺序:

与hashtable、collections封装后的SynchronizedMap比较
其实还可以加入concurrenthashmap的segment。
- hashtable:使用synchronized关键字对方法进行修饰。
- SynchronizedMap:使用一个mutex对象作为锁,每次访问方法必须要获取mutex对象的锁。
- segment:使用ReentrantLock作为锁,访问方法时lock进行加锁
- concurrenthashmap:多个segment。
一对比就可以看出concurrenthashmap引入并发级别的策略,可以让concurrenthashmap在多线程环境的性能更加突出,速度也更快。