注:本文很多素材来源于网络上前人总结和《流畅的python》一书,本人仅仅以个人视角重新整合,便于自己理解,再此声明
并发是指一次处理多件事。
并行是指一次做多件事。
二者不同,但是有联系。
一个关于结构,一个关于执行。
并发用于制定方案,用来解决可能(但未必)并行的问题。
by Rob Pike
1、简介
看了太多的人写的多进程,多线程,协程相关的文章,依然是云里雾里的,即便是知道了一二,可依然写不出了相关逻辑的代码,直到有一天,我看到了这篇文章,才略有些思路,所以我想从这里开始,从新的视角下学习一下多进程,多线程之类的东西。
附上文档地址http://learn-gevent-socketio.readthedocs.io/en/latest/general_concepts.html
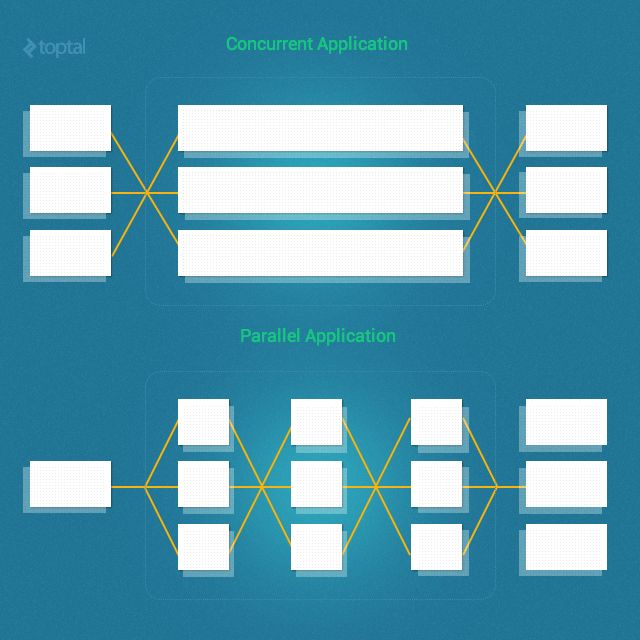
2. 并发和并行
当我们讨论实现线程(不管是绿线还是pthreads)和进程时,我们真正想实现的是并发性和/或并行性。那并发性和并行性两者有什么区别呢?并发性和并行性是截然不同的概念,但也是有联系的。特别的,Ruby的并发性是指两个任务可以在重叠的时间段内开始执行,运行,结束。但这并不一定意味着,他们会同时在同一时刻运行(例如,多线程在单核心机器上运行)。相反,并行性是两个任务同时运行的时候。真正的并行需要多个核心。(多进程在多核心机器上运行)。这里的关键点是,并发线程和/或进程并不一定是并行运行的。
并发性涉及从不同线程管理对共享状态的访问,而并行性则涉及利用多个处理器/内核来提高计算的性能。
3.线程和进程
3.1 进程
进程是一个正在运行的程序的一个实例。包括程序代码和当前的活动,根据操作系统的不同,一个进程可能由多个执行指令的执行线程组成。大多数现代操作系统都阻止了独立进程之间的直接通信,提供了严格的中介和控制的进程间通信 (IPC).
一个进程典型的包含以下资源:
1.an image of the executable machine code associated with the program
2.memory, which includes:2.1.executable code
2.2.process-specific data (input and output)
2.3.call stack that keeps track of active subroutines and/or other events
2.4.heap which holds intermediate computation data during run time
3.operating system descriptors of resources that are allocated to the process such as file descriptors (unix/linux) and handles (windows), dat sources and sinks
4.security attributes (process owner and set of permissions, e.g. allowable operations)
5.processor state (context) such as registers and physical memory addressing
操作系统将关于进程的很多信息都放在了程序控制块中(PCB)。操作系统将其进程分隔开,并分配所需的资源。这样它们就不太可能相互干扰从而导致系统故障。操作系统可以为进程间通信提供机制,使进程以安全且可预测的方式进行。
3.2 线程
线程是CPU可使用的最基本单元。有时候也成为轻量级进程。线程是进程中的指令序列,其行为类似于进程中的进程。 它不同于进程是因为它没有自己的程序控制块。通常,在进程中创建多线程。线程在进程内执行,进程在操作系统内核中执行。
一个线程的组成:
- thread ID
- program counter
- register set
- stack
注意:1. Python线程是在我所知道的所有实现中使用OS线程实现的(C Python、PyPy和Jython)。对于每个Python线程,都有一个底层OS线程。
2.一些操作系统(Linux是其中之一)在所有正在运行的进程的列表中提供由同一个可执行程序启动的所有不同的线程。这是操作系统的实现细节,而不是Python。在其他一些操作系统上,在列出所有进程时,可能看不到这些线程。
3.对于操作系统,一个进程由多个线程组成,每个线程都是相等的.操作系统不知道那个是守护进程线程。这纯粹是一个Python概念。当最后一个非守护线程完成时,进程将终止。在这一点上,所有守护进程线程都将被终止。所以,这些线程是你的进程的一部分,但并没有阻止它的终止。当系统调用_exit函数时,进程中断。主线程也会中断。python解释器会检测是否还有非守护线程运行,如果没有,就调用_exit.否则会等到非守护进程结束后再调用_exit.
4.这个守护线程标志是由threading模块在纯Python中实现的。当模块加载后,一个Thread类将会被创建用来代替main线程。它的 _exitfunc 方法被注册成一个 atexit 钩子.
import sys
import time
import threading
class WorkerThread(threading.Thread):
def run(self):
while True:
print 'Working hard'
time.sleep(0.5)
def main(args):
use_daemon = False
for arg in args:
if arg == '--use_daemon':
use_daemon = True
worker = WorkerThread()
worker.setDaemon(use_daemon)
worker.start()
time.sleep(1)
sys.exit(0)
if __name__ == '__main__':
main(sys.argv[1:])
上面的例子可以说明常规线程和守护线程的区别,当脚本以带有--use daemon的选项运行时,线程被设置为守护线程,在打印出一条后,整个程序就结束了。如果不带选项,程序将持续打印,即便是主线程结束也不会停止,直到被kill。
线程和进程的区别:
在单个处理器上,多线程通常是由时分多路复用(也称为多任务处理)发生的,也就是说,在不同线程之间的单处理器切换。这种上下文切换的速度非常快,这样我们就可以在同一时间看到线程在运行。在多处理器和多核系统中,线程可以是真正的并发,每个处理器或CPU内核同时执行一个单独的线程。
4、协程
4.1 概述
协程是一种 允许在特定位置暂停或恢复的子程序。但和 生成器 不同的是,协程 可以控制子程序暂停之后代码的走向,而 生成器 仅能被动地将控制权交还给调用者。
Coroutines适用于实现合作任务、迭代器、无限列表和管道。协程看上去像是线程,使用的接口类似线程接口,但是实际使用非线程的方式,对应的线程开销也不存的。协程 可以只利用一个线程更加轻便地实现 多任务,将任务切换的开销降至最低。和 回调 等其他异步技术相比,协程 维持了正常的代码流程,在保证代码可读性的同时最大化地利用了 阻塞 IO 的空闲时间。它的高效与简洁赢得了开发者们的拥戴。
常用的协程实现方式分为有以gevent,在底层实现了协程调度,并将大部分的 阻塞 IO 重写为异步。使用c语言实现的,第二种为Tornado中异步编程方式,直到python3.5中,语法上以async和await关键字实现的协程,可读性更好一些。
具体的说,协程是函数体中包含yield或者yield from 的函数。一个协程可以通常处于四种状态之一('GEN_CREATED',,'GEN_RUNNING','GEN_SUSPENDED','GEN_CLOSED').协程状态可以使用inspect.getgeneratorstate(...)函数来获知。
第一次激活线程通常有next(my_coro)完成。你也可以使用my_coro.send(None)完成,他们的作用是一样的。
协程的执行被明确的挂起在yield关键字上。具体例子:a= yield b.位于关键字右侧的值也就是b值,被返回给调用者,协程让出控制权。直到调用者调用send方法发送一个值,协程拿回控制权,调用者发送的值被分配给等号左侧的变量,也就是变量a.
4.2 异常处理
调用者通过throw和close方法,可以明确的发送异常给协程。
4.3 yield from 表达式
在python 3.3版本后,一个协程可以返回给调用者值,但是值是作为StopIteraton异常对象属性(value属性)。yield from 自动的启动协程,并处理StopIteration异常。
简单的,yield from 可用于简化 for 循环中的 yield 表达式。例如
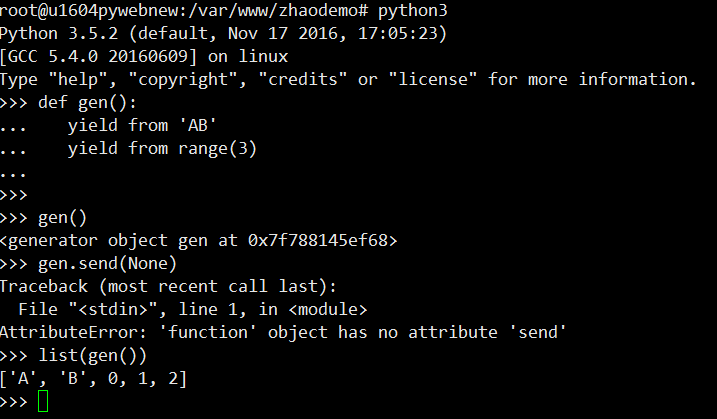
yield from 也可以用来链接可迭代对象,比如:
>>> def chain(*iterables):
... for it in iterables:
... yield from it
...
>>> s = 'ABC'
>>> t = tuple(range(3))
>>> list(chain(s, t))
['A', 'B', 'C', 0, 1, 2]
yield from x 表达式对 x 对象所做的第一件事是,调用 iter(x),从中获取迭代器。因此,x 可以是任何可迭代的对象。
yield from 的主要功能是打开双向通道,把最外层的调用方与最内层的子生成器连接起来,这样二者可以直接发送和产出值,还可以直接传入异常,而不用在位于中间的协程中添加大量处理异常的样板代码。有了这个结构,协程可以通过以前不可能的方式委托职责。
yield from 结构会在内部自动捕获 StopIteration 异常。这种处理方式与 for 循环处理 StopIteration 异常的方式一样:循环机制使用用户易于理解的方式处理异常。对 yield from 结构来说,解释器不仅会捕获 StopIteration 异常,还会把value 属性的值变成 yield from 表达式的值。可惜,我们无法在控制台中使用交互的方式测试这种行为,因为在函数外部使用 yield from(以及 yield)会导致句法出错。
借用别人的例子来说明一下yield from的使用
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# the subgenerator
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield
if term is None: # The crucial terminating condition. Without it, a yield from calling this coroutine will block forever
break
total += term
count += 1
average = total/count
return Result(count, average) # The returned Result will be the value of the yield from expression in grouper.
# the delegating generator
def grouper(results, key):
while True:
# Whenever grouper is sent a value, it’s piped into the `averager` instance by the `yield from`.
# `grouper` will be suspended here as long as the `averager` instance is consuming values sent by the
# client. When an `averager` instance runs to the end, the value it returns is bound to `results[key]`.
# The `while` loop then proceeds to create another `averager` instance to consume more values.
results[key] = yield from averager()
# the client code, a.k.a. the caller
def main(data):
results = {}
for key, values in data.items():
group = grouper(results, key)
next(group)
for value in values:
# Send each value into the grouper. That value ends up in the `term = yield` line of averager;
# grouper never has a chance to see it.
group.send(value)
# causes the current `averager` instance to terminate, and allows `grouper` to run again, which
# creates another `averager` for the next group of values.
group.send(None) # important!
# print(results) # uncomment to debug
report(results)
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(
result.count, group, result.average, unit))
data={ 'girls;kg':
[40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m':
[1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg':
[39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m':
[1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
把 None 传入 grouper,导致当前的 averager 实例终止,也让 grouper 继续运行,再创建一个 averager 实例,处理下一组值。
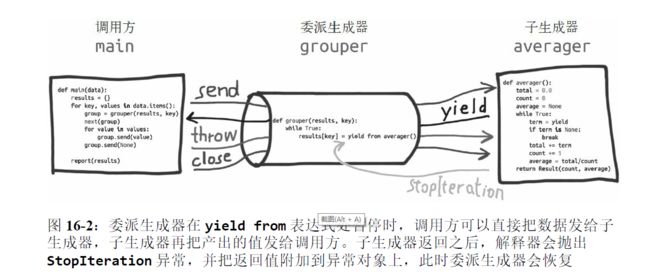
这个试验想表明的关键一点是,如果子生成器不终止,委派生成器会在yield from 表达式处永远暂停。如果是这样,程序不会向前执行,因为 yield from(与 yield 一样)把控制权转交给客户代码(即,委派生成器的调用方)了。显然,肯定有任务无法完成。
上面的示例展示了 yield from 结构最简单的用法,只有一个委派生成器和一个子生成器。因为委派生成器相当于管道,所以可以把任意数量个委派生成器连接在一起:一个委派生成器使用 yield from 调用一个子生成器,而那个子生成器本身也是委派生成器,使用 yield from 调用另一个子生成器,以此类推。最终,这个链条要以一个只使用 yield表达式的简单生成器结束;不过,也能以任何可迭代的对象结束。
4.4 asyncio
asyncio 这个包使用事件循环驱动的协程实现并发。该包使用的“协程”是较严格的定义。适合asyncio API 的协程在定义体中必须使用 yield from,而不能使用 yield。此外,
适合 asyncio 的协程要由调用方驱动,并由调用方通过 yield from 调用;或者把协程传给 asyncio 包中的某个函数,例如 asyncio.async(...) 和本章要介绍的其他函数,从而驱动协程。最后,@asyncio.coroutine 装饰器应该应用在协程上.
import asyncio
import itertools
import sys
@asyncio.coroutine
def spin(msg):
write, flush = sys.stdout.write, sys.stdout.flush
for char in itertools.cycle('|/-\\'):
status = char + ' ' + msg
write(status)
flush()
write('\x08' * len(status))
try:
yield from asyncio.sleep(.1)
except asyncio.CancelledError:
break
write(' ' * len(status) + '\x08' * len(status))
@asyncio.coroutine
def slow_function():
# 假装等待I/O一段时间
yield from asyncio.sleep(3)
return 42
@asyncio.coroutine
def supervisor():
spinner = asyncio.async(spin('thinking!'))
print('spinner object:', spinner)
result = yield from slow_function()
spinner.cancel()
return result
def main():
loop = asyncio.get_event_loop()
# 驱动 supervisor 协程,让它运行完毕;这个协程的返回值是这次调用的返回值。
result = loop.run_until_complete(supervisor())
loop.close()
print('Answer:', result)
if __name__ == '__main__':
main()
4.5 asyncio.Future
asyncio.Future 类与 concurrent.futures.Future 类的接口基本一致,不过实现方式不同,不可以互换.
在 asyncio 包中,BaseEventLoop.create_task(...) 方法接收一个协程,排定它的运行时间,然后返回一个 asyncio.Task 实例——也是 asyncio.Future 类的实例,因为 Task 是Future 的子类,用于包装协程。这与调用 Executor.submit(...) 方法创建
concurrent.futures.Future 实例是一个道理。
与 concurrent.futures.Future 类似,asyncio.Future 类也提供了.done()、.add_done_callback(...) 和 .result() 等方法。不过 .result() 方法差别很大。asyncio.Future 类的 .result() 方法没有参数,因此不能指定超时时间。此外,如果调用 .result() 方法时期物还没运行完毕,那么 .result() 方法不会阻塞去等待结果,而是抛出 asyncio.InvalidStateError 异常.获取 asyncio.Future 对象的结果通常使用 yield from,从中产出结果.
总之,因为 asyncio.Future 类的目的是与 yield from 一起使用,所以通常不需要使用以下方法:
1.无需调用 my_future.add_done_callback(...),因为可以直接把想在期物运行结束后执行的操作放在协程中 yield from my_future 表达式的后面。这是协程的一大优势:协程是可以暂停和恢复的函数。
2.无需调用 my_future.result(),因为 yield from 从期物中产出的值就是结果(例如,result = yield from my_future)。
在 asyncio 包中,期物和协程关系紧密,因为可以使用 yield from 从asyncio.Future 对象中产出结果。这意味着,如果 foo 是协程函数(调用后返回协程对象),抑或是返回 Future 或 Task 实例的普通函数,那么可以这样写:res = yield from foo()。这是 asyncio 包的 API 中很多地方可以互换协程与期物的原因之一。为了执行这些操作,必须排定协程的运行时间,然后使用 asyncio.Task 对象包装协程。对协程来说,获取 Task 对象有两种主要方式:
1.asyncio.async(coro_or_future, *, loop=None)
2.BaseEventLoop.create_task(coro)
4.6 关于测试代码中的time.sleep注意
实际应用中必须使用支持异步操作的非阻塞代码才能实现真正的异步。举个例子,比如,我们在爬虫的时候,需要请求的url列表中有和很多需要请求的url.这个时候使用requests库中的get请求方法,即便是放在异步实现的代码中,其实际操作还是同步请求的,真正想要实现异步还得使用非阻塞形式实现的库aiohttp.
4.7 asyncio 进阶
http://python.jobbole.com/87310/