参考
【PHPsocket编程专题(理论篇)】初步理解TCP/IP、Http、Socket
聊聊Socket、TCP/IP、HTTP、FTP及网络编程
一、ISO/OSI TCP/IP 模型
参考
OSI七层模型详解
网络协议概述:物理层、连接层、网络层、传输层、应用层详解
OSI(Open System Interconnect),即开放式系统互联。 一般都叫OSI参考模型,是ISO(国际标准化组织)组织在1985年研究的网络互联模型。该体系结构标准定义了网络互连的七层框架(物理层、数据链路层、网络层、传输层、会话层、表示层和应用层),即ISO开放系统互连参考模型。注意这仅仅是一个参考模型,实际用得更多的是更成熟的TCP/IP模型。
TCP/IP模型实际上是OSI模型的一个浓缩版本,它只有四个层次。
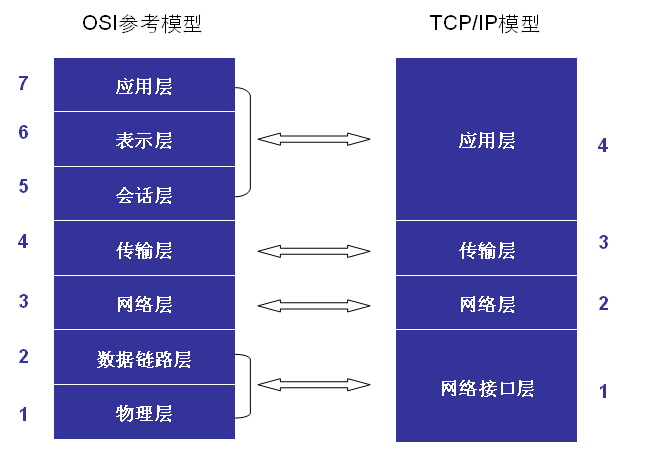

1.物理层(physical layer)
所谓的物理层,是指光纤、电缆或者电磁波等真实存在的物理媒介。这些媒介可以传送物理信号,比如亮度、电压或者振幅。对于数字应用来说,我们只需要两种物理信号来分别表示0和1,比如用高电压表示1,低电压表示0,就构成了简单的物理层协议。针对某种媒介,电脑可以有相应的接口,用来接收物理信号,并解读成为0/1序列。
2.连接层(link layer)
在连接层,信息以帧(frame)为单位传输。所谓的帧,是一段有限的0/1序列。连接层协议的功能就是识别0/1序列中所包含的帧。比如说,根据一定的0/1组合识别出帧的起始和结束。在帧中,有收信地址(Source, SRC)和送信地址(Destination, DST),还有能够探测错误的校验序列(Frame Check Sequence)。当然,帧中最重要的最重要是所要传输的数据 (payload)。这些数据往往符合更高层协议,供网络的上层使用。与数据相配套,帧中也有数据的类型(Type)信息。连接层协议不关心数据中到底包含什么。帧就像是一个信封,把数据包裹起来。
以太网(Ethernet)和WiFi是现在最常见的连接层协议。通过连接层协议,我们可以建立局域的以太网或者WiFi局域网,并让位于同一局域网络中的两台计算机通信。连接层就像是一个社区的邮差,他认识社区中的每一户人。社区中的每个人都可以将一封信(帧)交给他,让他送给同一社区的另一户人家。
3.网络层(network layer)
不同的社区之间该如何通信呢? 换句话说,如何让WiFi上的一台计算机和以太网上的另一台计算机通信呢?我们需要一个“中间人”。这个“中间人”必须有以下功能: 1. 能从物理层上在两个网络的接收和发送0/1序列,2. 能同时理解两种网络的帧格式。路由器(router)就是为此而产生的“翻译”。一个路由器有多个网卡(NIC,Network Interface Controller),每个NIC可以接入多个网络,并理解相应的连接层协议。在帧经过路由到达另一个网络的时候,路由会读取帧的信息,并改写以发送到另一个网络。所以路由器就像是在两个社区都有分支的邮局。一个社区的邮差将信送到本社区的邮局分支,而邮局会通过自己在另一个地区的分支将信转交给另一个社区的邮差手中,并由另一个社区的邮差最终送到目的地。
通过路由连接的WiFi和以太网通信过程如下:
WiFi上的计算机1 -> 路由WiFi接口 -> 路由以太网接口 -> 以太网上的计算机2
在连接层,我们的一个帧中只能记录SRC和DST两个地址。而上面的过程需要经过四个地址 (计算机1,WiFi接口,以太网接口,计算机2)。显然,仅仅靠连接层协议无法满足我们的需要。由于连接层协议开发在先,我们无法改动连接层协议,只能在连接层的数据(payload),也就是信纸内部下功夫了。IP协议应运而生。
计算机1,路由器和计算机2都要懂得IP协议。当计算机1写信的时候,会在信纸的开头写上这封信的出发地址和最终到达地址 (而不是在信封上),而在信封上写上要送往邮局。WiFi网的邮差将信送往邮局。在邮局,信被打开,邮局工作人员看到最终地址,于是将信包装在一个新的信封中,写上出发地为邮局,到达地为计算机2,并交给以太网的邮差,由以太网的邮差送往计算机2。(IP协议还要求写如诸如校验等信息,交通状况等信息,以保护通信的稳定性。)
在连接层,邮差只负责在本社区送信,所以信封上的地址总是“第一条街第三座房子”或者说“中心十字路口拐角的小房子”这样一些本地人才了解的地址描述,这给邮局的工作带来不便。所以邮局要求,信纸上写的地址必须是一个符合官方规定的“邮编”,也就是IP地址。这个地址为世界上的每一个房子编号(邮编)。当信件送到邮局的时候,邮局根据邮编,就能查到对应的地址描述,从而能顺利改写信封上的信息。
每个邮局一般连接多个社区,而一个社区也可以有多个邮局,分别通往不同的社区。有时候一封信要通过多个邮局转交,才能最终到达目的地,这个过程叫做route。邮局将分离的局域网络连接成了internet,并最终构成了覆盖全球的互联网。
4.传输层(transport layer)
上面的三层协议让不同的计算机之间可以通信。但计算机中实际上有许多个进程,每个进程都可能有通信的需求。这就好像一所房子里住了好几个人(进程),如何让信精确的送到某个人手里呢?遵照之前相同的逻辑,我们需要在信纸上写上新的信息,比如收信人的姓名,才可能让信送到。所以,传输层就是在信纸的空白上写上新的“收信人”信息。每一所房子会配备一个管理员(传输层协议)。管理员从邮差手中接过信,会根据“收信人”,将信送给房子中的某个人。
传输层协议,比如TCP和UDP,使用端口号(port number)来识别收信人(某个进程)。在写信的时候,我们写上目的地的端口。当信到达目的地的管理员手中,他会根据传输层协议,识别端口号,将信送给不同的人。
TCP和UDP协议是两种不同的传输层协议。UDP协议类似于我们的信件交流过程。TCP协议则好像两个情人间的频繁通信。一个小情人要表达的感情太多,以致于连续写了好几封信。而另一方必须将这些信按顺序排列起来,才能看明白全部的意思。TCP协议还有控制网络交通等功能。
5.应用层(application layer)
通过上面的几层协议,我们已经可以在任意两个人(进程)之间进行通信。然而每个人实际上从事的是不同的行业。有的人是律师,有的人外交官。比如说律师之间的通信,会用严格的律师术语,以免产生纠纷。再比如外交官之间的通信,必须符合一定的外交格式,以免发生外交误会。再比如间谍通过暗号来传递加密信息。应用层协议是对信件内容进一步的用语规范。应用层的协议包括用于Web浏览的HTTP协议,用于传输文件的FTP协议,用于Email的IMAP等等。
应用层所谓的应用,就是为了一个具体的应用场景而做的协议,应用层协议之间的区别,就是应用之间的区别。HTTP和FTP有什么区别,就是HTTP用来传输超文本而FTP用来传文件。
二、传输层的TCP UDP
传输层有多个协议,但最主要的是TCP和UDP协议。两者的区别在于TCP协议需要接收方反馈,UDP协议不需要接收方反馈。TCP就像挂号信,A电脑发信息给B电脑后,需要得到B电脑的反馈,这样A电脑就能知道B电脑是否已经收到信息。UDP就像平信,A电脑发信息给B电脑后,B电脑并不给A电脑发聩,A电脑发送信息出去后并不知道B电脑是否已经收到。 因此,TCP传输比UDP传送更可靠,但是TCP传输的效率就不如UDP了。
知道了TCP和UDP的区别,就不难理解为何采用TCP传输协议的MSN比采用UDP的QQ传输文件慢了,但并不能说QQ的通信是不安全的,因为程序员可以手动对UDP的数据收发进行验证,比如发送方对每个数据包进行编号然后由接收方进行验证啊什么的,即使是这样,UDP因为在底层协议的封装上没有采用类似TCP的“三次握手”而实现了TCP所无法达到的传输效率。
建立起一个TCP连接需要经过“三次握手”: 第一次握手:客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认; 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
握手过程中传送的包里不包含数据,三次握手完毕后,客户端与服务器才正式开始传送数据。理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。断开连接时服务器和客户端均可以主动发起断开TCP连接的请求,断开过程需要经过“四次握手”(过程就不细写了,就是服务器和客户端交互,最终确定断开)
以对话的形式来比喻这个过程:“客户端:你在酒店吗,在的话我就来了。服务端:我在酒店的,房间是308号,速来!客户端:好的,我来了,你等我哦,么么哒”。然后客户端才真正的去找服务端;
TCP发送的包有序号,对方收到包后要给一个反馈,如果超过一定时间还没收到反馈就自动执行超时重发,因此TCP最大的优点是可靠。一般网页(http)、邮件(SMTP)、远程连接(Telnet)、文件(FTP)传送就用TCP
UDP是面向消息的协议,通信时不需要建立连接,数据的传输自然是不可靠的,UDP一般用于多点通信和实时的数据业务,比如语音广播、视频、QQ、TFTP(简单文件传送)、SNMP(简单网络管理协议)、RTP(实时传送协议)RIP(路由信息协议,如报告股票市场,航空信息)、DNS(域名解释)。注重速度流畅。
三、SOCKET
1.概念
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。
在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。

通过Socket,我们才能使用TCP/IP协议。实际上,Socket跟TCP/IP协议没有必然的联系。Socket编程接口在设计的时候,就希望也能适应其他的网络协议。所以说,Socket的出现只是使得程序员更方便地使用TCP/IP协议栈而已,是对TCP/IP协议的抽象,从而形成了我们知道的一些最基本的函数接口,比如create、listen、connect、accept、send、read和write等等。
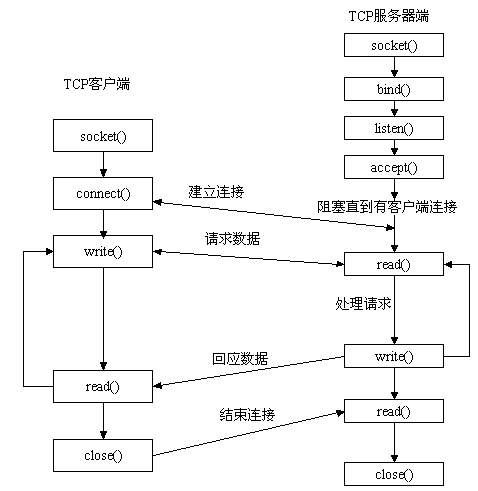
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
2.TCP粘包
参考
TCP粘包解决方法
tcp是流的一些思考--拆包和粘包
TCP粘包通俗来讲,就是发送方发送的多个数据包,到接收方后粘连在一起,导致数据包不能完整的体现发送的数据。
TCP粘包原因分析
导致TCP粘包的原因,可能是发送方的原因,也有可能是接受方的原因。
发送方
由于TCP需要尽可能高效和可靠,所以TCP协议默认采用Nagle算法,以合并相连的小数据包,再一次性发送,以达到提升网络传输效率的目的。但是接收方并不知晓发送方合并数据包,而且数据包的合并在TCP协议中是没有分界线的,所以这就会导致接收方不能还原其本来的数据包。
接收方
TCP是基于“流”的。网络传输数据的速度可能会快过接收方处理数据的速度,这时候就会导致,接收方在读取缓冲区时,缓冲区存在多个数据包。在TCP协议中接收方是一次读取缓冲区中的所有内容,所以不能反映原本的数据信息。
解决TCP粘包
自定协议,将数据包分为了封包和解包两个过程。在发送方发送数据时,对发送的数据进行封包操作。在接收方接收到数据时对接收的数据包需要进行解包操作。
自定协议时,封包就是为发送的数据增加包头,包头包含数据的大小的信息,数据就跟随在包头之后。当然包头也可以有其他的信息,比如一些做校验的信息。
四、HTTP
参考
廖雪峰 HTTP协议简介
HTTP协议漫谈
Android之Http通信——1.初识Http协议
Android网络请求心路历程
HTTPS理论基础及其在Android中的最佳实践
1.HTTP请求
也就是Web客户端向Web服务器发送信息,这个信息由如下三部分组成:
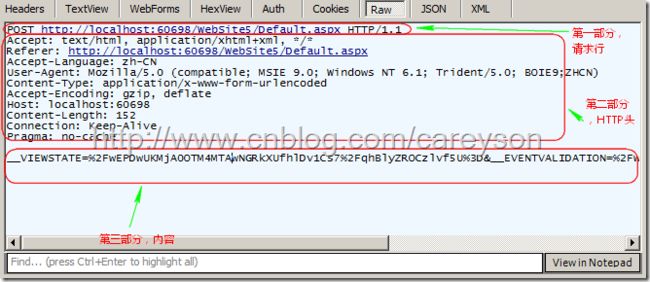
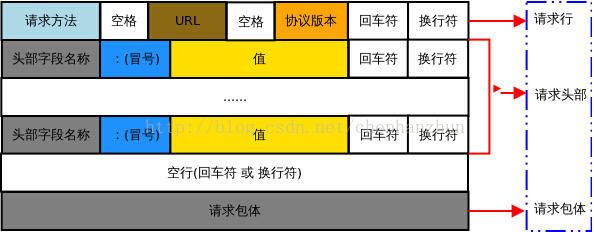
a.请求行
请求行写法是固定的,由三部分组成,第一部分是请求方法,第二部分是请求网址,第三部分是HTTP版本。GET www.cnblogs.com HTTP/1.1

GET表示一个读取请求,将从服务器获得网页数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。目前HTTP协议的版本就是1.1,但是大部分服务器也支持1.0版本,主要区别在于1.1版本允许多个HTTP请求复用一个TCP连接,以加快传输速度。也就是说,1.1协议,允许客户端与web服务器建立连接后,在一个连接上获取多个web资源!
我们看到上面我们发送http请求的方式是POST,它和GET在我们平时开发中使用较多,下面我们就罗列出所有的请求方式吧:
- Get:请求获取Request-URI所标识的资源
- POST:在Request-URI所标识的资源后附加新的数据
- HEAD 请求获取由Request-URI所标识的资源的响应信息报头
- PUT:请求服务器存储一个资源,并用Request-URI作为其标识
- DELETE:请求服务器删除Request-URI所标识的资源
- TRACE:请求服务器回送收到的请求信息,主要用于测试或诊断
- CONNECT:保留将来使用
- OPTIONS:请求查询服务器的性能,或者查询与资源相关的选项
重点说一下Get和Post方法,网上关于Get和Post的区别满天飞。但很多没有说到点子上。Get和Post最大的区别就是Post有上面所说的第三部分:内容。而Get不存在这个内容。因此就像Get和Post其名称所示那样,Get用于从服务器上取内容,虽然可以通过QueryString向服务器发信息,但这违背了Get的本意,QueryString中的信息在HTTP看来仅仅是获取所取得内容的一个参数而已。而Post是由客户端向服务器端发送内容的方式。因此具有请求的第三部分:内容。
要说一点,这两个玩意都是发送数据的,只是发送机制不一样,不要相信网上说的”GET获得服务器数据,POST向服务器发送数据”!! 另外GET安全性非常低,Post安全性较高,但是执行效率却比Post方法好,一般查询的时候我们用GET,数据增删改的时候用POST!!
具体用法参考开发HTTP服务器系列之实现Get和Post
b.HTTP头
在HTTP请求可以是3种HTTP头:请求头(request header) 普通头(general header) 实体头(entity header).通常来说,由于Get请求往往不包含内容实体,因此也不会有实体头。
c.内容
只在POST请求中存在,因为GET请求并不包含任何实体。
2.HTTP响应
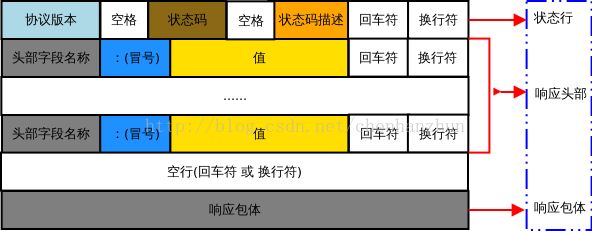
结构上很类似于HTTP请求,也是由三部分组成,分别为:
a.状态行
首先来看状态行,一个典型的HTTP状态如下:HTTP/1.1 200 OK
第一部分是HTTP版本,第二部分是响应状态码,第三部分是状态码的描述,因此也可以把第二和第三部分看成一个部分。对于HTTP版本没有什么好说的,而状态码值得说一下,网上对于每个具体的HTTP状态码所代表的含义都有解释,这里我说一下分类。
- 信息类 (100-199)
- 响应成功 (200-299)
- 重定向类 (300-399)
- 客户端错误类 (400-499)
- 服务端错误类 (500-599)
b.HTTP头
HTTP响应中包含的头包括响应头(response header) 普通头(general header) 实体头(entity header)。
c.返回内容
HTTP响应内容就是HTTP请求所请求的信息。这个信息可以是一个HTML,也可以是一个图片。比如我访问百度,HTTP Response如图
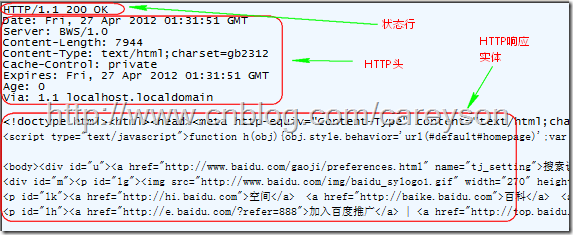
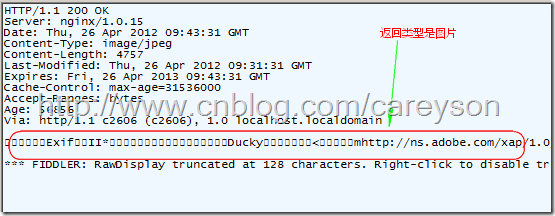
这里会有一个疑问,既然HTTP响应的内容不仅仅是HTML,还可以是其它类型,那么浏览器如何正确对接收到的信息进行处理?这是通过媒体类型确定的(Media Type),具体来说对应Content-Type这个HTTP头,比如text/html,image/jpeg。媒体类型的格式为:大类/小类 比如html是小类,而text是大类。浏览器并不靠URL来判断响应的内容,所以,即使URL是http://example.com/abc.jpg,它也不一定就是图片。
IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)定义了8个大类的媒体类型,分别是:
- application— (比如: application/vnd.ms-excel.)
- audio (比如: audio/mpeg.)
- image (比如: image/png.)
- message (比如,:message/http.)
- model(比如:model/vrml.)
- multipart (比如:multipart/form-data.)
- text(比如:text/html.)
- video(比如:video/quicktime.)
3.HTTP头
参考理解HTTP消息头
做过Socket编程的人都知道,当我们设计一个通信协议时,“消息头/消息体”的分割方式是很常用的,消息头告诉对方这个消息是干什么的,消息体告诉对方怎么干。HTTP传输的消息也是这样规定的,每一个HTTP包都分为HTTP头和HTTP体两部分,后者是可选的,而前者是必须的。每当我们打开一个网页,在上面点击右键,选择“查看源文件”,这时看到的HTML代码就是HTTP的消息体,那么消息头又在哪呢?IE浏览器不让我们看到这部分,但我们可以通过截取数据包等方法看到它。
下面就来看一个简单的例子:
首先制作一个非常简单的网页,它的内容只有一行:hello world把它放到WEB服务器上,比如IIS,然后用IE浏览器请求这个页面(http://localhost:8080/simple.htm),当我们请求这个页面时,浏览器实际做了以下四项工作:
- 解析我们输入的地址,从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下:
- 协议名:http
- 主机名:localhost
- 端口:8080
- 对象路径:/simple.htm
- 把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
- 使用TCP协议连接到主机的指定端口(localhost, 8080),并发送已封装好的数据包
- 等待服务器返回数据,并解析返回数据,最后显示出来
由截取到的数据包我们不难发现浏览器生成的HTTP数据包的内容如下:
GET /simple.htm HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,
application/x-shockwave-flash, application/vnd.ms-excel,
application/vnd.ms-powerpoint, application/msword, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;
SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
Host: localhost:8080
Connection: Keep-Alive
为了显示清楚我把所有的回车的地方都加上了“
消息的第一行“GET”表示我们所使用的HTTP动作,其他可能的还有“POST”等,GET的消息没有消息体,而POST消息是有消息体的,消息体的内容就是要POST的数据。后面/simple.htm就是我们要请求的对象,之后HTTP1.1表示使用的是HTTP1.1协议。
第二行表示我们所用的浏览器能接受的Content-type,三四两行则是语言和编码信息,第五行显示出本机的相关系信息,包括浏览器类型、操作系统信息等,很多网站可以显示出你所使用的浏览器和操作系统版本,就是因为可以从这里获取到这些信息。
第六行表示我们所请求的主机和端口,第七行表示使用Keep-Alive方式,即数据传递完并不立即关闭连接。
服务器接收到这样的数据包以后会根据其内容做相应的处理,例如查找有没有“/simple.htm”这个对象,如果有,根据服务器的设置来决定如何处理,如果是HTM,则不需要什么复杂的处理,直接返回其内容即可。但在直接返回之前,还需要加上HTTP消息头。
服务器发回的完整HTTP消息如下:
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.1
X-Powered-By: ASP.NET
Date: Fri, 03 Mar 2006 06:34:03 GMT
Content-Type: text/html
Accept-Ranges: bytes
Last-Modified: Fri, 03 Mar 2006 06:33:18 GMT
ETag: "5ca4f75b8c3ec61:9ee"
Content-Length: 37
hello world
同样,我用“
消息头第一行“HTTP/1.1”也是表示所使用的协议,后面的“200 OK”是HTTP返回代码,200就表示操作成功,还有其他常见的如404表示对象未找到,500表示服务器错误,403表示不能浏览目录等等。
第二行表示这个服务器使用的WEB服务器软件,这里是IIS 5.1。第三行是ASP.Net的一个附加提示,没什么实际用处。第四行是处理此请求的时间。第五行就是所返回的消息的content-type,浏览器会根据它来决定如何处理消息体里面的内容,例如这里是text/html,那么浏览器就会启用HTML解析器来处理它,如果是image/jpeg,那么就会使用JPEG的解码器来处理。
消息头最后一行“Content-Length”表示消息体的长度,从空行以后的内容算起,以字节为单位,浏览器接收到它所指定的字节数的内容以后就会认为这个消息已经被完整接收了。
以下参考
HTTP请求头与HTTP响应头
常用的HTTP请求头与响应头 全部列表查询
HTTP消息头,以明文的字符串格式传送,是以冒号分隔的键/值对,如:Accept-Charset: utf-8,每一个消息头最后以回车符(CR)和换行符(LF)结尾。HTTP消息头结束后,会用一个空白的字段来标识,这样就会出现两个连续的CR-LF。HTTP消息头支持自定义, 自定义的专用消息头一般会添加'X-'前缀。比如我在Aspx中加入代码:Response.AddHeader("测试头","测试值");对应的我们可以在fiddler抓到的信息如图7所示。
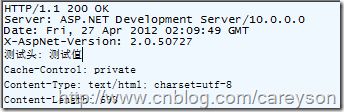
不难看出,HTTP头并不是严格要求的,仅仅是一个标签,如果浏览器可以解析就会按照某些标准(比如浏览器自身标准,W3C的标准)去解释这个头,否则不识别的头就会被浏览器无视。对服务器也是同理。假如你编写一个浏览器,你可以将上面的头解释成任何你想要的效果。
HTTP消息头,可以使服务器或客户端了解对方所使用的协议版本、内容类型、编码方式等。在HTTP消息头中,有些是客户端特有的,有些是服务端所特有的,也有些是消息头是通用的。按HTTP消息头出现的上下文环境,有以下分类:
a.通用头
HTTP消息头中,有些既适用于客户端的请求头,也适用于服务端的响应头,与HTTP消息体内最终传输的数据是无关的,只适用于要发送的消息。这些消息头由于HTTP协议版本的不同可能会有所区别,在HTTP/1.1中,这些消息头有:Cache-Control:、Connection:、Date:、 Pragma:、Trailer:、Transfer-Encoding:、Upgrade:、 Via:、Warning:。
b.请求头
HTTP 请求头为所请求的资源或请求本身,提供了更为精确的描述信息。其中有些缓存相关头描述了缓存信息,这些头会改变GET请求时获取资源的方式,如:If-Modified-Since。有些消息头描述了用户偏好,如: Accept-Language和Accept-Charset表示客户端所使用语言及编码方式、User-Agent表示客户端的代理方式。
新增加的请求头不能在旧的HTTP版本中使用,但是,如果服务器和客户端都能对相关头进行处理,就可以在请求中使用。在这种情况下,客户端不应该假定服务器有对相关头的处理能力。未知的请求头被处理为实体头。
c.响应头
HTTP 响应头为响应消息提供了更多信息。如,关于资源位置的描述Location:,关于务器本身的描述使用Server:
新增加的响应头不能在旧的HTTP版本中使用,但是,如果服务器和客户端都能对相关头进行处理,就可以在响应中使用。在这种情况下,服务器不应该假定客户端有对相关头的处理能力。未知的响应头被处理为实体头。
d.实体头
HTTP 实体头提供了关于消息体的描述。如,消息体的长度Content-Length:,消息体的MIME类型Content-Type:。新的实体头可以旧HTTP版本中使用。
4.状态保持
还有一点值得注意的是,HTTP协议是无状态的,这意味着对于接收HTTP请求的服务器来说,并不知道每一次请求来自同一个客户端还是不同客户端,每一次请求对于服务器来说都是一样的。因此需要一些额外的手段来使得服务器在接收某个请求时知道这个请求来自于某个客户端。
a.HTTP协议通过Cookies来保持状态.

- 第一次请求时没什么不同,略过
- 第一次返回时消息内容多了下面这一行:
Set-Cookie: key=haha; expires=Sun, 31-Dec-2006 16:00:00 GMT; path=/
很明显,key=haha表示键名为“key”的COOKIE的值为“haha”,后面是这则COOKIE的过期时间,因为我用的中文操作系统的时区是东八区,2007年1月1日0点对应的GMT时间就是2006年12月31日16点。 - 第二次再访问此网页时,发送的内容多了如下一行:
Cookie: key=haha它的内容就是刚才设的COOKIE的内容。可见,客户端在从服务器端得COOKIE值以后就保存在硬盘上,再次访问时就会把它发送到服务器。发送时并没有发送过期时间,因为服务器对过期时间并不关心,当COOKIE过期后浏览器就不会再发送它了。
如果使用IE6.0浏览器并且禁用COOKIE功能,可以发现服务器端的set-cookie还是有的,但客户端并不会接受它,也不会发送它。有些网站,特别是在线投票网站通过记录COOKIE防止用户重复投票,破解很简单,只要用IE6浏览器并禁用COOKIE就可以了。也有的网站通过COOKIE值为某值来判断用户是否合法,这种判断也非常容易通过手工构造HTTP消息头来欺骗,当然用HOSTS的方式也是可以欺骗的。
b.通过表单变量保持状态
除了Cookies之外,还可以使用表单变量来保持状态,比如Asp.net就通过一个叫ViewState的Input=“hidden”的框来保持状态,比如:
这个原理和Cookies大同小异,只是每次请求和响应所附带的信息变成了表单变量。
c.通过QueryString保持状态
这个原理和上述两种状态保持方法原理是一样的,QueryString通过将信息保存在所请求地址的末尾来向服务器传送信息,通常和表单结合使用,一个典型的QueryString比如:
www.xxx.com/xxx.aspx?var1=value&var2=value2
5.COOKIE和SESSION有什么区别
参考
COOKIE和SESSION有什么区别?
认识cookie与session的区别与应用
由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。当然这样不安全,浏览器也可以加密解密这样做,每个浏览器都可以有自己的加密解密方式,这样方便了用户,再比如用户喜欢的网页背景色,比如QQ空间的背景,这些信息也是可以通过cookie保存到客户端的,这样登录之后直接浏览器直接就可以拿到相应的偏好设置。
所以,总结一下:
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
注意不要混淆 session 和 session 实现。
本来 session 是一个抽象概念,开发者为了实现中断和继续等操作,将 user agent 和 server 之间一对一的交互,抽象为“会话”,进而衍生出“会话状态”,也就是 session 的概念。
而 cookie 是一个实际存在的东西,http 协议中定义在 header 中的字段。可以认为是 session 的一种后端无状态实现。
而我们今天常说的 “session”,是为了绕开 cookie 的各种限制,通常借助 cookie 本身和后端存储实现的,一种更高级的会话状态实现。
所以 cookie 和 session,你可以认为是同一层次的概念,也可以认为是不同层次的概念。具体到实现,session 因为 session id 的存在,通常要借助 cookie 实现,但这并非必要,只能说是通用性较好的一种实现方案。
6.TCP
默认情况下HTTP使用TCP,但是也可以基于以后存在的其他可靠传输协议。由于UDP无法提供可靠传输,所以不会使用UDP。UDP的不可靠传输加上HTTP的无记忆应答方式,那就是最糟糕的组合。举例就是你发送http请求访问网站,结果UDP给你丢了你还傻傻不知道UDP给你耍了。
HTTP协议是建立在TCP协议之上的一种应用,HTTP连接使用的是“请求—响应”的方式,不仅在请求时需要先建立TCP连接,而且需要客户端向服务器发出请求后,请求中包含请求方法、URI、协议版本以及相关的MIME样式的消息,服务器端才能回复数据,包含消息的协议版本、一个成功和失败码以及相关的MIME式样的消息。在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。由于HTTP在每次请求结束后都会主动释放连接,因此HTTP连接是一种“短连接”,要保持客户端程序的在线状态,需要不断地向服务器发起连接请求。通常的做法是即时不需要获得任何数据,客户端也保持每隔一段固定的时间向服务器发送一次“保持连接”的请求,服务器在收到该请求后对客户端进行回复,表明知道客户端“在线”。若服务器长时间无法收到客户端的请求,则认为客户端“下线”,若客户端长时间无法收到服务器的回复,则认为网络已经断开。
6.android HttpUrlConnection 简单例子
private void sendRequestWithHttpURLConnection(){
new Thread(new Runnable(){
public void run(){
HttpURLConnection connection = null;
try{
URL url = new URL("http://www.baidu.com");
connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(8000);
connection.setReadTimeout(8000);
InputStream in = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
StringBuilder response = new StringBuilder();
String line;
while((line = reader.readLine()) != null){
response.append(line);
}
Message message = new Message();
messsage.what = SHOW_RESPONSE;
message.obj = response.toString();
handler.sendMessage(message);
}catch(Execption e){
e.printStackTrace();
}finally{
if(connection != null){
connection.disconnect();
}
}
}
}).start();
}
五、Http和Socket
参考移动网络应用开发中,使用 HTTP 协议比起使用 socket 实现基于 TCP 的自定义协议有哪些优势
Http是应用层协议,TCP是传输层协议,HTTP是基于TCP的协议。HTTP好处就是标准化,文本化协议,可以非常方便的使用大量现有的框架代码资源,协议本身可读性较高;HTTP缺点就是性能比较差,无法做实时性要求较高的应用,例如实时游戏;而自定义协议,需要自己实现报文的切割,报文格式的定义,例如使用protobuff, 自己实现服务器,客户端网络架构,工作量大一些,但是可以做实时网络游戏。
1.优点
- HTTP 发展成熟
HTTP 几乎已经快成为一种通用的 Web 标准,Web Services、REST、Open API、OAuth 等等都是基于 HTTP 协议的。它已经不仅仅是 Hyper Text 的传输标准了,几乎所有数据的传输(多媒体、XML、JSON)都可以采用 HTTP。 - 后台复用
因为很多应用,除了有移动端,还有Web端,甚至桌面端。Web 版中前后台交互,无论是页面请求还是 AJAX 请求,都是采用标准 HTTP 协议。那么其他的客户端没有理由重新设计一套协议。 - HTML 5 应用
现在不少移动产品都采用或者半采用 HTML 5 技术,那么和服务器的交互又回归到 AJAX 上。不用说,还是离不开 HTTP。
2.局限性
- 实时数据推送
除了 iOS 开发提供有标准的 Apple 消息推送中心,其他移动产品可能还是要采用 Socket 长连接才能保证实时通讯。比较常见的有很多即时通讯软件采用的 XMPP 协议。 - 流媒体
适用于音频播放、视频播放、语音会议等等,一般可能采用 RTMP 协议。
六、RESTFUL
参考
怎样用通俗的语言解释什么叫 REST
理解RESTful架构-阮一峰
理解本真的REST架构风格
rest是架构设计风格,http是这个风格下的产物。不要用你的世界观YY出一个协议啦,你始终没有HTTP考虑的更全面,更易用,更有扩展性。
取东西就要GET(GET就是安全的,不会修改服务资源),新增就要POST(POST就是不安全的),修改就要PUT(PUT就要幂等),删除就是DELETE(DELETE就要幂等)....
优雅的展示你的资源,甚至让别人不看协议就能找到这个资源,这个世界岂不更简单Server提供的RESTful API中,URL中只使用名词来指定资源,原则上不使用动词。“资源”是REST架构或者说整个网络处理的核心。
看Url就知道要什么,看http method就知道干什么,看http status code就知道结果如何
比如:左边是错误的设计,而右边是正确的
GET /rest/api/getDogs --> GET /rest/api/dogs 获取所有小狗狗
GET /rest/api/addDogs --> POST /rest/api/dogs 添加一个小狗狗
GET /rest/api/editDogs/:dog_id --> PUT /rest/api/dogs/:dog_id 修改一个小狗狗
GET /rest/api/deleteDogs/:dog_id --> DELETE /rest/api/dogs/:dog_id 删除一个小狗狗
左边的这种设计,很明显不符合REST风格,上面已经说了,URI 只负责准确无误的暴露资源,而 getDogs/addDogs...已经包含了对资源的操作,这是不对的。相反右边却满足了,它的操作是使用标准的HTTP动词来体现。