看到今年的 SIGMOD17 上 Amazon 有一篇关于 Amazon Aurora 的 paper, 赶紧在周末的时候读了一下, 说不定哪天就 Aurora 就作为存储选型的一个 option 了, 要准备一下. 写点儿笔记
0x00 准备知识
这篇 paper 主要是关于 Aurora 如何将 MySQL 的 redo log 独立设计成一个存储服务, 从而提高了 Aurora 的吞吐的. 那么 MySQL 的 redo log 到底是什么?
redo log 就是 MySQL 的 WAL log, 是为了确保事务的持久性的. 每次事务提交前都需要确保 redo log 被持久化. 当数据库 crash 时, 会使用 redo log 进行 point-in-time recovery
需要注意的是: MySQL 中还有一个 binlog. redo log 和 binlog 不是一回事:
- binlog 是针对 MySQL 所有的引擎, 主要用来主从复制, 有
ROW和STATEMENT两种格式 - redo log 仅仅存在于 InnoDB 引擎, 用于记录每个页的改动情况.
从数据库架构上来说, 仅仅是将下图中的 Log Manager 中的一部分功能剥离出 MySQL, 做成一个高可用的服务, 其他部分不变.

0x01 为何要剥离 redo log
在存储和计算分离的大趋势下, 大家都是玩儿集群, 因此系统的瓶颈从之前的磁盘, 到现在变成了网络 IO. 如图常规情况下的 MySQL 集群网络 IO, 在 AWS 中一个常规使用 EBS 的主从 MySQL 集群, 网络 IO 是这样的:

独立出 redo log 服务后的 Aurora 集群, 网络 IO 是这样的:

也就是说 Aurora 仅仅需要把一个 Quorum 中的日志写成功就可以. 这种架构也有一个缺点: 放大了 replication 的 IO. 之前写 binlog 到 replica, 现在要写 redo log.
这么做的好处有3点:
- 将存储服务做成一个跨数据中心的服务, 提高数据库容灾, 降低性能影响
- 大幅度将低网络 IO, 为其他优化腾出了空间
- 之前备份等操作都很 expensive, 现在在单独的存储服务上, 都不是事儿
文中给了一个网络 IO 对比的数据:
Table 1: Network IOs for Aurora vs MySQL
| Configuration | Transactions | IOs/Transaction |
|---|---|---|
| Mirrored MySQL | 780,000 | 7.4 |
| Aurora with Replicas | 27,378,000 | 0.95 |
0x02 durability at scale: 规模化的 durability
如何确保数据的 durablity? 多写几份呗. 基于 Quorum 机制, 常规来说仅仅需要满足如下公式:
- Vr + Vw > V
- Vw > V/2
而且一般情况下, 大家都是选择 V=3, Vr = 2, Vw=2 (也就是说数据存储3份: 写入2份成功才算成功, 读取2份成功才算成功).
但 Aurora 认为使用3个AZ(AZ 就是 AWS 的机房的概念)每个 AZ 一份数据的情况不靠谱, 因此选择3个 AZ 存储 6 分数据: 每个 AZ 2份:
- V = 6
- Vw = 4
- Vr = 3
这样能够保证一个机房故障, 并且剩余两个机房有一个节点故障的情况下可用.
为了提高 MTTR(Mean Time To Repair) 时间, 还把存储每10 GB 作为 Protection Group, 自我修复, 提高修复时间.
0x03 存储服务设计
说到存储服务的设计, 核心的原则就是 latency 一定要低. 把能异步做的事情都异步都后台做, 数据一旦落地立即返回. 如图:
- LOG 请求进来, 落地就从
2返回, 尽最大可能降低 latency -
4是通过 Gossip 协议, 与其他 peer 通信, 修复数据

0x04 Aurora 性能
我也没有实际用过 Aurora, 贴一张 paper 中的数据吧
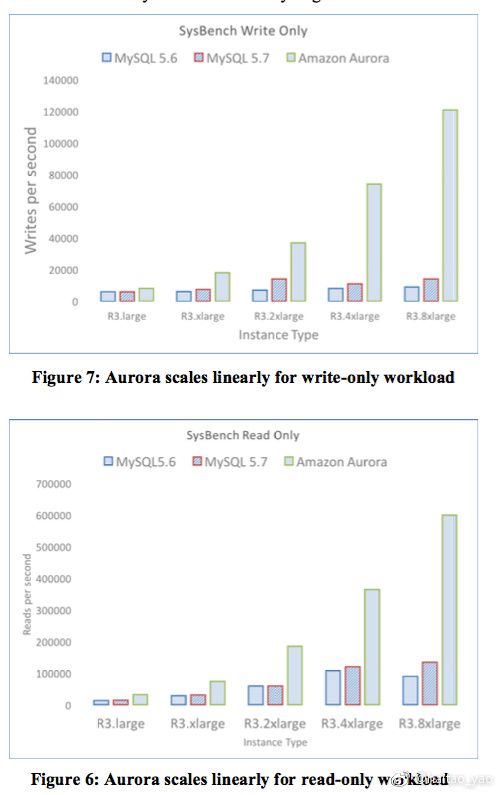
0x05 疑问
关于 binlog
看完 Aurora 的设计, 有一点疑惑的是, 主从复制使用了 redo log, 那么原生的 binlog 在 Aurora 中是否还存在? 找了一下文档, 发现 binlog 还是在的, 参见 Replication Between Aurora and MySQL or Between Aurora and Another Aurora DB Cluster
关于 MySQL 新 feature
另外一个疑惑就是关于 MySQL 新版本的 feature. 如果 MySQL 社区版本推出了一个新的 feature, Aurora 何时能够跟进并提供相应的功能(比如 JSON 字段类型)? 其实 Aurora 到底是基于哪个版本的 MySQL 的 source code 构建的, 我们也不得而知.
0x06 总结
存储计算分离, 连 OLTP 的数据库都在按照这个思路拆. Aurora 不仅仅止步于 MySQL, 去年的 re:Invent 2016 上发布了 Aurora 兼容 PostgreSQL 的版本. 至于 Aurora 怎么评价, 可以摘一句 Percona co-founder 的一句:
In general I think Amazon Aurora is a quite advanced proprietary version of MySQL. It is not revolutionary, however, and indeed not “reimagined relational databases” as Amazon presents it. This technology does not address a problem with scaling writes, sharding and does not handle cross-nodes transactions.
-- by Vadim Tkachenko
我个人倒是觉得, 反正我也不去写数据库(我也不会写), 是否 re-invent 数据库我不管, 能够让我不用分库分表, 价格还让我老板满意我就开心.
Reference
- MySQL · 引擎特性 · InnoDB redo log漫游
- Amazon Aurora – Looking Deeper
- 阿里云、Amazon、Google云数据库方案架构与技术分析
-- EOF --