链接:
1. 线性回归总结
2. 正则化
3. 逻辑回归
4. Boosting
5. Adaboost算法
一. 过拟合
从下图中可以看出在这三种拟合线条中一般线性拟合效果最差,只是描绘出了一种趋势,四次多项式拟合效果很完美,完全覆盖了训练集中的点。但是从实际来说数据时存在各种偏差的,肯定存在一些杂质或者误差,它在完美的拟合数据的同时意味着将这种误差也拟合在内,这种的结果是在测试集中会存在明显的差别,可能效果很差,我们需要拟合的不是误差,而是数据中的共性,存在的规律。
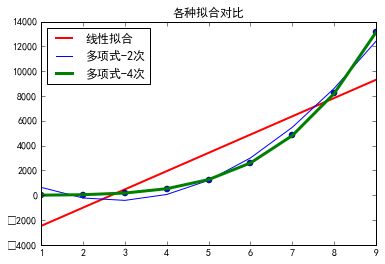
此时存在两种问题:
- 如一般线回归合下发生的欠拟合:并没有很好地找到数据的规律
- 如四次多项式回归下发生的过拟合:过多的将不需要的性质加入回归。如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集(能拟合几乎所有的训练数据),但这也就面临函数可能太过庞大的问题,变量太多。同时如果我们没有足够的数据集(训练集)去约束这个变量过多的模型,那么就会发生过拟合。
过度拟合的问题通常发生在变量(特征)过多的时候。这种情况下训练出的方程总是能很好的拟合训练数据,也就是说,我们的代价函数可能非常接近于 0 或者就为 0。但是,这样的曲线千方百计的去拟合训练数据,这样会导致它无法泛化到新的数据样本中,

二. 处理方式
那么,如果发生了过拟合问题,我们应该如何处理?
过多的变量(特征),同时只有非常少的训练数据,会导致出现过度拟合的问题。因此为了解决过度拟合,有以下两个办法。
- 人工选择减少特征数目
- 通过机器学习算法之类的算法去选取主要特征,放弃次要特征
- 正则化:不去减少特征,而是通过优化配置参数θ去实现消除过拟合
正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响比如我们有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。

在论文中常见的都聚集在:零范数、一范数、二范数、迹范数、Frobenius范数和核范数等等
L0范数与L1范数
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。为什么L1范数会使权值稀疏?有人可能会这样给你回答“它是L0范数的最优凸近似”。实际上,还存在一个更美的回答:任何的规则化算子,如果他在Wi=0的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。这说是这么说,W的L1范数是绝对值,|w|在w=0处是不可微,但这还是不够直观。这里因为我们需要和L2范数进行对比分析。
既然L0可以实现稀疏,为什么不用L0,而要用L1呢?因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。

OK,来个一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。它能实现特征的自动选择和有很好的可解释性。
L2范数
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。为什么越小的参数说明模型越简单?我也不懂,我的理解是:限制了参数很小,实际上就限制了多项式某些分量的影响很小(看上面线性回归的模型的那个拟合的图),这样就相当于减少参数个数。其实我也不太懂,希望大家可以指点下。
这里也一句话总结下:通过L2范数,我们可以实现了对模型空间的限制,从而在一定程度上避免了过拟合。
当然,采用正则化以后之前的矩阵求系数W就可以解决:

lasso回归效果(一范数):
![lasso回归]
](http://upload-images.jianshu.io/upload_images/1070582-fc992c96c6abb03a.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
Ridge回归效果(二范数):
# -*- coding: utf-8 -*-
"""
Created on Thu May 04 20:08:49 2017
@author: SUNFC
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
#x = np.arange(1,10,2).reshape(-1,1)
x = np.arange(1,10)
y = 2 * x*x*x*x + 10
random_num = np.random.randn(x.shape[0]) * 10
y = y + random_num
x = x.reshape(-1,1)
# 线性回归
linear_model = LinearRegression()
linear_model.fit(x,y)
y_pre = linear_model.predict(x)
plt.plot(x,y_pre,'r-',linewidth=2, label=u"线性拟合")
plt.plot(x,y, 'bo')
# 二项式回归
quadratic_featurizer = PolynomialFeatures(degree=2)
xx = quadratic_featurizer.fit_transform(x)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(xx, y)
plt.plot(x, regressor_quadratic.predict(xx), 'b-', label=u"多项式-2次")
# 四项式回归
quadratic_featurizer = PolynomialFeatures(degree=4)
xx = quadratic_featurizer.fit_transform(x)
regressor_quadratic = LinearRegression()
regressor_quadratic.fit(xx, y)
plt.plot(x, regressor_quadratic.predict(xx), 'g-', lineWidth=3, label=u"多项式-4次")
plt.title(u'各种拟合对比')
plt.legend(loc='upper left')
# plt.show()
# lasso拟合
plt.plot(x,y,'ro')
quadratic_featurizer = PolynomialFeatures(degree=4)
xx = quadratic_featurizer.fit_transform(x)
lasso_quadratic = Lasso()
lasso_quadratic.fit(xx, y)
plt.plot(x, lasso_quadratic.predict(xx), 'r-', lineWidth=3, label=u"lasso")
plt.title(u'lasso拟合')
plt.legend(loc='upper left')
plt.show()
# Ridge拟合
plt.plot(x,y,'ro')
quadratic_featurizer = PolynomialFeatures(degree=4)
xx = quadratic_featurizer.fit_transform(x)
ridge_quadratic = Ridge()
ridge_quadratic.fit(xx, y)
plt.plot(x, ridge_quadratic.predict(xx), 'r-', lineWidth=3, label=u"lasso")
plt.title(u'Ridge拟合')
plt.legend(loc='upper left')
plt.show()