首先来看一下在 C语言程序是如何经过处理变成可执行程序的:

C代码(.c) - 经过编译器预处理,编译成汇编代码(.asm) - 汇编器,生成目标代码(.o) - 链接器,链接成可执行文件(.out) - OS将可执行文件加载到内存里执行.
目标文件的格式ELF
EXECUTABLE AND LINKABLE FORMAT 可执行的和可链接的格式(是文件格式的标准)
.o文件 和 可执行文件,都是目标文件,一般使用相同的文件格式
ABI和目标文件格式是什么关系
目标文件也叫做ABI,应用程序二进制接口。实际上在目标文件里面,它已经是二进制兼容的格式。而什么叫二进制兼容呢?所谓的二进制兼容,就是指这个目标文件已经是适应某一种CPU体系结构上的二进制的指令,比如在32位x86环境下编译出来的目标文件,链接成ARM上的可执行文件,那肯定是不可以的
ELF文件里面三种目标文件
一个可重定位(relocatable)文件保存着代码和适当的数据,用来和其它的object文件一起来创建一个可执行文件或者是一个共享文件(主要是.o文件)
一个可执行(executable)文件保存着一个用来执行的程序,该文件指出了exec(BA_OS)如何来创建程序进程映象(操作系统怎么样把可执行文件加载起来并且从哪里开始执行)
一个共享object文件保存着代码和合适的数据,用来被下面两个链接器链接:(主要是.so文件)第一个是链接编辑器(静态链接)【请参看ld(SD_CMD)】,可以和其它的可重定位和共享object文件来创建其它的object第二个是动态链接器,联合一个可执行文件和其它的共享object文件来创建一个进程映象
ELF的目标文件格式
Object文件参与程序的链接(创建一个程序)和程序的执行(运行一个程序)
一个ELF头在文件的开始,保存了路线图(road map),描述了该文件的组织情况程序头表(Program header table)告诉系统如何来创建一个进程的内存映像Section头表(Section header table)包含了描述文件Sections的信息。每个Section在这个表中有一个入口,每个入口给出了该Section的名字,大小等信息
链接视图,有很多Section,执行视图,有很多段(Segment)
大多数文件格式也都是这种模式,在头记录了一些元数据,用readelf命令来详细查看ELF文件头
可执行程序加载的主要工作
当创建或增加一个进程映象的时候,系统在理论上将拷贝一个文件的段到一个虚拟的内存段
可执行文件有一个头部,里面有一些关键信息,Entry point Address,入口地址,即程序的起点,0x8048300,后面有一些代码,数据
对于进程来讲,进程有一个进程地址空间,而对于32位x86体系结构来讲,进程有4G的进程地址空间(逻辑地址),3G以上的地址空间只能在内核态下访问,在用户态的时候,只能访问0到3G的地址空间。
ELF可执行文件加载到内存的位置 与 ELF可执行文件加载到内存中开始执行的第一行代码
ELF可执行文件默认加载到内存0x8048000这个位置,从这个位置开始加载。前面加载ELF可执行文件的头部信息,但因不同文件大小不同,程序的实际入口为:0x8048x00,图例为0x8048300,也就是说这个位置是程序的实际入口地址,即刚加载过可执行文件的进程(一个进程加载了新的可执行文件之后,开始执行的入口点),就是从这个地方开始执行
简略地来看,图例里的文件是ELF的静态链接文件。静态链接的时候,会将所有代码放在一个代码段,把所有的链接都链接好了,所以从0x8048300开始一行行代码执行,压栈出栈,把整个程序执行完而实际上如果需要用到共享库,需要动态链接的话,会有多个代码段,情况会更复杂(暂不研究)
装载可执行程序之前的工作最主要的是两大部分:
- 可执行程序的文件格式
- 可执行程序的执行环境
一般是通过shell程序启动一个可执行程序,shell程序具体做了什么?而当启动加载一个可执行程序的时候,也就是发起一个系统调用execve,shell环境准备了哪些执行的上下文环境(用户态的执行环境)
再看看execve系统调用怎么样把一个可执行文件在内核态里面装载起来,装载起来后又返回到用户态(内核态的执行环境)
可执行程序的执行环境(Shell命令行、main函数的参数与execve的参数)
$ ls -l /usr/bin 列出/usr/bin下的目录信息,
Shell本身不限制命令行参数的个数,命令行参数的个数受限于命令自身例如,
int main(int argc, char *argv[]) -- 愿意接收命令行参数又如,int main(int argc, char *argv[], char *envp[]) -- 愿意接收shell的环境变量.
前两个参数由用户输入命令的时候设定-l /usr/bin,后一个是shell环境,shell程序自动加上
命令行参数和环境变量是如何保存和传递的?
先函数调用参数传递,再系统调用参数传递
Shell程序 -> execve -> sys_execve,然后在初始化新程序堆栈时拷贝进去
命令行参数和环境串都放在用户态堆栈中
当fork一个子进程的时候,复制父进程,调用execve系统调用的时候,要加载的可执行程序把原来的进程的环境覆盖掉了,覆盖掉之后它的用户态堆栈也被清空了,因为它是个新的程序要执行,那么argv和envp是如何进入新程序的用户态堆栈的?即命令行参数和环境变量是如何进入新程序的堆栈的?
在创建一个新的用户态堆栈的时候,实际上是把命令行参数的内容和环境变量的内容通过指针的方式传递到execve系统调用的内核处理函数,然后内核处理函数在创建可执行程序新的用户态堆栈的时候,会把参数拷贝到用户态堆栈里,初始化新的可执行程序的上下文环境。所以,新的程序能从main函数开始,把对应的参数接收过来,然后执行。但原先在调用execve时,参数只是压在了shell程序当前进程的堆栈上,而这个堆栈在加载完新的可执行程序之后,已经被清空了,内核又创建了一个新进程的用户态堆栈
如果仅仅只是加载一个静态链接的可执行程序的话,只需要传递一些命令行参数,一些环境变量,可执行程序就可以正常地工作。但是对于绝大多数的可执行程序来讲,还有一些对动态链接库的依赖,这个比较复杂。
传统的系统调用都是陷入到内核态,然后再返回到用户态,继续执行系统调用下面的指令
fork系统调用进入到内核态,两次返回,在父进程中,返回到父进程原来的位置继续向下执行,这个和传统的系统调用是一样的。在子进程中,构造了它的堆栈环境,子进程返回到特定的点,是从ret_from_fork开始执行然后返回到用户态,对于子进程来讲比较特殊
execve系统调用,当前的可执行程序在执行,执行到execve系统调用时候,陷入到内核态,在内核里面,用execve加载的可执行文件,把当前进程的可执行程序给覆盖掉了,当execve系统调用返回的时候,已经不是返回到原来的可执行程序了,是新的可执行程序的执行起点,也就是main函数大致的位置,那么main函数的执行环境,也就需要我们来构建好加载的新的可执行程序的执行环境
sys_execve内核处理过程
当execve系统调用陷入到内核里的时候,system_call,调用了sys_execve(),sys_execve内部会解析可执行文件格式,后面的调用顺序:do_execve -> do_execve_common -> exec_binprm
search_binary_handler根据文件头部信息寻找对应的文件格式处理模块,如下:
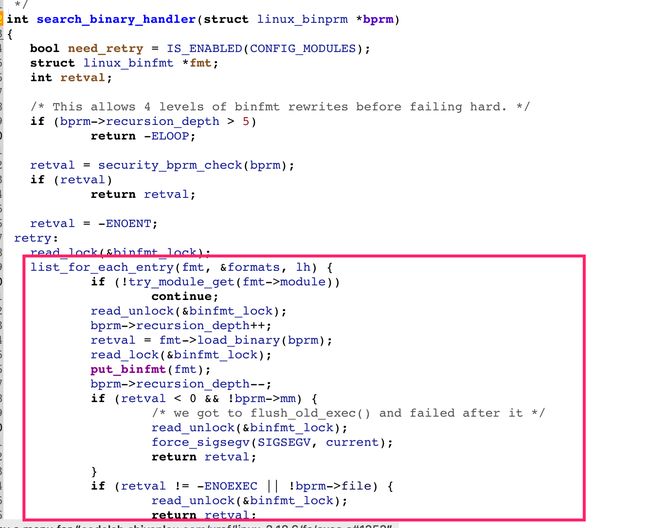
根据我们给出的文件名,加载了文件的头部,判断文件是什么格式,在列表中寻找能够解释ELF格式的内核模块
对于ELF格式的可执行文件fmt->load_binary(bprm);执行的应该是load_elf_binary其内部是和ELF文件格式解析的部分需要和ELF文件格式标准结合起来阅读
当ELF文件格式出现的时候,观察者就能自动执行load_elf_binary,但实际上是在retval = fmt->load_binary(bprm)执行,这个地方实际上是一种多态的机制,本质上是一种观察者模式
动态调试时中断在 load_elf_binary,如下所示:

在start_thread函数中,将中断返回后的 ip 和 sp 设置成了特定的新值,以便执行新的程序逻辑.

调试时也会中断在该函数,并可以查看新的 ip 地址.
start_thread这个函数有一个pt_regs,一个new_ip,一个new_sp
pt_regs实际上就是内核堆栈的栈底的那部分,发生系统调用int 0x80的时候,把eflags、sp、ip都压入到栈。那么新进程执行的时候,需要把它的起点位置给它替换掉
new_ip是怎么来的呢?
看一下load_elf_binary in /linux-3.18.6/fs/binfmt_elf.c#571
975 start_thread(regs, elf_entry, bprm->p);
elf_entry,对于一个静态链接的可执行文件,就是可执行文件里的Entry point address,可执行文件头部定义的起点
在一个新的可执行程序返回到用户态之前,需要修改int 0x80压入内核堆栈的EIP,用新的可执行程序的起点来修改,但是对于动态链接的过程又更复杂一些,先理解静态链接的过程,大致是这样
看一下do_execve_common
/linux-3.18.6/fs/exec.c#do_execve_common
打开要加载的可执行文件,然后加载文件头部
1474 file = do_open_exec(filename);
创建结构体,bprm
1481 bprm->file = file;
1482 bprm->filename = bprm->interp = filename->name;
把环境变量和参数都copy到结构体里面
1505 retval = copy_strings(bprm->envc, envp, berm);
1509 retval = copy_strings(bprm->argc, argv, berm);
对可执行文件的处理过程
1513 retval = exec_binprm(berm);
看一下exec_binprm /linux-3.18.6/fs/exec.c#exec_binprm
寻找可执行文件的处理函数
1416 ret = search_binary_handler(bprm);
看一下search_binary_handler /linux-3.18.6/fs/exec.c#1352
寻找能够解释当前可执行文件的代码模块
如果该程序需要动态链接,则elf_interpreter指针不为空,并指向对应的 ld 文件.内核则加载此文件,由该文件进行动态链接,并最终跳入程序头文件中制定的入口点.如下图所示:

所以后面在start_thread的时候就会有两种可能
975 start_thread(regs, elf_entry, bprm->p);
如果是一个静态链接文件的话,elf_entry就是指向Entry point address的位置0x8048x00如果是一个需要依赖动态链接库的话,需要ld链接器,elf_entry就是指向动态链接器的起点
浅析动态链接的可执行程序的装载
对于一般的可执行程序来讲,大多都是需要使用动态链接库,动态链接库最常见的就是libc,动态链接器ld它也是libc的一部分。那么在动态链接的过程,内核做了什么?
ELF格式里面要依赖其它的动态链接库,动态链接库某一个.so本身(它也是一个ELF格式的文件)还可能会依赖其它的动态链接库,因此实际上动态链接库的依赖关系会形成一个图。在解释每一个ELF格式文件的时候,看它依赖了哪些动态链接库,这样它就会加载
那么谁负责加载呢?
阅读内核代码的时候,可以看到,当这个文件需要用elf_interpreter的话,也就是说它需要依赖动态链接器来解释这个ELF文件,那么它就需要加载load_elf_interp,实际上是加载动态连接器ld,那么这时候Entry point address,也就是说在返回到用户态的时候,它返回的就不是这个可执行程序文件规定的起点,它返回的是动态连接器的程序入口,动态连接器负责解释当前的可执行文件,看它里面依赖哪些动态链接库,然后把那些动态链接库一个一个加载进来,加载进来之后再解释加载进来的动态链接库,看它这个动态链接库还依赖哪些文件,这样就有一个叫广度遍历的方法(即动态链接库的装载过程是一个图的遍历),把所有的动态链接库都装载起来,装载起来之后ld再负责把CPU的控制权移交给可执行程序头部规定的起点位置
那么从以上分析看出,动态链接的过程不是由内核来完成的,主要是由动态链接器来完成的,动态链接器是libc的一部分,是在用户态做的事情