1.Scrapy爬虫框架介绍
2.Scrapy爬虫框架解析
3.requests库和Scrapy爬虫比较
4.Scrapy爬虫的常用命令
5.单元小结
网页链接【Python网络爬虫与信息提取】.MOOC. 北京理工大学
https://www.bilibili.com/video/av9784617/?from=search&seid=10703466871670873351#page=51
最近更新:2018-01-22
1.Scrapy爬虫框架介绍
1.1scrapy的安装
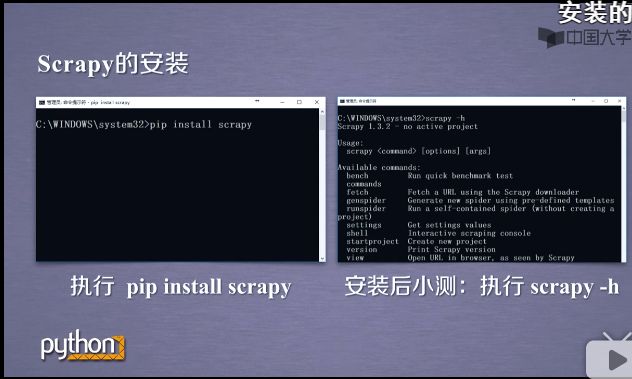
注意:
- 这里的安装过程中,我出现了twisted错误,后面参照了知乎XP LEE的 的方法才安装好
原链接是https://www.zhihu.com/question/52281800
1.2scrapy爬虫框架结构
1.2.1爬虫框架
scrapy不是一个函数功能库,而是一个爬虫框架

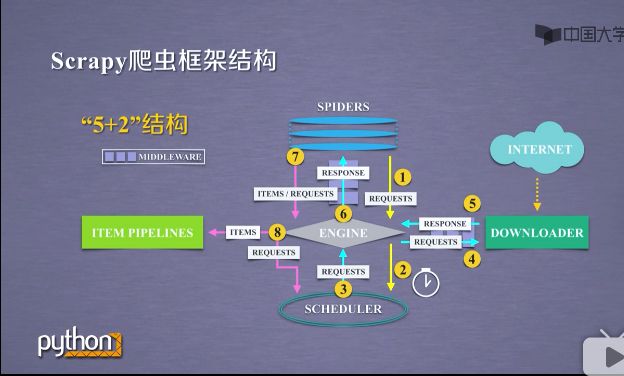
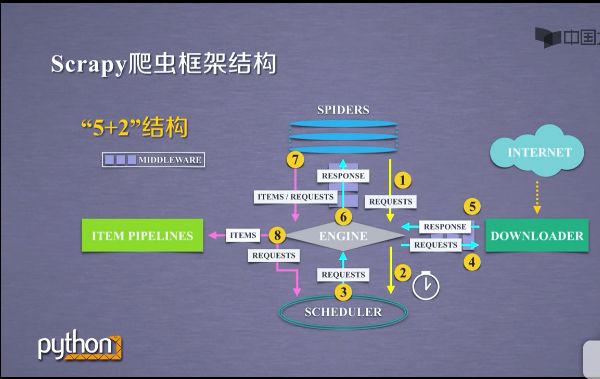
1.2.2"5+2"结构
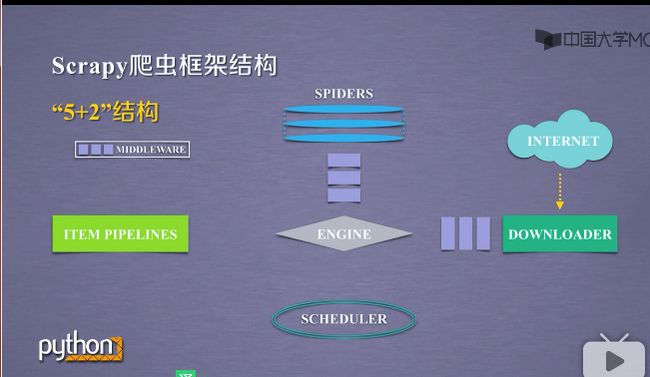
- 这五个模块分别包括SPIDERS,DOWNLOADER,SCHEDULER,ITEM PIPELINES,ENGINE. ENGINE与SPIDERS之间,ENGINE与DOWNLOADER之间出现中间键模块.这五个模块形成的结构叫做scrapy爬虫框架.
-
在这5个模块之间,包括数据用户提交的网络爬虫请求以及网络上获取的相关内容,在这些结构之间进行流动.形成了数据流.scrapy爬虫框架包含三条主要的数据流途径,具体如下:
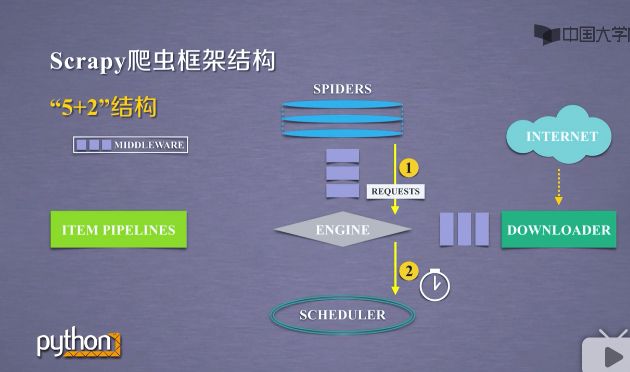
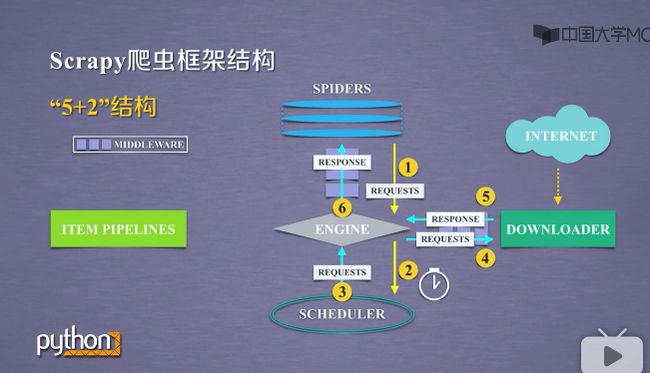
1 )第一条数据流途径(1-2),如下截图
a )是从SPIDERS经过ENGINE到达SCHEDULER.其中ENGINE从SPIDERS那里获得爬取用户的请求,我们把这种请求叫requests,可以把请求简单理解为url.
b )请求从SPIDERS到达ENGINE之后,ENGINE把请求转发给SCHEDULER模块.
c )SCHEDULER模块是负责爬取请求进行调度.
2 )第二条数据流途径(3-4-5-6),如下截图
a )是从SCHEDULER通过ENGINE模块到达DOWNLOADER模块,并将数据最终返回SPIDERS模块.
b )这个路径的作用是ENGINE从SCHEDULER那里获得下一个要爬取的请求,这时候的网络请求是真实的,要去网络上爬取的请求.ENGINE获得这样的请求后通过中间键发送给DOWNLOADER模块.
c )DOWNLOADER模块拿到这样的请求之后,真实的连接互联网,并且爬取相关的网页,爬取网页之后,DOWNLOADER模块将爬取的内容形成一个对象,这个对象叫响应,叫response,将所有的内容封装成response之后.
d )将这个响应再通过中间键ENGINE发送给SPIDERS.
e)这条路径中真实的爬取url的请求,经过SCHEDULER,DOWNLOADER,最终返回相关内容,到达SPIDERS
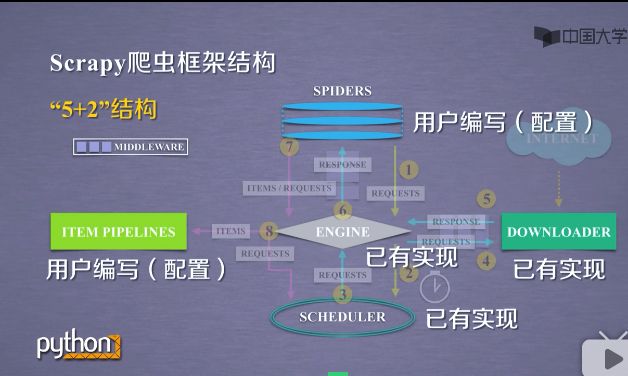
3)第三条数据流途径(7-8),如下截图
a )从SPIDERS模块经过ENGINE模块到达ITEM PIPELINES模块.以及SCHEDULER模块.
b )SPIDERS处理从DOWNLOADER获得的响应,也就是从网络当中爬取了相关的内容.处理之后产生了两种数据类型,一个数据类型是爬取项,叫srcpyitems,也叫items.另外一个是新的爬取请求,也就是说从网上获得一个网页之后,如果网页有其他的链接,也是我们十分感兴趣的,可以在SPIDERS之间增加相关的功能,对新的链接再次发生爬取.
c )SPIDERS生成这两种数据类型之后,将它们发送给ENGINE模块,ENGINE模块收到两类数据之后,将items发送给ITEM PIPELINES模块.
d )将其中的requests发送给SCHEDULER模块进行调度.从而为后续的处理,以及再次启动网络爬虫请求,提供了新的数据来源.

-
scrapy框架主要有三条数据流路径,可以看到ENGINE模块控制着各个模块的数据流,不断的从SCHEDULER获得真实要爬取的请求,并将请求发送给DOWNLOADER.整个框架的执行,是从ENGINE发送第一个请求开始到获得所有链接的内容并将内容处理后,放到ITEM PIPELINES为止.
 2018-01-22_161122.png
2018-01-22_161122.png
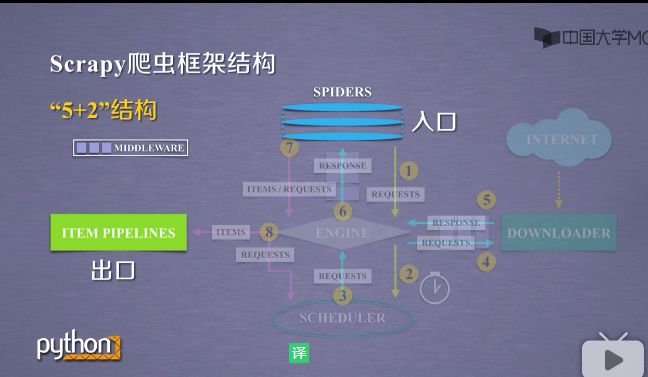
1.2.3爬虫框架汇总
- 这个框架的入口是SPIDERS,出口是ITEM PIPELINES模块.
- 在这框架中,scrapy是5+2结构,其中ENGINE,DOWNLOADER,SCHEDULER是已有的模块.用户不需要编写它,会按照既定的功能,去完成它的任务.
- 用户需要编写的是SPIDERS和TEM PIPELINES模块.
- 其中SPIDERS是整个框架要提供的url,同时要解析从网上获得页面的内容.
- 而ITEM PIPELINES模块负责对提取的信息进行后处理.
-
由于在这个框架下用户编写的并不是完整的大篇的代码,对SPIDERS和TEM PIPELINES已有的模版进行编写.我们也将这种方法叫做配置.相当于用户在scrapy框架下,经过简单的配置,就可以实现这个框架下的运行功能,就可以完成用户的需求.
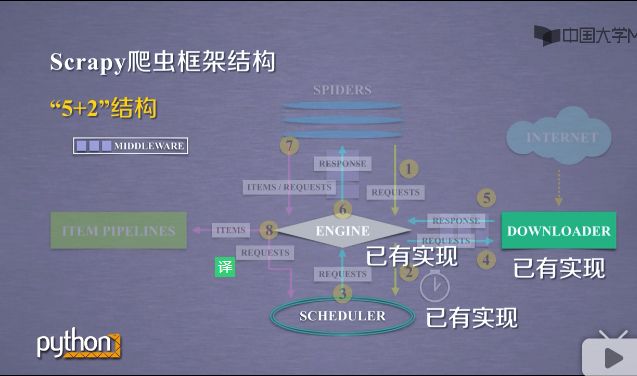
2.Scrapy爬虫框架解析
有5个模块加2个中间键
2.1Engline模块
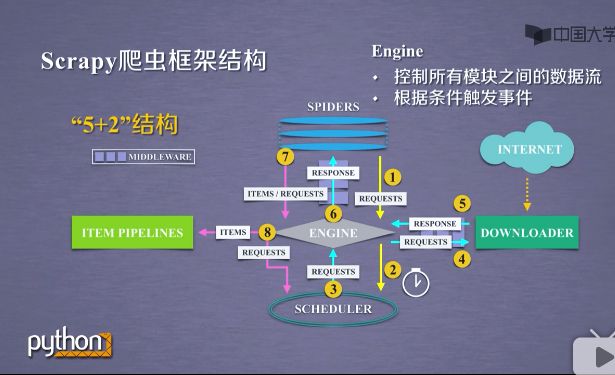
- 整个框架最中心的位置是Engline模块,是整个框架的核心.
- Engine是控制所有模块之间的数据流.任何模块与模块的数据流动都是要经过Engine模块的调度,同时根据模块之间的事件,进行触发.
- Engine模块相当于一个发动机,所以起的名字叫Engine.
-
这个模块不需要用户修改.遵循框架的方式编写代码,那么这个模块不需要管.
 2018-01-22_162729.png
2018-01-22_162729.png
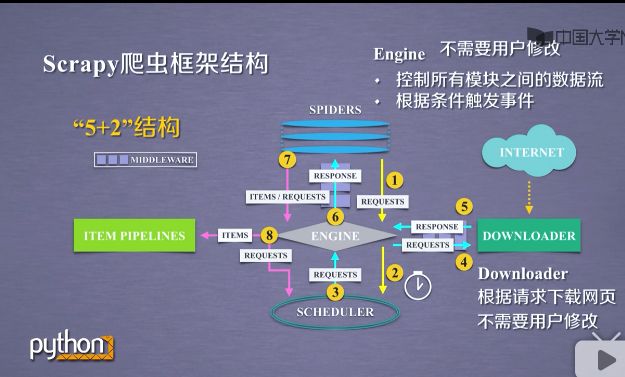
2.2Downloader模块
- 根据用户的请求下载网页,功能比较单一.只是获得一个请求,并向网络提交这个请求.最终获得返回相关内容.
-
功能比较固定和简单,scrapy已将它实现的非常好.用户不需要修改.
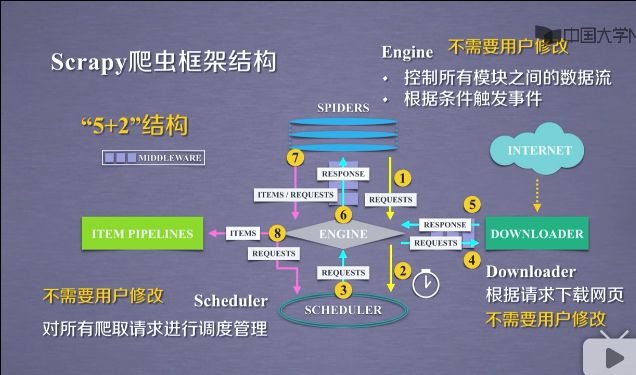
2.3Scheduler模块
- 对所有的爬取请求进行调度管理,对一个中规模爬虫,可能一时间有很多很多的爬取请求,这个请求比如哪些先访问,哪些该后面访问,这些就是由Scheduler模块进行调度.
-
调度的方法和功能相对固定,因此用户也不需要修改.

2.4Engline模块,Downloader模块,Scheduler模块汇总
- 可以看到Engline模块,Downloader模块,Scheduler模块这三个都不需要用户进行修改.
-
三个模块放在一起形成一个功能,由Scheduler模块发送访问请求,经过Engline模块到达Downloader模块.
2.5Downloader Middleware
- 用户希望对请求做一定的配置,一定的定义,该怎么办?scrapy在这三个模块之间,最主要是在Engline模块到达Downloader模块之间,增加了一个中间键,这个中间键叫Downloader Middleware.
- 比如一个Scheduler希望网络上提交访问请求,比如访问百度网站,用户可以编写代码在Downloader Middleware将这样的网络请求拦截下来,修改为雅虎等等.
- Downloader Middleware这个用户可以编写配置代码.
-
用户不需要对requests或responses进行修改的时候,用户可以不更改这个中间键.

2.6spider
- 能够解析Downloader返回的响应(response)
- 能够产生爬取项(scraped item)
- 产生额外的爬取请求(request)
- 简单说它向整个框架,提供了最初始的访问链接,同时对每次爬取回来的内容进行解析,再次产生新的爬取请求.并从内容中分析出,提取出相关的数据,是整个爬虫框架最核心的一个单元.
-
用户需要编写的就是这个模块中的相关代码.
2.7Item Pipelines
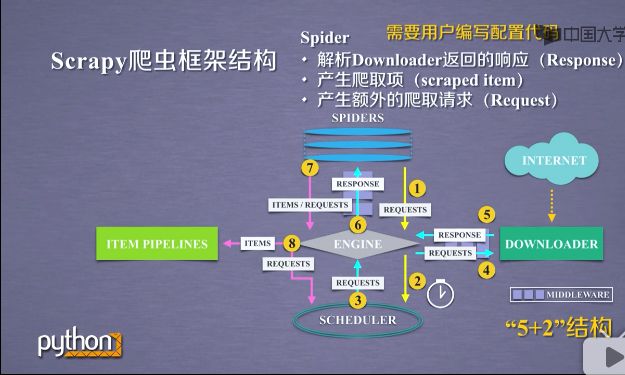
- 以流水线的方式处理Spider产生的爬取项.也是就是说spider产生了对爬取之后的信息,这个信息在爬取项目中,经过一个又一个的功能模块,以流水线的方式处理起来.所以叫Item Pipelines.
- 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型.Item Pipeline是由一组操作顺序组成的,每组操作对Item进行处理.
- 可能操作包括:清理/检验和查重爬取项中的HTML数据.将数据存储到数据库.甚至前面的功能模块可以去掉items的功能模块.
-
Item Pipeline完全由用户编写的.
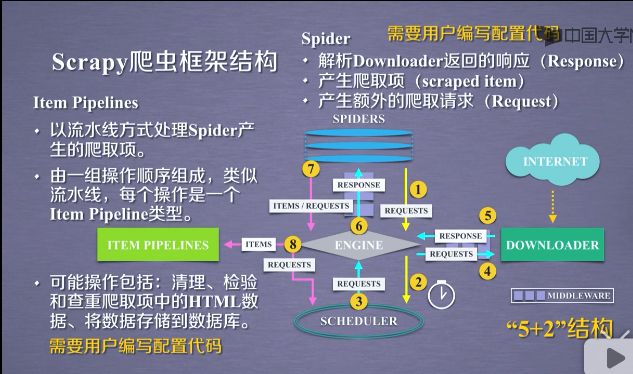
- 用户需要关心的是对于网页提取的信息,这些以item类型封装的信息,用户需要怎么做,尤其是将数据存储到数据库里面,还是经过简单的清洗.用在什么地方,这些都是需要在Item Pipeline中来实现
2.8Spider Middleware中间键

2.9Scrapy爬出框架知识汇总
- 重点编写Item Pipelines和spiders模块
-
为了操作数据流,对数据流进行一定的控制,可以通过两个中间键,对其中的request和response和items做一定的操作.
3.requests库和Scrapy爬虫比较
3.1requests vs. Scrapy相同点
都是重要的第三方爬虫库,如果都是网站存在验证码都是无法应对,因此需要扩展新的库.

3.2requests vs. Scrapy不同点

- 如果爬取个别网页requests非常合适,如果批量的爬取大量的网页,建议使用scrapy.
- requests是功能库由函数构成,scrapy是个框架,很多函数非用户定义和使用,更多支撑爬虫的一个整体结构.
- requests并发性不足,性能较慢.而scrapy并发性好,性能较高,可以多个网站爬取请求.(注意:网络爬虫的爬取的快与慢,只是一个参数,对于成熟的网站都有反爬虫技术,反爬虫技术要求爬虫爬取的速度不能太快.太快就会被反爬虫技术发现,并屏蔽某些IP的请求.爬取的速度好与坏要结合一定的情况进行考虑.)
- requests重点在于页面下载,scrapy爬虫结构.所以说scrapy是配置型的代码编写.
- requests库使用灵活,代码嵌入怎么使用都可以.而scrapy库对于一般使用还算灵活,但深度定制的时候反而存在障碍.
- requests上手十分简单,而scrapy库稍微难一点.
3.3两个库的选择

4.Scrapy爬虫的常用命令
4.1Scrapy命令行

4.2Scrapy命令行格式

-
Scrapy常用命令
 2018-01-22_173220.png
2018-01-22_173220.png - 在scrapy下,一个工程是一个最大的单元,一个工程可以是相当于一个大的scrapy框架.而在scrapy框架中可以有多个爬虫,每一个爬虫相当于框架中的一个spider模块.需要理解工程与爬虫的不同.
-
最常用是其中的三个命令.

4.3Scrapy爬虫的命令行逻辑
Scrapy不是给用户操作使用的,更多是后台的爬虫框架.对于程序而言,更关心的是一个个的指令.通过命令行,程序就可以通过程序进行接收.只有用户才会关心图像界面.

4.单元小结
