链表的简单介绍
为什么需要线性链表
当然是为了克服顺序表的缺点,在顺序表中,做插入和删除操作时,需要大量的移动元素,导致效率下降。
线性链表的分类
- 按照链接方式:单链表、循环链表、双链表
- 按照实现角度:静态链表、动态链表
线性链表的创建和简单遍历
算法思想
创建一个链表,并对链表的数据进行简单的遍历输出。
算法实现
# include
# include
typedef struct Node
{
int data;//数据域
struct Node * pNext;//指针域 ,通过指针域 可以指下一个节点 “整体”,而不是一部分;指针指向的是和他本身数据类型一模一样的数据,从结构体的层面上说,也就是说单个指向整体,(这里这是通俗的说法,实施情况并非是这样的)下面用代码进行说明。
}NODE,*PNODE; //NODE == struct Node;PNODE ==struct Node *
PNODE create_list(void)//对于在链表,确定一个链表我们只需要找到“头指针”的地址就好,然后就可以确认链表,所以我们直接让他返回头指针的地址
{
int len;//存放有效节点的个数
int i;
int val; //用来临时存放用书输入的节点的的值
PNODE pHead = (PNODE)malloc(sizeof(NODE)); //请求系统分配一个NODE大小的空间
if (NULL == pHead)//如果指针指向为空,则动态内存分配失败,因为在一个链表中首节点和尾节点后面都是NULL,没有其他元素
{
printf("分配内存失败,程序终止");
exit(-1);
}
PNODE pTail = pHead;//声明一个尾指针,并进行初始化指向头节点
pTail->data = NULL;//把尾指针的数据域清空,毕竟和是个结点(清空的话更符合指针的的逻辑,但是不清空也没有问题)
printf("请您输入要生成链表节点的个数:len =");
scanf("%d",&len);
for (i=0;i < len;i++)
{
printf("请输入第%d个节点的值",i+1);
scanf("%d",&val);
PNODE pNew = (PNODE)malloc(sizeof(NODE));//创建新节点,使之指针都指向每一个节点(循环了len次)
if(NULL == pNew)//如果指针指向为空,则动态内存分配失败,pNew 的数据类型是PNODE类型,也就是指针类型,指针指向的就是地址,如果地址指向的 //的 地址为空,换句话说,相当于只有头指针,或者是只有尾指针,尾指针应该是不能的,因为一开始的链表是只有一个 //头指针的,所以说,如果pNew指向为空的话,说明,内存并没有进行分配,这个链表仍然是只有一个头节点的空链表。
{
printf("内存分配失败,程序终止运行!\n");
exit(-1);
}
pNew->data = val; //把有效数据存入pNEW
pTail->pNext = pNew; //把pNew 挂在pTail的后面(也就是pTail指针域指向,依次串起来)
pNew->pNext = NULL;//把pNew的指针域清空
pTail = pNew; //在把pNew赋值给pTai,这样就能循环,实现依次连接(而我们想的是只是把第一个节点挂在头节点上,后面的依次进行,即把第二个
//节点挂在第一个节点的指针域上),这个地方也是前面说的,要给pHead 一个“别名的原因”
/*
如果不是这样的话,代码是这样写的:
pNew->data = val;//一个临时的节点
pHead->pNext = pNew;//把pNew挂到pHead上
pNew->pNext=NULL; //这个临时的节点最末尾是空
注释掉的这行代码是有问题的,上面注释掉的代码的含义是分别把头节点后面的节点都挂在头节点上,
导致头节点后面的节点的指针域丢失(不存在指向),而我们想的是只是把第一个节点挂在头节点上,后面的依次进行,即把第二个
节点挂在第一个节点的指针域上,依次类推,很明显上面所注释掉的代码是实现不了这个功能的,pTail 在这里的做用就相当于一个中转站的作用,类似于两个数交换算法中的那个中间变量的作用,在一个链表中pHead 是头节点,这个在一个链表中是只有一个的,但是如果把这个节点所具备的属性赋值给另外的一个变量(pTail)这样的话,pTail 就相当于另外的一个头指针,然后当然也是可以循环。
*/
}
return pHead;//返回头节点的地址
}
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;//等价于 struct Node * pHead = NULL;把首节点的地址赋值给pHead(在一个链表中首节点和尾节点后面都是NULL,没有其他元素)
//PNODE 等价于struct Node *
pHead = create_list();
traverse_list(pHead);
return 0;
} 运行演示

算法小结
这只是一个简单的示例,其中用到的插入节点的算法就是尾插法,下面有具体的算法。
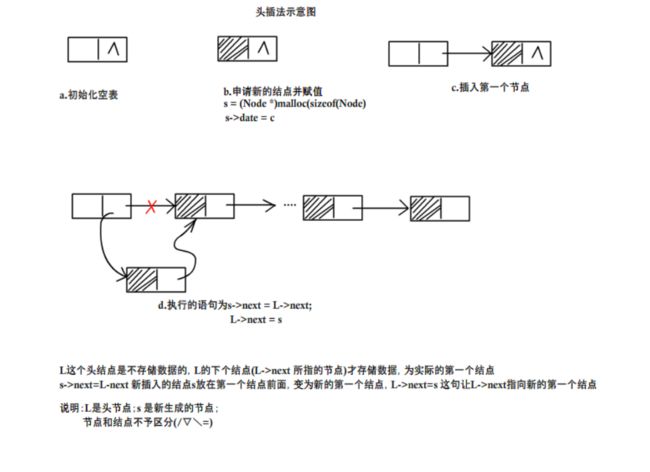
线性链表头插法实现
算法思想
从一个空表开始,每次读入数据,生成新结点,将读入数据存放到新结点的数据域中,然后将新结点插入到当前表的表头结点之后。
算法实现
# include
# include
typedef struct Node
{
int data;
struct Node * pNext;
}NODE,*PNODE;
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度\n");
int n;
int val;
scanf("%d",&n);
for (int i = n;i > 0;i--)
{
printf("请输入的第%d个数据",i);
PNODE p = (PNODE)malloc(sizeof(NODE));//建立新的结点p
if(NULL == p)
{
printf("内存分配失败,程序终止运行!\n");
exit(-1);
}
scanf("%d",&val);
p->data = val;
p->pNext = pHead->pNext;//将p结点插入到表头,这里把头节点的指针赋给了p结点
//此时,可以理解为已经把p节点和头节点连起来了,头指针指向,也就变成了
//p节点的指针指向了(此时的p节点相当于首节点了)
pHead->pNext = p;
}
return pHead;
}
int main(void)
{
PNODE pHead = NULL;
pHead = create_list();
traverse_list(pHead);
return 0;
} 运行演示
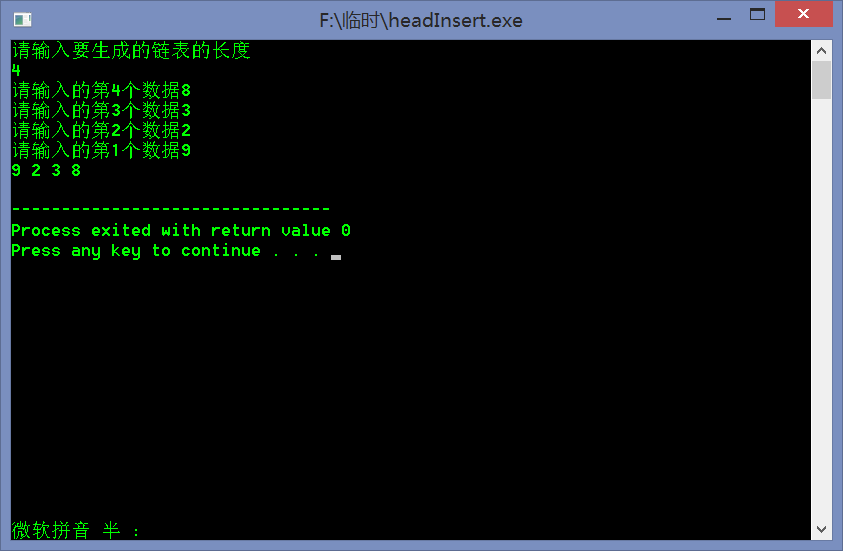
算法小结
采用头插法得到的单链表的逻辑顺序与输入元素顺序相反,所以也称头插法为逆序建表法。为什么是逆序的呢,因为在开始建表的时候,所谓头插法,就是新建一个结点,然后链接在头节点的后面,也就是说,最晚插入的结点,离头节点的距离也就是越近!这个算法的关键是 p->data = val;p->pNext = pHead->pNext; pHead->pNext = p;。用图来表示的话可能更加清晰一些。
线性链表尾插法实现
算法思想
头插法建立链表虽然算法简单,但生成的链表中节点的次序和输入顺序相反,如果希望二者的顺序一致,可以采用尾插法,为此需要增加一个尾指针r,使之指向单链表的表的表尾。
算法实现
# include
# include
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;//r 指针动态指向链表的当前表尾,以便于做尾插入,其初始值指向头节点,
//这里可以总结出一个很重要的知识点,如果都是指针类型的数据,“=”可以以理解为指向。
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val; //给新节点p的数据域赋值
r->pNext = p;//因为一开始尾指针r是指向头节点的, 这里又是尾指针指向s
// 所以,节点p已经链接在了头节点的后面了
p->pNext = NULL; //把新节点的指针域清空 ,先清空可以保证最后一个的节点的指针域为空
r = p; // r始终指向单链表的表尾,这样就实现了一个接一个的插入
}
return pHead;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
//删除
void DelList(PNODE pHead,int i,int * e)
//在带头节点的单链表L中删除第i个元素,并将删除的元素保存到变量 *e 中
{
NODE * pre;
NODE * r;
int k = 0;
pre = pHead;
while (pre->pNext!=NULL && kpNext;
k = k+1;
}
if(pre->pNext == NULL)
{
printf("删除位置i不合理!");
exit(-1);
}
r = pre->pNext;
pre->pNext = r->pNext;//修改指针,删除结点
*e = r->data;
printf("您要删除的结点%d已经被删除!",*e);
free(r);//注意顺序,是最后才把rfree掉!
}
int main(void)
{
int val;
PNODE pHead = NULL;
pHead = create_list();
traverse_list(pHead);
DelList(pHead,2,&val);
traverse_list(pHead);
return 0;
}
运行演示
算法小结
通过尾插法的学习,进一步加深了对链表的理解,“=”可以理解为赋值号,也可以理解为“指向”,两者灵活运用,可以更好的理解链表中的相关内容。
还有,这个尾差法其实就是这篇文章中的一开始那个小例子中使用的方法。两者可以比较学习。
查找第i个节点(找到后返回此个节点的指针)
按序号查找
算法思想
在单链表中,由于每个结点 的存储位置都放在其前一个节点的next域中,所以即使知道被访问的节点的序号,也不能想顺序表中那样直接按照序号访问一维数组中的相应元素,实现随机存取,而只能从链表的头指针触发,顺链域next,逐个结点往下搜索,直到搜索到第i个结点为止。
要查找带头节点的单链表中第i个节点,则需要从**单链表的头指针L出发,从头节点(pHead->next)开始顺着链表扫描,用指针p指向当前扫面到的节点,初始值指向头节点,用j做计数器,累计当前扫描过的节点数(初始值为0).当i==j时,指针p所指向的节点就是要找的节点。
代码实现
# include
# include
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找第i个节点
NODE * getID(PNODE pHead,int i)//找到后返还该节点的地址,只需要需要头节点和要找的节点的序号
{
int j; //计数,扫描的次数
NODE * p;
if(i<=0)
return 0;
p = pHead;
j = 0;
while ((p->pNext!=NULL)&&(jpNext;
j++;
}
if(i==j)//找到了第i个节点
return p;
else
return 0;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;
int n;
NODE * flag;
pHead = create_list();
traverse_list(pHead);
printf("请输入你要查找的结点的序列:");
scanf("%d",&n);
flag = getID(pHead,n);
if(flag != 0)
printf("找到了!");
else
printf("没找到!") ;
return 0;
}
运行演示
按值查找
算法思想
按值查找是指在单链表中查找是否有值等于val的结点,在查找的过程中从单链表的的头指针指向的头节点开始出发,顺着链逐个将结点的值和给定的val做比较,返回结果。
代码实现
# include
# include
#include //为了总是出现null未定义的错误提示
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找按照数值
NODE * getKey(PNODE pHead,int key)
{
NODE * p;
p = pHead->pNext;
while(p!=NULL)
{
if(p->data != key)
{
p = p->pNext;//这个地方要处理一下,要不然找不到的话就指向了系统的的别的地方了emmm
if(p->pNext == NULL)
{
printf("对不起,没要找到你要查询的节点的数据!");
return p;//这样的话,如果找不到的话就可以退出循环了,而不是一直去指。。。。造成指向了系统内存emmm
}
}
else
break;
}
printf("您找的%d找到了!",p->data) ;
return p;
}
//遍历
void traverse_list(PNODE pHead)//怎样遍历,是不能像以前一样用数组的,以为数组是连续的,这里不连续
{
PNODE p = pHead->pNext;
while (NULL != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
}
int main(void)
{
PNODE pHead = NULL;
int val;
pHead = create_list();
traverse_list(pHead);
printf("请输入你要查找的结点的值:");
scanf("%d",&val);
getKey(pHead,val);
return 0;
}
运行演示
算法小结
两个算法都是差不多的,第一个按序号查找,定义了一个计数变量j,它有两个作用,第一个作用是记录节点的序号,第二个作用是限制指针指向的范围,防止出现指针指向别的地方。第二个按值查找,当然也可以用相同的方法来限制范围,防止指针指向别的位置。或者和上面写的那样,加一个判断,如果到了表尾,为空了,就退出循环。
求链表的长度
算法思想
采用“数”结点的东方法求出带头结点单链表的长度。即从“头”开始“数”(p=L->next),用指针p依次指向各个节点。并设计计数器j,一直疏导最后一个节点(p->next == NUll),从而得到单链表的长度。
算法实现
# include
# include
#include //为了总是出现null未定义的错误提示
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的节点(输入0结束):\n");
int val=1;//赋一个初始值,防止 因为垃圾值而报错,下面都会被scanf函数给覆盖掉
PNODE r = pHead;
while(val != 0)
{
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//计算链表的长度
int ListLength(PNODE pHead)
{
NODE * p;
int j;//计数
p = pHead->pNext;
j = 0;
while(p!=NULL)
{
p = p->pNext;
j++;
}
return j;
}
int main(void)
{
PNODE pHead = NULL;
pHead = create_list();
int len = ListLength(pHead);
printf("%d",len);
return 0;
}
运行演示
算法小结
在顺序表中,线性表的长度是它的属性,数组定义时就已经确定,在单链表中,整个链表由“头指针”来表示,单链表的长度在头到尾遍历的过程中统计计数,得到长度值未显示保存。
求单链表中的最大值以及实现就地址逆置链表
算法思想(求单链表的最大值)
通过两个指针就可以很简单实现这个问题,值得注意的是,要主要模拟比较的过程,通过指针指向的两个节点的数据域进行比较,把数据域大的节点的地址返回,如果找不到一直找。
算法实现
# include
# include
typedef struct Node
{
int data;
struct Node * pNext;
} NODE,*PNODE;
PNODE create_list(void)
{
PNODE pHead = (PNODE)malloc(sizeof(NODE));
pHead->pNext = NULL;
printf("请输入要生成的链表的长度:\n");
int n;
int val;
PNODE r = pHead;
scanf("%d",&n);
for(int i = 0;i < n;i++)
{
printf("请输入的第%d个数据",i+1);
PNODE p = (PNODE)malloc(sizeof(NODE));
if(NULL == p)
{
printf("内存分配失败,程序终止运行!");
exit(-1);
}
scanf("%d",&val);
p->data = val;
r->pNext = p;
p->pNext = NULL;
r = p;
}
return pHead;
}
//查找单链表中的最大值
NODE * SearchMAx(PNODE pHead)
{
NODE * p1;//定义两个指针,依次比较两次的数据域大小
NODE * p2;
p1 = pHead->pNext;
p2 = p1->pNext;
while(p2 != NULL)
{
if(p2->data > p1->data) //注意这里和上面的赋值的顺序
{
p1 = p2;//把p1定义为最大结点的指针
p2 = p2->pNext;//继续走链表
}
else
{
p2 = p2->pNext; //如果一直没有找到比p1大的数据,继续找
}
}
return p1;//把最大的节点的地址返回
}
int main(void)
{
PNODE pHead = NULL;
NODE * p;
pHead = create_list();
p = SearchMAx(pHead);
printf("链表中的最大值为%d",p->data);
return 0;
} 运行演示
算法思想(就地址逆置换)
算法思想:逆置链表初始为空,表中节点从原链表中依次“删除”,再逐个插入逆置链表的表头(即“头插”到逆置链表中),使它成为逆置链表的“新”的第一个结点,如此循环,直至原链表为空。利用头插法。
算法实现
void converse(LinkList *head)
{
LinkList *p,*q;
p=head->next;
head->next=NULL;
while(p)
{
/*向后挪动一个位置*/
q=p;
p=p->next;
/*头插*/
q->next=head->next;
head->next=q;
}
}
参考文献
- 数据结构-用C语言描述(第二版)[耿国华]
- 数据结构(C语言版)[严蔚敏,吴伟民]