第一条:了解Objective-C语言的起源
Objective-C语言是一门面向对象的语言,与C++、Java等有所相似。然而在语法上,则有许多差别。这个差别产生的原因在于,Objective-C是由Smalltalk演化而来,直接借用了或者说继承了很多后者的思想,使用“消息结构”(messaging stricture)而非“函数调用”(function calling)。这个特性使得Objective-C语言,在运行时才回去查找所要执行的方法。实际上,编译器甚至都不关心接受消息的对象是何种类型。
Smalltalk之父Alan Kay曾经说过
I’m sorry that I long ago coined the term “objects” for this topic because it gets many people to focus on the lesser idea. The big idea is “messaging” – that is what the kernel of Smalltalk/Squeak is all about.
对象和类只是消息的载体。面向对象思想将程序按功能和逻辑分成了若干个类,每个类包含自己的代码、功能实现并提供对外接口,以黑箱模式运行,使得外部无需了解内部而协同使用,分解了复杂度并控制在一个个较小规模中,以消息作为其间所有的协作方式。消息才是Objective-C的核心。
Objective-C语言是C的“超集”(superset),亦或者说“Objective-C == C + runtime”。
所有C语言中的功能在编写Objective-C代码的时候依然适用。所以,掌握C语言有助于写出高效的Objective-C代码。而同时由于许多跨平台的第三方库是用C++编写的,我们最好也要了解一些C++。
第二条:在类的头文件中尽量少引入其他头文件
在Objective-C中,以类名做文件名,分别创建两个文件,头文件后缀使用.h,实现文件后缀使用.m。
我们在想要使用其他文件的时候,往往并不需要知晓其他文件的全部细节,只需要知道有一个类名就可以。我们使用@class方法去实现
使用@class时,若需要引入多个,标准写法为@class classA,ClassB,ClassC
这种方法叫做“前向声明”。
在实现文件中,需要实现的时候,就可以使用#import ClassA写法。
这样使用的原因在于:减少了很多根本用不到的内容,减少编译时间,提升性能;同时也可以避免两个类互相引用的问题,避免“循环引用”。
假如在某些情况下,必须要在.h文件中使用#import时,比如要声明某个类遵循一项协议,这种情况下,尽量吧“该类遵循某个协议”这条声明移到“class-continuation分类”中。若是还不行,就把协议单独放到一个头文件中,然后将其引入。
第三条:多用字面量语法,少用与之等价的方法
字面数值
将整数、浮点数、布尔值放入Objective-C对象中,我们一般需要NSNumber,有两种创建方法
NSNumber *someNumber = [NSNumber numberWithInt:1];
NSNumber *someNumber = @1;
字面量数组
NSArray *animals = [NSArray arraywithObjects:@"cat",@"dog",@"mouse",@"badger",nil];
NSArray *animals = @[@"cat",@"dog",@"mouse",@"badger",nil];
不过,我们使用这种方法的时候,数组元素不能为nil,因为创建数组的时候,到nil为止。使用第一种方法创建的数组,可能会缺少元素,而使用第二种即字面量方法创建的数组,会直接抛出异常。这也表明了使用字面量会更加安全,抛出异常令程序终止执行,比创建好一个数组后发现少了要好。我们可以通过异常直接发现这个错误。
字面量字典
NSDictionary *personData = [NSDictionary dictionaryWithObjectsAndKey:@"Matt",@"firstName",@"galloway",@"lastName",[NSNumber numberWithInt:28],@"age",nil];
NSDictionary *personData =
@{@"firstName":@"Matt",
@"lastName":@"Galloway"
@"age":@28};
这里的优势显而易见,键出现在对象之前,更加好理解。
局限性
除了字符串意外,所有创建出来的对象,必须属于Foundation框架才行。并且,创建出来的字符串、数组、字典对象都是不可变的。假如想使用可变版本的,需要mutableCopy一份。
第四条:多用类型常量,少用#define预处理指令
有时候,我们需要使用某个常量的时候,会这么使用
#define ANIMATION_DURATION 0.3
但是使用这个方法有时候会遇到一个问题:它会将所有遇到的ANIMATION_DURATION都替换成0.3.
为了避免这种情况
static const NSTimeInterval kANimationDuration = 0.3;
此外,我们还要注意常量的名称,常用的做法是,若常量局限于某“实现文件”内,则在前面加k;若是常量在类之外课件,则通常以类名为前缀。
常量一定要同时使用static与const来声明。
假如要使得外界可见,一般我们会将其放入一个“全局符号表”中。
.h
extern NSString *const EOCStringConstant;
.m
NSString *const EOCStringConstant = @"VALUE";
extern关键字会告诉编译器,在全局符号表中将会有一个名叫EOCStringConstant的符号,也就是说,编译器无需查看其定义,即允许代码使用此常量。因为它知道,当链接成二进制文件之后,肯定能找到这个常量。
此类常量必须要定义,且只能定义一次。通常将其定义的与声明该常量的头文件相关的实现文件中。由实现文件生成目标文件时,编译器会在“数据段”为字符串分类存储空间。链接器会把此目标文件与其他目标文件相链接,以生成最终的二进制文件,凡是用到EOCStringConstant这个全局符号的地方,链接器都能将其解析。
这样要优于使用#define预处理指令,因为编译器会确保常量值不变。一旦在一处文件中定义好,即可随处使用;而采用预处理指令所定义的常量可能会无意中遭人修改,从而导致应用程序各个部分所使用的值互不相同。
第5条:用枚举表示状态、选项、状态码
应用枚举来表示状态机的状态、传递给方法的选项及状态码等值,给这些值起个易懂的名字。
如果把传递给某个方法的选项表示为枚举类型,而多个选项又可同时使用,那么就将各选项的值定义为2的幂,以便通过按位或操作将其组合起来。
在处理枚类型的switch语句中不要出现default分支。这样的话,加入新枚举之后,编译器就会提示开发者:switch语句并未处理所有枚举。
我们知道,在Objective-C中,“对象”(object)就是最基本的构造单元,开发者通过对象来存储和传递数据。在对象之间传递数据并执行任务的过程就叫做“消息传递”(Messaging)。
第6条:理解“属性”这一概念
“属性”(property)是Objective-C的一个特征,用于封装对象中的数据。Objective-C对象通常会把其所需要的数据保存为各种实例变量。实例变量一般通过“存取方法”来访问。其中,“获取方法”(getter)用于读取变量值,而“设置方法”(setter)用于写入变量值。
Objective-C会把实例变量当做一种存储偏移量的特殊变量,交给“类对象”保管。偏移量会在运行期查找,如果类的定义变了,那么存储的偏移量也就变了。这样的话,无论何时访问实例变量,总能找到正确的偏移量。甚至可以在运行期向类中新增实例变量。
当然,我们还可以使用属性的方法去解决这个问题,也就是不不要直接访问实例变量,而通过存取方法来做。
@interface EOCPerson : NSObject
@property NSString *firstName;
@property NSString *lastName;
@end
与下面等价
@interface EOCPerson : NSObject
- (NSString *)firstName;
- (void)setFirstName:(NSString *)firstName;
- (NSString *)lastName;
- (void)setLastName:(NSString *)lastName;
@end
使用“点语法”的效果与直接调用存取方法相同。
EOCPerson *aPerson = [Person new];
aPerson.firstName = @"Bob";//Same as
[aPerson setFirstName:@"Bob"];
NSString *lastName = aPerson.lastName;//same as
NSString *lastName = [aPerson lastName];
属性特质
属性可以分为四类:
原子性
使用同步锁,为nonatomic(默认),不适用则为atomic
iOS程序中,绝大部分都是nonatomic,atomic会带来非常大的性能问题。而且往往也达不到“线程安全”,如果要实现,还需要更加深层的锁定机制。
读写权限
具备readwrite特质的属性拥有setter和getter方法。编译器会自动生成
具备readonly特质的属性仅拥有获取方法。你可以利用此特质,把某个属性对外公开为只读属性,然后在“class-continuation分类”中将其重新定义为读写属性。
内存管理语义
assign(默认):assign用于值类型,如int、float、double和NSInteger,CGFloat等表示单纯的复制。还包括不存在所有权关系的对象,比如常见的delegate。
strong:strong是在IOS引入ARC的时候引入的关键字,是retain的一个可选的替代。表示实例变量对传入的对象要有所有权关系,即强引用。strong跟retain的意思相同并产生相同的代码,但是语意上更好更能体现对象的关系。
weak:在setter方法中,需要对传入的对象不进行引用计数加1的操作。
unsafe_unretailed 此特质的语义和assign相同,但适用于“对象类型”,该特质表达一种“非拥有关系”,当对象遭到摧毁时,属性值不会自动清空,这一点与weak有区别。
copy:与strong类似,但区别在于实例变量是对传入对象的副本拥有所有权,而非对象本身。
方法名
getter=
setter=
第7条:在对象内部尽量直接访问实例变量
由于不经过Objective-C的“方法派发”步骤,所以直接访问实例变量的速度回比较快。编译器所生成的代码会直接访问对象实例变量的那块内存;直接访问实例变量时,不会调用其“设置方法”,这就绕过了为相关属性所定义的“内存管理语义”;直接访问实例变量,不会触发“键值观测(KVO)”通知;通过属性来访问会有助于排查与之相关的错误,因为可以在“获取方法”和“设置方法”中新增断点,监控该属性的调用者及其访问时机。
在对象内部读取数据时,应该直接通过实例变量来读,而写入数据时,则应使用属性来写。
在初始化方法和dealloc方法中,总是应该使用实例变量(self.xxx)来读写数据。
有时会使用懒加载技术配置某份数据,这种情况下,需要使用属性来读取数据。
第8条:理解“对象等同性”这一概念
按照==操作符比较出来的结果未必是我们想要的,因为该操作比较的是两个指针本身,而不是其所指的对象。应该使用NSObject协议中声明的“isEqual”方法,来判断两个对象的等同性。
在NSString中有相应的比较方法,叫“isEqualToString:”。该方法比“isEqual”要快,后者还要执行额外的步骤,以判断对象的类型。
NSObject协议中有两个用于判断等同性的关键方法:
- (BOOL)isEqual:(id)object;
- (NSUInteger)hash;
NSObject类对这两个方法的默认实现是:当且仅当其“内存地址”完全相等时,两个对象才相等。如果“isEqual”方法判定两个对象相等,那么其hash方法必须返回同一个值,但是,如果两个对象的hash方法返回同一个值,那么“isEqual”方法未必会认为两者相等。
在编写hash判断方法时,要格外的注意性能问题。因为collection在检索hash table的时候,会用对象的哈希码做索引。江入某个collection使用set实现的,那么set可能会根据哈希码把对象分装到不同的数组中。在向set中添加新对象时,要根据其哈希码找到与之相关的那个数组,依次检查检查其中各个元素,看数组中以后的对象时候和将要添加的新对象相等。如果相等,那就说明要添加的对象已经在set里面了。由此可知,如果令每个对象都返回相同的哈希码,那么在set中已有100000个对象的情况下,若是继续向其中添加对象,则需将这1000000个对象全部扫描一遍。
若是计算哈希码,可以使用如下方法
- (NSUIntger)hash {
NSUIntger firstNameHash = [_firstName hash];
NSUIntger lastNameHash = [_lastName hash];
NSUIntger ageHash = _age;
return firstNameHash ^ lastNameHash ^ ageHash;
}
这种方法既能保持较高效率,又能使生成的哈希码至少位于一定范围内,而不会过于频繁的重复。
当然,我们也可以自己实现等同性判断方法,在写这样的方法时,也应一并覆写“isEqual”方法。
- (BOOL)isEqualToPerson:(EOCPerson *)otherPerson {
if(self == object ) return YES;
if(![_first那么isEqualToString:otherPerson.firstName]){
return NO;
}
return YES;
}
- (BOOL)isEqual:(id)object {
if([self class] == [object class]) {
return [self isEqualToPerson:(EOCPerson *)object];
}else{
return [super isEqual:object];
}
}
不要盲目的逐个监测每条属性,而是应该依照具体需求来制定检测方案。比如判断数组,我们就可以先判断数组的所含对象的数量是否相等。
如果把对象放入collection之后改变其内容,可能会造成严重的后果,要小心对待
第9条:以“类族模式”隐藏实现细节
“类族”是一种很有用的模式,可以隐藏“抽象基类”背后的实现细节。“工厂模式”是创建类族的办法之一。
如果对象所属的类位于某个类族中,那么在查询其类型信息时就要当心了。你可能觉得创建了某个类的实现,然而实际上穿件的却是其子类的实例。
在系统框架中,很多地方都使用了类族模式。比如NSArray。
我们在给Cocoa中的类族添加子类的时候,要注意一下几点:
- 子类应该继承自类族中的抽象基类
- 子类应该定义自己的数据存储方式
- 子类应该复写超类文档中指明需要覆写的方法。
第10条:在既有类中,使用关联对象(Associated Object)存放自定义数据
有时需要在对象中存放相关信息,这是我们通常对从对象所属的类中继承一个子类,然后改用这个子类对象。然而有时候我们无法这么做,这时候就要使用关联对象了。
| 关联类型 | 等效的@property属性 |
|---|---|
| OBJC_ASSOCIATION_ASSIGN | assign |
| OBJC_ASSOCIATION_RETAIN_NONATOMIC | nonatomic,retain |
| OBJC_ASSOCIATION_COPY_NONATOMIC | nonatomic,copy |
| OBJC_ASSOCIATION_RETAIN | retain |
| OBJC_ASSOCIATION_COPY | copy |
下列方法可以管理关联对象:
- void objc_setAssociatedObject(id object,void *key,id value,objc_AssociationPolicy policy)
此方法以给定的键和策略为某对象设置关联对象值- id objc_getAssociatedObject(id object,void *key)
此方法根据给定的键和策略为某对象中获取相应的关联对象值- void objc_removeAssicuatedObjects(id object)
此方法移除指定对象的全部关联对象
在设置关联对象值时,通常使用静态全局变量做键
只有在其他方法完全不可行的时候才选用关联对象方法,因为这种做法通常会引入难于查找的bug。
第11条:理解objc_msgSend的作用
在C语言当中,C语言使用“静态绑定”,也就是说,在编译期就能决定运行时所应调用的函数。
而Objective-C使用“动态绑定”,在底层,所有方法都是普通的C语言函数,然而对象收到消息后,究竟该调用那个方法则完全于运行期决定,甚至可以在程序运行时改变。
给对象发送消息可以这样来写:
id returnValue = [someObject messageName:parameter];
在这里,someObject叫做“接收者”,messageName叫做“选择子”,选择子与参数合起来称之为“消息”。编译器看到此消息后,将其转换为一条标准的C语言函数调用,所调用的函数乃是消息传递机制中的核心函数,叫做objc_msgSend,其原型如下:
void objc_msgSend(id self,SEL cmd,...)
编译器会把它转换成
id returnValue = objc_msgSend(someObject,
@selector(messageName:),
parameter);
为了完成此操作,该方法需要在接受者所属的类中搜寻其“方法列表”如果能找到与选择子名称相符的防范,就跳转至其代码。若是找不到,那就沿着继承体系继续向上查找,等找到合适的方法之后再跳转。如果最终还是找不到相符的方法,那就执行“消息转发”操作。
objc_msgSend会将匹配结果缓存在“快速映射表”里面,每个类都有这一块缓存,若是稍后还想该类发送与选择子相同的消息,那么执行起来就会很快了。
除了以上的方法,还有一些其他的函数:
- objc_msgSend_stret 如果待发送的消息要返回结构体,就由它处理。
- objc_msgSend_fpret 如果待发送的消息要返回浮点数,就由它处理。
- objc_msgSendSuper 如果要给超类发消息,例如[super message:parameter],那么久交由此处理。
在每个类中都有一张表格,其中的指针都会指向这种函数,而选择子的名称则是查表所用的“键”。
这里为了优化,使用了尾调用优化。
如果某函数的最后一项操作是调用另外一个函数,那么就会调用这个方法。编译器会生成调转至另一函数所需的指令码,而且不会向调用堆栈中推入新的“栈帧”。这么做法非常关键,如果不这么做的话,会过早的发生栈溢出。
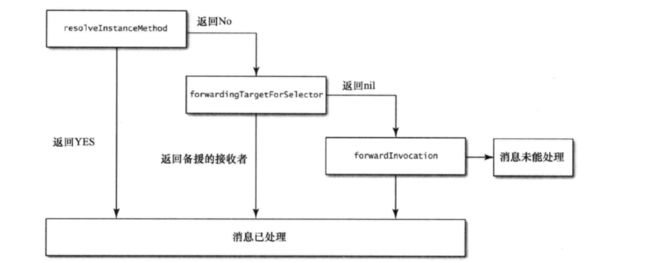
第12条:理解消息转发机制
在编译期间向类发送了其无法解读的消息并不会报错,因为在运行期可以继续向类中添加方法,所以编译器会在编译时还无法确定类中到底会不会有某个方法实现。当对象收到了无法解读的消息时,就会启动“消息转发”机制。
消息转发分为两大阶段。第一阶段先征询接受者,所属的类,看其是否能动态添加方法,以处理这个未知的选择子,这叫做动态方法解析。第二阶段涉及“完整的消息转发机制”。如果运行期系统已经把第一阶段执行完了,那么接受者自己就无法再以动态新增方法的手段来响应包含该选择子的消息了。此时,运行期系统会请求接受者以其他手段来处理与消息相关的方法调用。这里又分两步,首先,请接受者看看有没有其他对象能处理这条消息。若有,则运行期系统会把消息转给那个对象。若没有备用的接受者,则启动完整的消息转发机制,运行期系统会把与消息相关的全部细节都封装到NSInvocation当中,再给接受者最后一次机会,令其设法解决当前还未处理的这条消息。
第13条:用method swizzling调试黑盒方法
我们在给定的选择子名称相对的方法在运行期改变,这种方法叫“方法调配”(method swizzling)。
类的方法列表会把选择子的名称映射到相关的方法实现上,是的“动态消息派发系统”能够据此找到应该调用的方法。这些方法以函数指针的方法表示,这种指针叫做IMP,原型如下:
id (*IMP)(id,SEL,...)
我们要实现方法互换,需要以下方法
//交换方法实现
void method_exchangeImplementations(Method m1,Method m2)
//取出对应方法
Method class_getInstanceMethod(Class aClass,SEL aSelector)
看起来没有什么用处,但是结合添加方法和category,就可以达到让人意想不到的效果。
在category中添加一个方法,与原本的方法互换,就会达到调用的效果。
这里实现埋点,日志意义非常大。
一般来说,只有调试程序的时候才需要在runtime中修改方法实现,这种做法不宜滥用。
第14条:理解"类对象"的用意
描述Objective-C对象所用的数据结构定义在运行期程序库的头文件里,id类型本身也在定义这里:
typedef struct objc_object {
Class isa
}*id;
由此可见,每个对象结构体的首个成员是Class的变量。该变量定义了对象所属的类,通常称为"isa"指针。
Class对象也定义在运行期程序库的头文件中:
typedef struct objc_class *Class
struct objc_class {
Class isa OBJC_ISA_AVAILABILITY;
Class super_class;
const char *name;
long version;
long info;
long instance_size;
struct objc_ivar_list *ivars;
struct objc_method_list **methodLists;
struct objc_cache *cache;
struct objc_protocol_list *protocols;
} ;
在类继承中查询类的信息:
isMemberOfClass能够判断出对象是否为某个特定类的实例,而isKindOfClass则能判断出对象是否为某类或其派生类的实例。
每个实例都有一个指向Class对象的指针,用以表明其类型,而这些Class对象则构成了累的继承体系。
如果对象类型无法在编译期确定,那么就应该使用类型信息查询方法来探知。
尽量使用类型信息查询方法来确定对象类型,而不要直接比较类对象,因为某些对象可能实现了消息转发功能。
第15条:用前缀避免命名空间冲突
Apple宣称其保留使用所有"两字母前缀"的权利,所以我们选用的前缀应该是三个字母的。 而且,如果自己开发的程序使用到了第三方库,也应该加上前缀。
第16条:提供“全能初始化方法”
有时,由于要实现各种设计需求,一个类可以有多个创建实例的初始化方法。我们应该选定其中一个作为全能初始化方法,令其他初始化方法都来调用它。这个我们就叫做“全能初始化方法”。
只有在全能初始化方法里面才能存储内部数据。这样一来,当底层数据存储机制改变时,只需修改此方法的代码就好,无需改动其他初始化方法。
在我们拥有了一个全能初始化方法后,最好还是要覆写init方法来设置默认值。并且,每个子类的全能初始化方法都应该调用其超类的对象方法,并且逐级向上,否则可能无法实现相应的方法。
假如我们并不想覆写超类的全能初始化方法,我们可以在本类中在覆写超类的全能初始化方法并抛出异常。
第17条:实现description方法
在打印我们自己定义的类的实例对象时,在控制台输出的结果往往是只包含了类名和内存地址,它的信息显然是不具体的,远达不到调试的要求。
这时,我们就需要重写description方法了。我们将这些属性值放在字典里打印,则更具有可读性:
- (NSString*)description {
return [NSString stringWithFormat:@"<%@: %p, %@>",[self class],self,
@{ @"title":_title,
@"latitude":@(_latitude),
@"longitude":@(_longitude)}
];
}
输出结果:
location =
如果你想要在调试器中实现类似效果,就需要重写debugDescription方法了。可以实现和description一样的效果,并且当你不想要在log中出现过分详细的内容的时候,完全可以使用debugDescription在调试器中使用。
第18条:尽量使用不可变对象
书中作者建议尽量把对外公布出来的属性设置为只读,在实现文件内部设为读写。具体做法是:
在头文件中,设置对象属性为readonly,在实现文件中设置为readwrite。这样一来,在外部就只能读取该数据,而不能修改它,使得这个类的实例所持有的数据更加安全。
而且,对于集合类的对象,更应该仔细考虑是否可以将其设为可变的。
如果在公开部分只能设置其为只读属性,那么就在非公开部分存储一个可变型。这样一来,当在外部获取这个属性时,获取的只是内部可变型的一个不可变版本,例如:
在公共API中:
@interface EOCPerson : NSObject
@property (nonatomic, copy, readonly) NSString *firstName;
@property (nonatomic, copy, readonly) NSString *lastName;
@property (nonatomic, strong, readonly) NSSet *friends //向外公开的不可变集合
- (id)initWithFirstName:(NSString*)firstName lastName:(NSString*)lastName;
- (void)addFriend:(EOCPerson*)person;
- (void)removeFriend:(EOCPerson*)person;
@end
在这里,我们将friends属性设置为不可变的set。然后,提供了来增加和删除这个set里的元素的公共接口。
在实现文件里:
@interface EOCPerson ()
@property (nonatomic, copy, readwrite) NSString *firstName;
@property (nonatomic, copy, readwrite) NSString *lastName;
@end
@implementation EOCPerson {
NSMutableSet *_internalFriends; //实现文件里的可变集合
}
- (NSSet*)friends {
return [_internalFriends copy]; //get方法返回的永远是可变set的不可变型
}
- (void)addFriend:(EOCPerson*)person {
[_internalFriends addObject:person]; //在外部增加集合元素的操作
//do something when add element
}
- (void)removeFriend:(EOCPerson*)person {
[_internalFriends removeObject:person]; //在外部移除元素的操作
//do something when remove element
}
- (id)initWithFirstName:(NSString*)firstName lastName:(NSString*)lastName {
if ((self = [super init])) {
_firstName = firstName;
_lastName = lastName;
_internalFriends = [NSMutableSet new];
}
return self;
}
我们也要将内部可变的set去开放给外边一个不可变的set。但是这里会造成一个问题,也就是我们在内部修改set的时候,外部可能有观察者正在使用这个set。这时候,我们需要运用“派发队列”等手段,把数据的存取操作都设置为同步操作。
第19条:使用清晰而协调的命名方式
类、方法及变量的命名是Objective-C编程的重要环节。它的语法结构使得代码读起来和句子一样,名字中一般都带有"in"、"for"、"with"等介词。
方法名与变量名要使用“驼峰命名法”(camel casing),以小写字母开头,其后每个单词首字母大写。类名也用驼峰命名法,不过首字母要大写,并且前面通常还有三个前缀字母。
作者给我们总结了几条注意事项:
- 如果方法的返回值是新出创建的,那么方法名的首个词应该是返回值的类型,除非前面还有修饰词。
- 应该把表示参数类型的名词放在参数前面。
- 如果方法要在当前对象上执行操作,那么就应该包含动词;若执行操作还需要参数,则应该在动词后面加上一个或多个动词。
- 不要使用str这种简称,应该使用string这样的全称。
- Boolean 属性应该加is前缀。如果返回的非属性的Boolean值,那么应该根据其功能,选用has或者is当前缀
- 将get这个前缀留给那些借由“输出参数”来保存返回值的方法。
第20条:为私有方法名加前缀
建议在实现文件里将非公开的方法都加上前缀,便于调试,而且这样一来也很容易区分哪些是公共方法,哪些是私有方法。因为往往公共方法是不便于任意修改的。
作者推荐使用字母和_相结合的方式。比如说在私有方法前加 p
- 不要用下划线来区分私有方法和公共方法,因为会和苹果公司的API重复。
第21条:理解Objective-C错误类型
首先要注意的是,ARC在默认情况下不是“异常安全的”。也就是说如果抛出异常,那么本应该在作用域末尾释放的对象现在却不会自动释放了。
现在Objective-C使用的策略是:只有在极其罕见的情况下才会抛出异常,异常跑出来之后,无须考虑恢复问题,而应用也会推出。换一句话说:程序崩啦!
那么问题来了,程序只有在遇到严重错误的时候会崩溃,在遇到不那么严重的错误是,该如何处理呢?
会令方法返回nil/0,或者是使用NSError,来标明错误的发生。
返回nil/0很简单,就是返回值会是nil或者0,这样我们就明白发生了错误。
而NSError则更加灵活,我们可以通过NSError将导致错误的原因返回给使用者。
使用NSError可以封装三种信息:
Error domain:错误范围,类型是字符串
Error code :错误码,类型是整数
User info:用户信息,类型是字典
NSError的用法:
1.通过委托协议来传递NSError,告诉代理错误类型。
- (void)connection:(NSURLConnection *)connection didFailWithError:(NSError *)error
2.作为方法的“输出参数”返回给调用者
- (BOOL)doSomething:(NSError**)error
使用范例:
NSError *error = nil;
BOOL ret = [object doSomething:&error];
if (error) {
// There was an error
}
第22条:理解NSCopying协议
使用对象时我们经常拷贝它。如果我们想令自己的类支持拷贝操作,那就要实现NSCopying协议,该协议只有一个方法:
- (id)copyWithZone:(NSZone*)zone
NSZone这个参数是以前的历史遗留,现在每个程序都只有一个区:默认区,所以,我们可以不必管这个参数了。
若想使某个类支持拷贝功能,只需声明该类遵从NSCopying协议,并实现其中的copyWithZone方法就可以。
如果我们想获得某对象的不可变型,统一调用copy方法;获得某对象的可变型,统一调用mutableCopy方法。
例如数组的拷贝:
-[NSMutableArray copy] => NSArray
-[NSArray mutableCopy] => NSMutableArray
深浅拷贝
Foundation框架中的集合类默认都执行浅拷贝:只拷贝容器对象本身,而不复制其中的数据。 而深拷贝的意思是连同对象本身和它的底层数据都要拷贝。
[图片上传失败...(image-f73c33-1527125798111)]
- (id)initWithSet:(NSArray*)array copyItems:(BOOL)copyItems;
在这里,我们自己提供了一个深拷贝的方法:该方法需要传入两个参数:需要拷贝的数组和是否拷贝元素(是否深拷贝)
- (id)deepCopy {
EOCPerson *copy = [[[self class] alloc] initWithFirstName:_firstName andLastName:_lastName];
copy->_friends = [[NSMutableSet alloc] initWithSet:_friends copyItems:YES];
return copy;
}
因为没有专门定义深拷贝的协议,所以其具体执行方式由每个类来决定,你时许决定自己所写的类是否要提供深拷贝方法即可。另外,不要嘉定遵从了NSCopying协议的对象都会执行深拷贝。在绝大多数情况下,执行的都是浅拷贝。
第23条:通过委托与数据源协议进行对象间通信
定义:定义一套接口,某对象若想接受另一个对象的委托,则需遵从此接口,一遍成为其"委托对象"。而这"另一个对象"则可以给其委托对象回传一些信息,也可以在发生相关事件时通知委托对象。
对于代理模式,在iOS中分为两种:
delegate:信息从类流向委托者,从委托对象中获取信息。
datasource:信息从数据源流向类,将信息传递给类。
- 注意:用属性定义委托对象的时候,需要设置为weak,而非strong。
使用@optional关键字标注方法,表示方法未必执行。
在使用的时候,最好再加上一个判断:判断委托对象是否存在
NSData *data = /* data obtained from network */;
if ( (_delegate) && ([_delegate respondsToSelector: @selector(networkFetcher:didReceiveData:)]))
{
[_delegate networkFetcher:self didReceiveData:data];
}
优化
我们需要在使用的时候检查委托对象是否响应选择子,但是如果频繁的执行操作,除了第一次操作是有用的以外,后续的操作都是多余的。所以,我们可以把委托对象能否响应某个协议方法这一信息缓存起来,以便优化程序效率。
这里我们可以使用"段位"(bitfield)数据类型来实现。把结构体中某个字段所占用的二进制位个数设为特定的值。
@interface EOCNetworkFetcher () {
struct {
unsigned int didReceiveData :1
unsigned int didFailWithError :1
unsigned int didUpdateProgressTo :1
}_delegate;
}
@end
这样我们就可为代理设置缓存。
//set flag
_delegate.didReceiveData = 1;
//Check flag
if(_delegateFlags.didReceiceData){
//yes,flag set
}
然后我们实现缓存的代码可以写在delegate的设置方法中
- (void)setDelegate:(id)delegate {
_delegate = deleagte;
_delegateFlags.didReceiveData = [delegate respondsToSelect:@selector(networkFetcher:didReceiveData:)];
}
这样的话我们每次调用delegate的方法前,就不用检测委托对象能否响应给指定的选择子了,二十直接查询结构体的标志:
if(_delegateFlags.didUpdateProgressTo){
[_delegate networkFetcher:self didUpdateProgressTo:currentProgress];
}
第24条:将类的实现代码分散到便于管理的数个分类中
通常一个类会有很多方法,而这些方法往往可以用某种特有的逻辑来分组。我们可以利用OC的分类机制,将类的这些方法按一定的逻辑划入几个分区中。
例子:
无分类的类:
#import
@interface EOCPerson : NSObject
@property (nonatomic, copy, readonly) NSString *firstName;
@property (nonatomic, copy, readonly) NSString *lastName;
@property (nonatomic, strong, readonly) NSArray *friends;
- (id)initWithFirstName:(NSString*)firstName lastName:(NSString*)lastName;
/* Friendship methods */
- (void)addFriend:(EOCPerson*)person;
- (void)removeFriend:(EOCPerson*)person;
- (BOOL)isFriendsWith:(EOCPerson*)person;
/* Work methods */
- (void)performDaysWork;
- (void)takeVacationFromWork;
/* Play methods */
- (void)goToTheCinema;
- (void)goToSportsGame;
@end
分类之后:
#import
@interface EOCPerson : NSObject
@property (nonatomic, copy, readonly) NSString *firstName;
@property (nonatomic, copy, readonly) NSString *lastName;
@property (nonatomic, strong, readonly) NSArray *friends;
- (id)initWithFirstName:(NSString*)firstName lastName:(NSString*)lastName;
@end
@interface EOCPerson (Friendship)
- (void)addFriend:(EOCPerson*)person;
- (void)removeFriend:(EOCPerson*)person;
- (BOOL)isFriendsWith:(EOCPerson*)person;
@end
@interface EOCPerson (Work)
- (void)performDaysWork;
- (void)takeVacationFromWork;
@end
@interface EOCPerson (Play)
- (void)goToTheCinema;
- (void)goToSportsGame;
@end
其中,FriendShip分类的实现代码可以这么写:
// EOCPerson+Friendship.h
#import "EOCPerson.h"
@interface EOCPerson (Friendship)
- (void)addFriend:(EOCPerson*)person;
- (void)removeFriend:(EOCPerson*)person;
- (BOOL)isFriendsWith:(EOCPerson*)person;
@end
// EOCPerson+Friendship.m
#import "EOCPerson+Friendship.h"
@implementation EOCPerson (Friendship)
- (void)addFriend:(EOCPerson*)person {
/* ... */
}
- (void)removeFriend:(EOCPerson*)person {
/* ... */
}
- (BOOL)isFriendsWith:(EOCPerson*)person {
/* ... */
}
@end
注意:在新建分类文件时,一定要引入被分类的类文件。
通过分类机制,可以把类代码分成很多个易于管理的功能区,同时也便于调试。因为分类的方法名称会包含分类的名称,可以马上看到该方法属于哪个分类中。
利用这一点,我们可以创建名为Private的分类,将所有私有方法都放在该类里。这样一来,我们就可以根据private一词的出现位置来判断调用的合理性,这也是一种编写“自我描述式代码(self-documenting)”的办法。
第25条:总是为第三方类的分类名称加前缀
分类机制通常用于向不知道源码的既有类中新增功能。但是使用的时候也容易忽视其中的问题,这个问题在于:分类中的方法是直接添加在类里面的。将分类中的方法假如类中这一操作是在运行期系统加载分类时完成的。运行期系统会把分类中所实现的每个方法都加入类的方法列表中。如果类中本来就有此方法,而分类又实现了一次,那么分类中的方法会覆盖原来那一份实现代码。
我们需要在分类中的方法前加上前缀,这么做的好处有以下几点:
- 可以避免自己活他人实现的方法名重复
- 避免和苹果自己的api重复,即使现在没有,也有可能在未来的某个时间,苹果新加了方法
- 避免他们使用自己代码是,发生误会
第26条:勿在分类中声明属性
除了实现文件里的class-continuation分类中可以声明属性外,其他分类无法向类中新增实例变量。
因此,类所封装的全部数据都应该定义在主接口中,这里是唯一能够定义实例变量的地方。
关于分类,需要强调一点:
分类机制,目标在于扩展类的功能,而不是封装数据。
第27条:使用class-continuation分类 隐藏实现细节
通常,我们需要减少在公共接口中向外暴露的部分(包括属性和方法),而因此带给我们的局限性可以利用class-continuation分类的特性来补偿:
可以在class-continuation分类中增加实例变量。
可以在class-continuation分类中将公共接口的只读属性设置为读写。
可以在class-continuation分类中遵循协议,使其不为人知。
第28条:通过协议提供匿名对象
我们用协议把自己所写的API之中的实现细节隐藏起来,将返回的对象设计为遵从此协议的纯id类型。这样,想要隐藏的类名就不会出现在API当中了。若是接口背后有多个不同的实现类,而你又不想之名具体使用哪个类,那么就可以使用这个方法。
如果具体的类型不重要,重要的是对象能够响应(定义在协议里面)的特定方法,那么可使用匿名对象来表示。
第29条:理解引用计数
NSObject协议声明了以下三个方法用于操作引用计数器。
retain 递增保留计数
release 递减保留计数
autorelease 自动释放池
对象创建出来之后,引用计数至少为1.我们绝不应该说保留计数一定是某个值,只能说你所执行的操作是递增了还是递减了该计数。
在设置属性的时候,需要使用实例变量的getter方法和setter方法。比如以下代码
- (void)setFoo:(id)foo {
[foo retain];
[_foo release];
_foo = foo;
}
这里我们先保留新值并释放了旧值,然后更新实例变量,令其指向新值。这个顺序非常重要,假如还未保留新值就把旧值释放了,然后两个值又指向同一个对象,俺么,先执行的release操作就可能导致系统将此对象永久回收。而后续的retain操作则无法令这个已经彻底回收的对象复生,于是实例变量就成了悬挂指针。
autorelease
将对象放入自动释放池之后,不会马上使其引用计数-1,而是在当前线程的下一次事件循环时递减。
使用举例:如果我们想释放当前需要使用的方法返回值是,可以将其暂时放在自动释放池中:
- (NSString*)stringValue {
NSString *str = [[NSString alloc] initWithFormat:@"I am this: %@", self];
return [str autorelease];
}
retain cycle
在其他有垃圾回收机制的语言中,几个对象互相引用形成保留环的时候,垃圾回收器会把几个对象认定为"孤岛",将其全部收走。而在Objective-C中,往往要采用weak reference即弱引用的方法解决问题。此外,我们还可以在外界命令循环中的某个对象不再保留另外一个对象。
第30条:以ARC简化引用计数
在Clang编译器中带有一个"静态分析器(sratic analyzer)",用于指明程序里引用计数出问题的地方,它可以很简单的通过引用计数的检查来分析出是否有内存泄漏。这个也是ARC的思路来源。
使用ARC的时候一定要记住,引用计数实际上还是要执行的,只不过保留与释放操作现在是由ARC为你自动添加。
在ARC环境下,会自动执行retain、release、autorelease、dealloc方法,所以我们不能再调用了。实际上,ARC在调用这些方法的时候,并不通过普通的Objective-C消息派发机制,二十直接调用其底层的C语言版本,这要操作性能会更好。
在ARC中,在方法返回自动释放的对象时,要执行一个特殊函数。此时不会调用对象的autorelease方法,而是改用objc_autoreleaseReturnValue方法。此函数会检视当前方法返回之后即将要执行的那段代码。若发现那段代码要在返回的对象上执行retain操作,则设置全局数据结构中的一个标志位,而不执行autorelease操作。与之相似,如果方法返回了一个自动释放的对象,而调用方法的代码要保留此对象,那么此时不直接执行retain,而是改为执行objc_retainAttoreleaseReturnValue函数。此函数要检测刚才提到的那个标志位,若已经置位,则不执行retain操作。设置并检测标志位,要比调用autorelease和retain更快。
在ARC中,会采用一种安全的方式来设置:先保留新值,再释放旧值,最后设置实例变量。
ARC如何管理实例变量
在MRC下,我们要这么写dealloc方法:
-(void)dealloc {
[_foo release];
[_bar release];
[super dealloc];
}
而在ARC中,我们就不需要再这么写了。因为ARC会调用Objective-C++的一项特性来生成清理例程(cleanup routine)。回收Objective-C++对象是时,待回收的对象会调用所有C++的析构函数(destructor)。编译器如果发现某个对象里含有C++对象,就会生成名为.cxx_destruct的方法。而ARC会借助此特性,在该方法中生成清理内存所需的代码。
不过,如果有非Objective-C的对象,比如CoreFoundation中的对象或是由malloc()分配在堆中的内存,那么仍然需要清理。ARC会自动在.cxx_destruct方法中生成代码并运行dealloc方法,儿子啊生成的代码中会自动调用超类的dealloc方法。ARC环境下,dealloc方法可以像这么来写
-(void)dealloc {
CFRelease(_coreFoundationObject);
free(_heapAllocateMemoryBlob);
}
第31条:在dealloc方法中只释放引用并解除监听
永远不要自己调用dealloc方法,运行期系统会在适当的时候调用它。根据性能需求我们有时需要在dealloc方法中做一些操作。那么我们可以在dealloc方法里做什么呢?
- 释放对象所拥有的所有引用,不过ARC会自动添加这些释放代码,可以不必操心。
- 而且对象拥有的其他非OC对象也要释放(CoreFoundation对象就必须手动释放)
- 释放原来的观测行为:注销通知。如果没有及时注销,就会向其发送通知,使得程序崩溃。
需要注意的是:
在dealloc方法中不应该调用其他的方法,因为如果这些方法是异步的,并且回调中还要使用当前对象,那么很有可能当前对象已经被释放了,会导致崩溃。同时,在dealloc方法中也不能调用属性的存取方法,因为很有可能在这些方法里还有其他操作。而且这个属性还有可能处于键值观察状态,该属性的观察者可能会在属性改变时保留或者使用这个即将回收的对象。
第32条:编写“异常安全代码”时留意内存管理问题
在当前的运行期系统中,C++与Objective-C的异常互相兼容。也就是说,从其中一门语言里抛出的异常能用另外一门语言所编的"异常处理程序"来捕获。
在try块中,如果先保留了某个对象,然后在释放它之前又抛出了异常,那么除非在catch块中能处理此问题,否则对象所占内存就将泄漏。C++的析构函数由Objective-C的异常处理例程来运行。这对于C++对象很重要,由于抛出异常会缩短生命周期,所以发生异常的时候必须析构,不然就会泄漏,而文件句柄等系统资源因为没有正确清理,所以就更容易因此而泄漏了。
@try {
EOCSomeClass *object = [[EOCSomeClass alloc] init];
[object doSomethingThatMayThrow];
[object release];
}
@catch (...) {
NSLog(@"Whoops, there was an error. Oh well...");
}
这里,我们用release方法释放了try中的对象,但是这样做仍然有问题:如果在doSomthingThatMayThrow方法中抛出了异常了呢?
这样就无法执行release方法了。
解决办法是使用@finnaly块,无论是否抛出异常,其中的代码都能运行:
EOCSomeClass *object;
@try {
object = [[EOCSomeClass alloc] init];
[object doSomethingThatMayThrow];
}
@catch (...) {
NSLog(@"Whoops, there was an error. Oh well...");
}
@finally {
[object release];
}
而在ARC状态下的时候,我们要这么写:
@try {
EOCSomeClass *object = [[EOCSomeClass alloc] init];
[object doSomethingThatMayThrow];
}
@catch (...) {
NSLog(@"Whoops, there was an error. Oh well...");
}
我们不能使用release方法了。解决办法就是需要打开编辑器的-fobjc-arc-exceptions标志。不过会导致应用程序过大,而且会降低运行效率。
第33条:以弱引用避免保留环
- 将某些引用设为weak,可以避免出现"保留环";
- weak引用可以自动清空,也可以不自动清空。自动清空是随着ARC而引入的新特性,由运行期系统来实现。在具备自动清空功能的弱引用上,可以随意读取其数据,因为这种引用不会指向已经回收过的对象。
第34条:以“自动释放池快”降低内存峰值
释放对象的两种方式:
- 调用release:保留计数递减
- 调用autorelease将其加入自动释放池中。在将来清空自动释放池时,系统会向其中的对象发送release消息。
OSX和iOS的应用程序分别运行于Cocoa和CocoaTouch环境中。系统会自动创建一些线程,比如说主线程或是GCD机制中单额线程,这些线程默认都有自动释放池,每次执行runloop时,就会自动将其清空。因为不需要自己来创建自动释放池,通常只有一个地方需要创建自动释放池,那就是在main函数里,我们用自动释放池来包裹应用程序的主入口点。比方说,iOS程序的main函数经常这样写:
int main(int argc, char * argv[]) {
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
内存峰值(high-memory waterline)是指应用程序在某个限定时段内的最大内存用量(highest memory footprint)。新增的自动释放池块可以减少这个峰值。
不用自动释放池减少峰值:
for (int i = 0; i < 100000; i++) {
[self doSomethingWithInt:i];
}
在这里,doSomethingWithInt:方法可能会创建临时对象。随着循环次数的增加,临时对象的数量也会飙升,而只有在整个for循环结束后,这些临时对象才会得意释放。
这种情况是不理想的,尤其在我们无法控制循环长度的情况下,我们会不断占用内存并突然释放掉它们。
又比如我们要从数据库中读取出很多对象时:
NSArray *databaseRecords = /* ... */;
NSMutableArray *people = [NSMutableArray new];
for (NSDictionary *record in databaseRecords) {
EOCPerson *person = [[EOCPerson alloc] initWithRecord:record];
[people addObject:person];
}
这样明显多在内存中多出很多不必要的临时对象。我们就可以使用内存释放池:
NSArray *databaseRecords = /* ... */;
NSMutableArray *people = [NSMutableArray new];
for (NSDictionary *record in databaseRecords) {
@autoreleasepool {
EOCPerson *person = [[EOCPerson alloc] initWithRecord:record];
[people addObject:person];
}
}
自动释放池机制就像栈一样。系统创建好自动释放池之后,就将其推入栈中,而清空自动释放池,则相当于将其从栈中弹出。在对象上执行自动释放操作,就等于将其放入栈顶的那个池里。
而且,自动释放池还有一个好处:每个自动释放池均有其范围,可以避免无意间误用了那些在清空池之后已经为系统所回收的对象。
第35条:用“僵尸对象”调试内存管理问题
某个对象被回收后,再向它发送消息是不安全的,这并不一定会引起程序崩溃。
如果程序没有崩溃,可能是因为:
- 该内存的部分原数据没有被覆写。
- 该内存恰好被另一个对象占据,而这个对象可以应答这个方法。
如果被回收的对象占用的原内存被新的对象占据,那么收到消息的对象就不会是我们预想的那个对象。在这样的情况下,如果这个对象无法响应那个方法的话,程序依旧会崩溃。
因此,我们希望可以通过一种方法捕捉到对象被释放后收到消息的情况。
这种方法就是利用僵尸对象!
Cocoa提供了“僵尸对象”的功能。如果开启了这个功能,运行期系统会把所有已经回收的实例转化成特殊的“僵尸对象”(通过修改isa指针,令其指向特殊的僵尸类),而不会真正回收它们,而且它们所占据的核心内存将无法被重用,这样也就避免了覆写的情况。
在僵尸对象收到消息后,会抛出异常,它会说明发送过来的消息,也会描述回收之前的那个对象。
在设置僵尸对象之后,对象所属的类会从xxxClass编程_NSZombie_xxxClass。_NSZombie_xxxClass实际上实在运行期中生成的,当首次碰到xxxClass类的对象要变成僵尸对象时,就会创建这么一个类。僵尸类从名为NSZombie的模板中辅助出来的。这些僵尸对象没有什么事情可以做,只是充当一个标记。运行期系统会给变成僵尸的类创建一个新类。创建新类的工作由运行期函数objc_duplicateClass()来完成,它会把整个NSZombie类结构拷贝一份,并赋予其新的名字,在名字中保留原来类的名字。
NSZombie类并未实现出任何方法,此类没有超类,因此和NSObject一样是个根类。类里是有一个实例变量,就是isa。由于没有实现任何方法,所以发给他的全部消息都要经过"完整的消息转发机制"。这样,我们就可以在栈回溯中查看到前缀为__NSZombie __的僵尸对象。会打印出僵尸对象所受到的消息及其原来所属的类。
第36条:不要使用retainCount
在非ARC得环境下使用retainCount可以返回当前对象的引用计数,但是在ARC环境下调用会报错,因为该方法已经被废弃了 。
它被废弃的原因是因为它所返回的引用计数只能反映对象某一时刻的引用计数,而无法“预知”对象将来引用计数的变化(比如对象当前处于自动释放池中,那么将来就会自动递减引用计数)。
第37条:理解block这一概念
说过很多了,推荐看这个
第38条:为常用的块类型创建typedef
如果我们需要重复创建某种块(相同参数,返回值)的变量,我们就可以通过typedef来给某一种块定义属于它自己的新类型。
int (^variableName)(BOOL flag, int value) =^(BOOL flag, int value){
// Implementation
return someInt;
}
这个块有一个bool参数和一个int参数,并返回int类型。我们可以给它定义类型:
typedef int(^EOCSomeBlock)(BOOL flag, int value);
再次定义的时候,就可以通过简单的赋值来实现:
EOCSomeBlock block = ^(BOOL flag, int value){
// Implementation
};
这么做的好处在于:
将代码做的更加容易使用
当你打算重构块的时候会很方便
第39条:用handler块降低代码分散程度
在界面编码的时候,我们经常使用异步执行任务。这么做的好处在于:处理用户界面的显示及触摸操作所用的线程,不会以内要执行I/O或网络通信这类耗时的任务而阻塞。这个线程我们一般称之为主线程。
异步方法在执行完任务之后,需要以某种手段通知相关代码。这里有很多的方法,比如说delegate和block。
与实现delegate模式相比,block写出来的代码更为整洁。异步任务执行完毕后所需要运行的业务逻辑,和启动异步任务所用的代码放在了一起。
同时,我们还可以用block的方式来处理错误。而且,在某些代码必须执行在特定的线程上的时候,会更加有效。
第40条:用块引用其所属对象时不要出现保留环
在使用块的时候,若不仔细思考,会很容易导致保留环。
情况一:
@implementation EOCClass {
EOCNetworkFetcher *_networkFetcher;
NSData *_fetchedData;
}
- (void)downloadData {
NSURL *url = [[NSURL alloc] initWithString:@"http://www.example.com/something.dat"];
_networkFetcher =[[EOCNetworkFetcher alloc] initWithURL:url];
[_networkFetcher startWithCompletionHandler:^(NSData *data){
NSLog(@"Request URL %@ finished", _networkFetcher.url);
_fetchedData = data;
}];
}
在这里出现了保留环:块要设置_fetchedData变量,就需要捕获self变量。而self(EOCClass实例)通过实例变量保留了获取器_networkFetcher,而_networkFetcher又保留了块。
解决方案是:在块中取得了data后,将_networkFetcher设为nil。
- (void)downloadData {
NSURL *url = [[NSURL alloc] initWithString:@"http://www.example.com/something.dat"];
_networkFetcher =[[EOCNetworkFetcher alloc] initWithURL:url];
[_networkFetcher startWithCompletionHandler:^(NSData *data){
NSLog(@"Request URL %@ finished", _networkFetcher.url);
_fetchedData = data;
_networkFetcher = nil;
}];
}
情况二:
- (void)downloadData {
NSURL *url = [[NSURL alloc] initWithString:@"http://www.example.com/something.dat"];
EOCNetworkFetcher *networkFetcher =[[EOCNetworkFetcher alloc] initWithURL:url];
[networkFetcher startWithCompletionHandler:^(NSData *data){
NSLog(@"Request URL %@ finished", _networkFetcher.url);
_fetchedData = data;
}];
}
这里其实也出现了保留环,block要通过获取获取器对象来引用url,于是block就要保留获取器,而同时获取器反过来也保留了这个块。我们要在接下来要进行的方法中做如下处理
-(void)p_requestCompleted{
if(_completionHandler){
_completionHandler(_downloadData);
}
self.completionHandler = nil;
}
第41条:多用派发队列,少用同步锁
多个线程执行同一份代码时,很可能会造成数据不同步。作者建议使用GCD来为代码加锁的方式解决这个问题。
方案一:使用串行同步队列来将读写操作都安排到同一个队列里:
_syncQueue = dispatch_queue_create("com.effectiveobjectivec.syncQueue", NULL);
//读取字符串
- (NSString*)someString {
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
//设置字符串
- (void)setSomeString:(NSString*)someString {
dispatch_sync(_syncQueue, ^{
_someString = someString;
});
}
方案二:将写操作放入栅栏快中,让他们单独执行;将读取操作并发执行。
_syncQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
//读取字符串
- (NSString*)someString {
__block NSString *localSomeString;
dispatch_sync(_syncQueue, ^{
localSomeString = _someString;
});
return localSomeString;
}
//设置字符串
- (void)setSomeString:(NSString*)someString {
dispatch_barrier_async(_syncQueue, ^{
_someString = someString;
});
}
显然,数据的正确性主要取决于写入操作,那么只要保证写入时,线程是安全的,那么即便读取操作是并发的,也可以保证数据是同步的。
这里的dispatch_barrier_async方法使得操作放在了同步队列里“有序进行”,保证了写入操作的任务是在串行队列里。
第42条:多用GCD,少用performSelector系列方法
因为Objective-C语言的特性。编译器并不知道要调用的选择子是什么,因此,也就不了解其方法签名及返回值,甚至连是否有返回值都不清楚。而且因为不了解方法名,所以就没办法运用ARC的内存管理机制来判断返回值是否应该释放。
使用performSelector来执行某个方法,但是performSelector系列的方法能处理的选择子很局限:它无法处理带有两个以上的参数的选择子;返回值只能是对象类型。
但是我们如果使用block和GCD,就可以解决这些问题。
- 延后执行某个任务的方法:
// 使用 performSelector:withObject:afterDelay:
[self performSelector:@selector(doSomething) withObject:nil afterDelay:5.0];
// 使用 dispatch_after
dispatch_time_t time = dispatch_time(DISPATCH_TIME_NOW, (int64_t)(5.0 * NSEC_PER_SEC));
dispatch_after(time, dispatch_get_main_queue(), ^(void){
[self doSomething];
});
- 将任务放在主线程执行:
// 使用 performSelectorOnMainThread:withObject:waitUntilDone:
[self performSelectorOnMainThread:@selector(doSomething) withObject:nil waitUntilDone:NO];
// 使用 dispatch_async
// (or if waitUntilDone is YES, then dispatch_sync)
dispatch_async(dispatch_get_main_queue(), ^{
[self doSomething];
});
这里我们都优先考虑第二种。
第43条:掌握GCD及操作队列的使用时机
除了GCD,操作队列(NSOperationQueue)也是解决多线程任务管理问题的一个方案。对于不同的环境,我们要采取不同的策略来解决问题:有时候使用GCD好些,有时则是使用操作队列更加合理。
GCD是纯C语言实现的API,而NSOperationQueue是Objective-C的。
使用NSOperation和NSOperationQueue的优点:
- 可以取消操作:在运行任务前,可以在NSOperation对象调用cancel方法,标明此任务不需要执行。但是GCD队列是无法取消的,因为它遵循“安排好之后就不管了(fire and forget)”的原则。
- 可以指定操作间的依赖关系:例如从服务器下载并处理文件的动作可以用操作来表示。而在处理其他文件之前必须先下载“清单文件”。而后续的下载工作,都要依赖于先下载的清单文件这一操作。
- 监控NSOperation对象的属性:可以通过KVO来监听NSOperation的属性:可以通过isCancelled属性来判断任务是否已取消;通过isFinished属性来判断任务是否已经完成。
- 可以指定操作的优先级:操作的优先级表示此操作与队列中其他操作之间的优先关系,我们可以指定它。
- 重用NSOperation对象。我们如要创建NSOperation的子类,可以方便的使用其中的方法。
第44条:通过Dispath Group机制,根据系统资源状况来执行任务
有时需要等待多个并行任务结束的那一刻执行某个任务,这个时候就可以使用dispath group函数来实现这个需求:
通过dispath group函数,可以把并发执行的多个任务合为一组,于是调用者就可以知道这些任务何时才能全部执行完毕。
//一个优先级低的并发队列
dispatch_queue_t lowPriorityQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0);
//一个优先级高的并发队列
dispatch_queue_t highPriorityQueue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0);
//创建dispatch_group
dispatch_group_t dispatchGroup = dispatch_group_create();
//将优先级低的队列放入dispatch_group
for (id object in lowPriorityObjects) {
dispatch_group_async(dispatchGroup,lowPriorityQueue,^{ [object performTask]; });
}
//将优先级高的队列放入dispatch_group
for (id object in highPriorityObjects) {
dispatch_group_async(dispatchGroup,highPriorityQueue,^{ [object performTask]; });
}
//dispatch_group里的任务都结束后调用块中的代码
dispatch_queue_t notifyQueue = dispatch_get_main_queue();
dispatch_group_notify(dispatchGroup,notifyQueue,^{
// Continue processing after completing tasks
});
是用GCD会在适当的时候自动创建新线程或者复用旧线程。在并发队列中,执行任务所用的并发线程数量,取决于各种因素,而GCD主要是根据系统资源状况来判定这些因素的。通过dispatch group所提供的这种简便方式,既可以并发执行一系列给定的文物,又能在全部任务结束的时候得到通知。由于GCD有并发队列机制,所以能够根据可用的系统资源状况来并发执行任务。
第45条:使用dispatch_once来执行只需运行一次的线程安全代码
有时我们可能只需要将某段代码执行一次,这时可以通过dispatch_once函数来解决。
dispatch_once函数比较重要的使用例子是单例模式:
我们在创建单例模式的实例时,可以使用dispatch_once函数来令初始化代码只执行一次,并且内部是线程安全的。
而且,对于执行一次的block来说,每次调用函数时传入的标记都必须完全相同,通常标记变量声明在static或global作用域里。
+ (id)sharedInstance {
static EOCClass *sharedInstance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
sharedInstance = [[self alloc] init];
});
return sharedInstance;
}
使用dispatch_once可以简化代码并且彻底保证线程安全,开发者无需担心加锁或者同步。另外,dispatch_once方法更加高效,此函数采用原子访问(atomic access)来查询标记,以判断所对应的代码是否已经执行过。
第46条:不要使用dispatch_get_current_queue
我们无法用某个队列来描述“当前队列”这一属性,因为派发队列是按照层级来组织的。
[图片上传失败...(image-74a524-1527207303216)]
安排在某条队列中的快,会在其上层队列中执行,而层级地位最高的那个队列总是全局并发队列。
在这里,B,C中的块会在A里执行。但是D中的块,可能与A里的块并行,因为A和D的目标队列是并发队列。
正因为有了这种层级关系,所以检查当前队列是并发的还是非并发的就不会总是很准确。
dispatch_get_current_queue函数能够用于解决由不可重入的队列代码所引发的死锁,然而能用此函数解决的问题,也能用dispatch_queue_set_specific来解决。
第47条:熟悉系统框架
如果我们使用了系统提供的现成的框架,那么用户在升级系统后,就可以直接享受系统升级所带来的改进。
主要的系统框架:
Foundation:NSObject,NSArray,NSDictionary等
CFoundation框架:C语言API,Foundation框架中的许多功能,都可以在这里找到对应的C语言API
CFNetwork框架:C语言API,提供了C语言级别的网络通信能力
CoreAudio:C语言API,操作设备上的音频硬件
AVFoundation框架:提供的OC对象可以回放并录制音频和视频
CoreData框架:OC的API,将对象写入数据库
CoreText框架:C语言API,高效执行文字排版和渲染操作
用C语言来实现API的好处:可以绕过OC的运行期系统,从而提升执行速度。用纯C写成的框架与用Objective-C写成的一样重要,若想成为优秀的Objective-C开发者,应该掌握C语言的核心概念。
第48条:多用块枚举,少用for循环
当遍历集合元素时,建议使用块枚举,因为相对于传统的for循环,它更加高效,而且简洁,还能获取到用传统的for循环无法提供的值:
我们首先看一下传统的遍历:
传统的for遍历
NSArray *anArray = /* ... */;
for (int i = 0; i < anArray.count; i++) {
id object = anArray[i];
// Do something with 'object'
}
// Dictionary
NSDictionary *aDictionary = /* ... */;
NSArray *keys = [aDictionary allKeys];
for (int i = 0; i < keys.count; i++) {
id key = keys[i];
id value = aDictionary[key];
// Do something with 'key' and 'value'
}
// Set
NSSet *aSet = /* ... */;
NSArray *objects = [aSet allObjects];
for (int i = 0; i < objects.count; i++) {
id object = objects[i];
// Do something with 'object'
}
我们可以看到,在遍历NSDictionary,和NSet时,我们又新创建了一个数组。虽然遍历的目的达成了,但是却加大了系统的开销。
利用快速遍历:
NSArray *anArray = /* ... */;
for (id object in anArray) {
// Do something with 'object'
}
// Dictionary
NSDictionary *aDictionary = /* ... */;
for (id key in aDictionary) {
id value = aDictionary[key];
// Do something with 'key' and 'value'
}
NSSet *aSet = /* ... */;
for (id object in aSet) {
// Do something with 'object'
}
这种快速遍历的方法要比传统的遍历方法更加简洁易懂,但是缺点是无法方便获取元素的下标。
利用基于block的遍历:
NSArray *anArray = /* ... */;
[anArray enumerateObjectsUsingBlock:^(id object, NSUInteger idx, BOOL *stop){
// Do something with 'object'
if (shouldStop) {
*stop = YES; //使迭代停止
}
}];
“// Dictionary
NSDictionary *aDictionary = /* ... */;
[aDictionary enumerateKeysAndObjectsUsingBlock:^(id key, id object, BOOL *stop){
// Do something with 'key' and 'object'
if (shouldStop) {
*stop = YES;
}
}];
// Set
NSSet *aSet = /* ... */;
[aSet enumerateObjectsUsingBlock:^(id object, BOOL *stop){
// Do something with 'object'
if (shouldStop) {
*stop = YES;
}
我们可以看到,在使用块进行快速枚举的时候,我们可以不创建临时数组。虽然语法上没有快速枚举简洁,但是我们可以获得数组元素对应的序号,字典元素对应的键值,而且,我们还可以随时令遍历终止。
利用快速枚举和块的枚举还有一个优点:能够修改块的方法签名
for (NSString *key in aDictionary) {
NSString *object = (NSString*)aDictionary[key];
// Do something with 'key' and 'object'
}
NSDictionary *aDictionary = /* ... */;
[aDictionary enumerateKeysAndObjectsUsingBlock:^(NSString *key, NSString *obj, BOOL *stop){
// Do something with 'key' and 'obj'
}];
如果我们可以知道集合里的元素类型,就可以修改签名。这样做的好处是:可以让编译期检查该元素是否可以实现我们想调用的方法,如果不能实现,就做另外的处理。这样一来,程序就能变得更加安全。
个人添加
- block遍历还有一个明显的优点:如果数组的数量过多,除了block遍历,其他的遍历方法都需要添加autoreleasePool方法来优化。block不需要,因为系统在实现它的时候就已经实现了相关处理。
第49条:对自定义其内存管理语义的collection使用无缝桥接
通过无缝桥接技术,可以再Foundation框架中的OC对象和CoreFoundation框架中的C语言数据结构之间来回转换。
创建CoreFoundation中的collection时,可以指定如何处理其中的元素。然后利用无缝桥接技术,可以将其转换为OCcollection。
简单的无缝桥接演示:
NSArray *anNSArray = @[@1, @2, @3, @4, @5];
CFArrayRef aCFArray = (__bridge CFArrayRef)anNSArray;
NSLog(@"Size of array = %li", CFArrayGetCount(aCFArray));
这里,__bridge表示ARC仍然具备这个OC对象的所有权。CFArrayGetCount用来获取数组的长高度。
为什么要使用无缝桥接技术呢?因为有些OC对象的特性是其对应的CF数据结构不具备的,反之亦然。因此我们需要通过无缝桥接技术来让这两者进行功能上的“互补”。
第50条:构建缓存时选用NSCache 而非NSDictionary
如果我们缓存使用得当,那么应用程序的响应速度就会提高。只有那种“重新计算起来很费事的数据,才值得放入缓存”,比如那些需要从网络获取或从磁盘读取的数据。
在构建缓存的时候很多人习惯用NSDictionary或者NSMutableDictionary,但是作者建议大家使用NSCache,它作为管理缓存的类,有很多特点要优于字典,因为它本来就是为了管理缓存而设计的。
NSCache优于NSDictionary的几点:
- 当系统资源将要耗尽时,NSCache具备自动删减缓冲的功能。并且还会先删减“最久未使用”的对象。
NSCache不拷贝键,而是保留键。因为并不是所有的键都遵从拷贝协议(字典的键是必须要支持拷贝协议的,有局限性)。- NSCache是线程安全的:不编写加锁代码的前提下,多个线程可以同时访问NSCache。
关于操控NSCache删减内容的时机
开发者可以通过两个尺度来调整这个时机:
缓存中的对象总数.
将对象加入缓存时,为其指定开销值。
对于开销值,只有在能很快计算出开销值的情况下,才应该考虑采用这个尺度,不然反而会加大系统的开销。
NSPurgeableData是NSMutableData的子类,把它和NSCache配合使用效果很好。
因为当系统资源紧张时,可以把保存NSPurgeableData的那块内存释放掉。
如果需要访问某个NSPurgeableData对象,可以调用beginContentAccess方发,告诉它现在还不应该丢弃自己所占据的内存。
在使用完之后,调用endContentAccess方法,告诉系统在必要时可以丢弃自己所占据的内存。
- 如果缓存使用得当,那么应用程序的响应速度就能提高。只有那种"重新计算起来很费事"的数据,才值得放入缓存,比如那些需要从网络获取或者从磁盘读取的数据。
第51条: 精简initialize 与 load的实现代码
每个类和分类在加入运行期系统时,都会调用load方法,而且仅仅调用一次,可能有些小伙伴习惯在这里调用一些方法,但是作者建议尽量不要在这个方法里调用其他方法,尤其是使用其他的类。原因是每个类载入程序库的时机是不同的,如果该类调用了还未载入程序库的类,就会很危险。而且,load方法并不会遵从继承规则。如果某个类本身没实现load方法,那么不管其各级超类是否实现此方法,系统都不会调用。
initialize方法与load方法类似,区别是这个方法会在程序首次调用这个类的时候调用(惰性调用),而且只调用一次(绝对不能主动使用代码调用)。值得注意的一点是,如果子类没有实现它,它的超类却实现了,那么就会运行超类的代码:这个情况往往很容易让人忽视。
在实现initalize方法时,需要加判断是否是本类:
+ (void)initialize {
if (self == [EOCBaseClass class]) {
NSLog(@"%@ initialized", self);
}
}
- 在initalize方法里应该只用来设置内部数据。不应该调用方法,即使是本类方法。
- 无法再编译期设定的全局变量(比如说NSMutableArray),可以放在initialize里实现。
| load | initialize | |
|---|---|---|
| 调用时间 | 被添加到 runtime 时 | 收到第一条消息前,可能永远不调用 |
| 调用顺序 | 父类->子类->分类 | 父类->子类 |
| 调用次数 | 1次 | 多次 |
| 是否沿用父类的实现 | NO | YES |
| 分类中的实现 | 类和分类都执行 | 覆盖类中的方法,只执行分类的实现 |
第52条: 别忘了NSTimer会保留其目标对象
在使用NSTimer的时候,NSTimer会生成指向其使用者的引用,而其使用者如果也引用了NSTimer,那么就会生成保留环。
#import
@interface EOCClass : NSObject
- (void)startPolling;
- (void)stopPolling;
@end
@implementation EOCClass {
NSTimer *_pollTimer;
}
- (id)init {
return [super init];
}
- (void)dealloc {
[_pollTimer invalidate];
}
- (void)stopPolling {
[_pollTimer invalidate];
_pollTimer = nil;
}
- (void)startPolling {
_pollTimer = [NSTimer scheduledTimerWithTimeInterval:5.0
target:self
selector:@selector(p_doPoll)
userInfo:nil
repeats:YES];
}
- (void)p_doPoll {
// Poll the resource
}
@end
在这里,在EOCClass和_pollTimer之间形成了保留环,如果不主动调用stopPolling方法就无法打破这个保留环。
那么我们要如何解决呢?用block
通过给NSTimer增加一个分类就可以解决:
#import
@interface NSTimer (EOCBlocksSupport)
+ (NSTimer*)eoc_scheduledTimerWithTimeInterval:(NSTimeInterval)interval
block:(void(^)())block
repeats:(BOOL)repeats;
@end
@implementation NSTimer (EOCBlocksSupport)
+ (NSTimer*)eoc_scheduledTimerWithTimeInterval:(NSTimeInterval)interval
block:(void(^)())block
repeats:(BOOL)repeats
{
return [self scheduledTimerWithTimeInterval:interval
target:self
selector:@selector(eoc_blockInvoke:)
userInfo:[block copy]
repeats:repeats];
}
+ (void)eoc_blockInvoke:(NSTimer*)timer {
void (^block)() = timer.userInfo;
if (block) {
block();
}
}
@end
我们在NSTimer类里添加了方法,我们来看一下如何使用它:
- (void)startPolling {
__weak EOCClass *weakSelf = self;
_pollTimer = [NSTimer eoc_scheduledTimerWithTimeInterval:5.0 block:^{
EOCClass *strongSelf = weakSelf;
[strongSelf p_doPoll];
}
repeats:YES];
}
在这里,创建了一个self的弱引用,然后让块捕获了这个self变量,让其在执行期间存活。
一旦外界指向EOC类的最后一个引用消失,该类就会被释放,被释放的同时,也会向NSTimer发送invalidate消息(因为在该类的dealloc方法中向NSTimer发送了invalidate消息)。
而且,即使在dealloc方法里没有发送invalidate消息,因为块里的weakSelf会变成nil,所以NSTimer同样会失效。