标签(空格分隔): Glibc, Thread, 线程栈
前言
前几天自己写了一段基于线程模型的网络程序,即主线程对每个连接请求创建一个工作线程,工作线程处理接下来所有业务。主线程希望工作线程完成后自动结束并释放资源(请别问我这么 Low 的代码用来干嘛,我就自己写两行来玩的 v)。这个时候容易犯一个错(大神请绕道),那就是既不调join操作(因为主线程并不关注工作线程什么时候结束),也不将工作线程detach。这个错误的后果就是导致资源泄露,当然解决这个问题最简单的方法是将工作线程设置为detach状态,系统就会自动完成资源的回收。显然如果本篇博客只是想描述怎么解决这个问题,那么显然没有写一篇文章的必要。本文真正要描述的是线程的资源是怎么自动释放的,这毫无疑问涉及到线程有哪些资源以及是如何管理的问题。 在此之前,需要说明一下,本文中描述所描述的适用于 Linux 系统,x86_64 平台,至于其它平台是否适用我也不知道,哈哈。
背景
本节线程模型的内容来自 Linux 线程模型的比较:LinuxThreads 和 NPTL。
对 Linux 有所了解就会知道, Linux 内核并不能真正支持线程,而是通过进程间共享资源(内存空间、文件等)的方式模拟线程,又被称之为轻量级进程(LWP)。最早 LinuxThreads 项目希望在用户空间模拟对线程的支持。LinuxThreads 采用的是一对一的线程模型,为了解决信号处理、调度和进程间同步原语方面的问题, LinuxThreads 引入了一个管理线程,以满足响应终止信号杀死整个进程,完成线程结束后的内存回收等任务。但是管理线程的引入也带来系统伸缩性与性能的问题。并且, LinuxThreads 并不符合 POSIX 标准。
NPTL 的出现改变了 LinuxThreads 尴尬的现状。不过,NPTL 不仅仅是一个用户态的线程库,同时它也对系统内核做了一定的要求, 因此有时在谈论 Linux 内核没有线程概念时并不十分准确,例如为了支持 nptl 线程内核 task_struct 是引入了 pid 与 tgid 的区别, 因而准确的说法应该是内核在调度的时候没有线程的概念,这都是题外话了。NPTL 作为 Linux 线程的新的实现,它移除了 LinuxThreads 中的管理线程,因而其在 NUMA 与 SMP 系统上更好的伸缩性与同步机制。此外,NPTL 是符合 POSIX 需求的, glibc2.3.5 开始就全面使用 NPTL 模型了,所在现在使用的 Linux 线程模型都是已经 NPTL 了。 本文中描述的资源管理都是指 NPTL 模型中的资源管理。更多的关于 LinuxThreads 与 NPTL 的内容可以参考 Linux 线程模型的比较:LinuxThreads 和 NPTL。
此外需要说明一点, 无论是 LinuxThreads 还是 NPTL, 它们都使用了一对一的线程模型,也即一个用户态线程对应一个内核态LWP,线程的调度是由内核完成的。
线程内核资源
线程资源可以粗略地分为两类,内核资源(例如 task_struct)以及用户态内存资源(主要是线程栈)。在 Linux 平台上,进程的内核资源释放是通过父进程使用 wait 系统调用完成的,如果父进程没有调用该操作,就会出现僵尸进程,直到父进程结束。对于线程而言,Linux 还提供了内核自动释放的功能。参考 glibc-2.25 源码描述 (sysdeps/unix/sysv/linux/createthread.c)
const int clone_flags =
(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM
| CLONE_SIGHAND | CLONE_THREAD
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID
| 0);
上述代码是 glibc 在调用 clone 创建线程时传入的 flag 参数,在本文中我们需要注意三个参数: CLONE_THREAD, CLONE_PARENT_SETTID,CLONE_CHILD_CLEARTID。后面两个参数与后面讲述线程栈的释放有关。 关于 CLONE_THREAD 参数的描述如下:
When a CLONE_THREAD thread terminates, the thread that created it using clone() is not sent a SIGCHLD (or other termination) signal; nor can the status of such a thread be obtained using wait(2).
这段说明,当使用 CREATE_THREAD 参数创建线程后,此线程结束时不会发送 SIGCHLD 信号,而且不能使用 wait 获得其状态,其间接地说明了,内核在某个时机自动释放了该线程的内核资源,而至于是否有其它方式获得该线程的状态,以后再讨论这个问题。
线程栈的管理
对于多线程程序而言,堆资源是共享的,所有的线程都使用一个堆区。但是栈区是独立的,每个线程都必须有自己的独立的栈区,那么这些栈区是如何管理的呢?
线程栈的布局
在讨论线程栈的布局的时候,涉及到一个十分重要的数据结构 struct pthread。它存储了线程的相关信息担任线程的管理功能。其数据结构比较复杂,再这里我们只展示几个与本文讨论内容相关的变量,完整的内容可以从 nptl/descr.h 文件中查看。
/* This descriptor's link on the `stack_used' or `__stack_user' list. */
list_t list;
/* Thread ID - which is also a 'is this thread descriptor (and
therefore stack) used' flag. */
pid_t tid;
list 用于将此结构体挂于双链表中,这也是 Linux 内核中十分常见的一种数据结构。 tid 存储了线程的 ID 值。 从代码中的注释也可以看出 list 和 tid 都将用于线程栈的管理。
struct pthread 是用于用户态描述线程的数据结构,那么显然每个 pthread 都唯一对应一个线程。那么这个变量是存储在哪里的,答案是线程栈内存块的高地址空间中的(这里以 x86 栈向下增长的方式为例)。也就是说,创建线程时为每个线程分配了一块内存,然后这块内存一部分存储了 pthread 变量,剩下的内存才是真正的线程栈。熟悉 Linux 内核栈 结构的人会对这种方式比较熟悉。下图展示了 x86 上线程栈的简要布局:
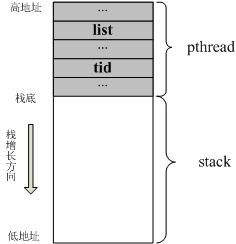
Talk is cheap, show me the code.
在创建线程的函数 __pthread_create_2_1 中(nptl/pthrea_create.c),调用 ALLOCATE_STACK 宏用于分配线程栈,该宏即函数 allcate_stack (nptl/allocatestack.c)。
struct pthread *pd;
...
/* The user provided some memory. Let's hope it matches the
size... We do not allocate guard pages if the user provided
the stack. It is the user's responsibility to do this if it is wanted. */
#if TLS_TCB_AT_TP
pd = (struct pthread *) ((uintptr_t) stackaddr
- TLS_TCB_SIZE - adj);
#elif TLS_DTV_AT_TP
pd = (struct pthread *) (((uintptr_t) stackaddr
- __static_tls_size - adj)
- TLS_PRE_TCB_SIZE);
#endif
这段代码是用户自己提供内存块用作线程栈时的代码,此处 stackaddr 指向所分配内存块的高地址。因此,从代码中可以看出来,无论从哪个分支编译,pd 都指向该内存块高地址端一块内存。换句话说在线程栈内存块中存储了一个 pthread 对象。 至于这其中复杂的地址预留策略,例如对齐等,就不在此细说,有兴趣可以直接去阅读代码。nptl 自动分配线程栈的处理代码是类似的,其注释说明的已经非常清楚了,如下所示:
/* Place the thread descriptor at the end of the stack. */
#if TLS_TCB_AT_TP
pd = (struct pthread *) ((char *) mem + size - coloring) - 1;
#elif TLS_DTV_AT_TP
pd = (struct pthread *) ((((uintptr_t) mem + size - coloring
- __static_tls_size)
& ~__static_tls_align_m1)
- TLS_PRE_TCB_SIZE);
#endif
线程栈的管理结构
glibc 中使用了链表的形式来管理所有内存栈,其中定义了两个全局变量(nptl/allocatestack.c):
/* List of queued stack frames. */
static LIST_HEAD (stack_cache);
/* List of the stacks in use. */
static LIST_HEAD (stack_used);
而 LIST_HEAD 定义(include/list.h):
/* Define a variable with the head and tail of the list. */
# define LIST_HEAD(name) \
list_t name = { &(name), &(name) }
可以看出,上面的代码定义了两个链表头, stack_cache 用于存放没有使用的栈内存,而 stack_used 是正在使用的栈内存块。
前面提到 pthread 是存储在分配的栈内存块中的,同时 pthread 中存在一个管理变量 list, 该变量即可将栈内存块挂载到不同的链表中。 如果内存栈在使用过程中时,则内存块被放入 stack_used 队列中; 当线程结束后,该内存块被移入 stack_cache 队列中,可以供下次创建线程时直接使用。
线程栈的分配
创建线程时,既可以由用户自己分配内存作为线程的栈区,也可以由库自动为线程分配栈区。这里我们看一下线程分配栈内存的过程。
在 allocatestack 函数中,当用户没有传入栈区内存地址时,库首先会调用 get_cached_stack 函数尝试从缓存中分配一块内存:
...
/* Search the cache for a matching entry. We search for the
smallest stack which has at least the required size. Note that
in normal situations the size of all allocated stacks is the
same. As the very least there are only a few different sizes.
Therefore this loop will exit early most of the time with an
exact match. */
list_for_each (entry, &stack_cache)
{
struct pthread *curr;
curr = list_entry (entry, struct pthread, list);
if (FREE_P (curr) && curr->stackblock_size >= size)
{
if (curr->stackblock_size == size)
{
result = curr;
break;
}
if (result == NULL
|| result->stackblock_size > curr->stackblock_size)
result = curr;
}
}
...
/* Dequeue the entry. */
stack_list_del (&result->list);
其中主要逻辑很简单,就是从 stack_cache 中找到一个空闲的栈内存, 其中 FREE_P 用于判断是否空闲。事实上该宏就是判断 pthread 结构中 tid 值是否小于或等于 0, 若是则该块地址是空闲的。 并将该 内存块从列表中取出来。
/* Check whether the stack is still used or not. */
#define FREE_P(descr) ((descr)->tid <= 0)
如果没有空闲的内存块,那么就需要调用 mmap 去重新分配内存了。
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
为线程成功获得一块内存块后,按前面分析会挂入 stack_used 列表中。这一步骤也是在 allocate_stack 函数中完成的,如下:
/* Prepare to modify global data. */
lll_lock (stack_cache_lock, LLL_PRIVATE);
/* And add to the list of stacks in use. */
stack_list_add (&pd->list, &stack_used);
lll_unlock (stack_cache_lock, LLL_PRIVATE);
如上,即完成了线程栈的分配。
线程栈的释放
线程栈的释放我们需要搞清楚下面两个问题:
由谁释放?
对于非 detach 的线程,这个问题答案十分明显,线程的栈区将由调用 Join 操作的线程来完成释放。但是对于 detach 线程,这个问题就不是那么清楚了。 没有其它线程来显式的释放栈区,那么这个栈区的释放只能交由线程自己来完成。也就是说,一个线程需要自己释放自己正在使用的栈内存块。这听上去就是胡扯嘛,正在用怎么能释放呢。但是仔细想一下,如果栈区没有使用了,那么线程已经结束,它更没办法去释放自己的栈内存了。这时就需要 Linux 内核的支持了。怎么释放?
事实上,线程释放自己的栈区也并非真正意义上的释放该内存块,而是将该内存块从 stack_used 移除,放入 stack_cache 链表中, 同时修改标志位,而将内存真正的释放操作推迟到其它线程中完成。释放过程被分为如下步骤:(1) 将栈内存块从 stack_used 取下放入 stack_cache 列表中。(2) 释放 stack_cache 中已结束线程的栈内存块。这里是否已结束是根据 pthread tid 位是否被清零来业判断的。(3) 线程结束时, 由内核清除标志位(tid), 这一步骤是由内核完成的,当线程结束时,内核会自动将tid清零,这就意味着一旦 tid 被清零就意味着线程已经结束。需要注意:前两步是由线程完成,而每三步是由内核来完成的。
可以看出,针对自己的栈内存,每个线程只是将其放入 stack_cache 链表中,而该内存块真正的释放操作是由别的线程来完成的。所以会存在这样一个时间段,线程正在使用过程中却已经被放到 stack_cache 链表中了,而线程真正结束的标志是由 Linux 内核来完成的,只由 tid 被清零的栈内存才可能被真正的释放掉。
当用户执行完用户指定的函数后,进入清理工作。整个线程的入口函数是 START_THREAD_DEFN(nptl/pthread_create.c)
,该宏定义为:
#def START_THREAD_DEFN \
static void __attribute__ ((noreturn)) start_thread(void)
所以,其实该宏其实是一个函数的签名。在这个函数中,调用用户提供的函数(pd->start_routine(pd->arg))。 下面 THREAD_SETMEM 宏的作用是执行函数的结果存储在 pthread 的 result 变量中。
/* Run the code the user provided. */
#ifdef CALL_THREAD_FCT
THREAD_SETMEM (pd, result, CALL_THREAD_FCT (pd));
#else
THREAD_SETMEM (pd, result, pd->start_routine (pd->arg));
#endif
当用户函数执行完后, start_thread 函数会进行清理工作。如果发现线程是 detach 状态,则会主动进行资源的释放,否则将等待 join 操作来释放:
...
/* If the thread is detached free the TCB. */
if (IS_DETACHED (pd))
/* Free the TCB. */
__free_tcb (pd);
...
真正的释放操作发生在 __deallocate_stack 函数中,
void
internal_function
__deallocate_stack (struct pthread *pd)
{
lll_lock (stack_cache_lock, LLL_PRIVATE);
/* Remove the thread from the list of threads with user defined
stacks. */
stack_list_del (&pd->list);
/* Not much to do. Just free the mmap()ed memory. Note that we do
not reset the 'used' flag in the 'tid' field. This is done by
the kernel. If no thread has been created yet this field is
still zero. */
if (__glibc_likely (! pd->user_stack))
(void) queue_stack (pd);
else
/* Free the memory associated with the ELF TLS. */
_dl_deallocate_tls (TLS_TPADJ (pd), false);
lll_unlock (stack_cache_lock, LLL_PRIVATE);
}
/* Add a stack frame which is not used anymore to the stack. Must be called with the cache lock held. */
static inline void
__attribute ((always_inline))
queue_stack (struct pthread *stack)
{
/* We unconditionally add the stack to the list. The memory may
still be in use but it will not be reused until the kernel marks
the stack as not used anymore. */
stack_list_add (&stack->list, &stack_cache);
stack_cache_actsize += stack->stackblock_size;
if (__glibc_unlikely (stack_cache_actsize > stack_cache_maxsize))
__free_stacks (stack_cache_maxsize);
}
这一幕何其熟悉,首先将将内存块从 stack_used 链表中移除(stack_list_del (&pd->list););再调用 queue_stack 函数将其添加到 stack_cache 链表中。 如上完成了第一步了。
glibc 允许缓存一部分内存块,只有当内存块的大小超过 stack_cache_maxsize 时才会释放掉一部分内存块,这也就是为什么会有分配阶段的 get_cached_stack 的操作了。 具体的释放过程如下:
/* Free stacks until cache size is lower than LIMIT. */
void
__free_stacks (size_t limit)
{
/* We reduce the size of the cache. Remove the last entries until
the size is below the limit. */
list_t *entry;
list_t *prev;
/* Search from the end of the list. */
list_for_each_prev_safe (entry, prev, &stack_cache)
{
struct pthread *curr;
curr = list_entry (entry, struct pthread, list);
if (FREE_P (curr))
{
/* Unlink the block. */
stack_list_del (entry);
/* Account for the freed memory. */
stack_cache_actsize -= curr->stackblock_size;
/* Free the memory associated with the ELF TLS. */
_dl_deallocate_tls (TLS_TPADJ (curr), false);
/* Remove this block. This should never fail. If it does
something is really wrong. */
if (munmap (curr->stackblock, curr->stackblock_size) != 0)
abort ();
/* Maybe we have freed enough. */
if (stack_cache_actsize <= limit)
break;
}
}
}
该函数过程就是就是遍历 stack_cache 链表,从中判断使用该内存的线程是否结束(FREE_P),即内存块中 pthread 的 tid 值是否被清零,并释放掉一部分内存(munmap)。其中包含了 TLS 内存释放的操作,本文中暂不做讨论。
当前线程结束时的 tid 操作是怎么完成的呢?希望你还记得前面说过的 clone 系统调用时传入的 flag 参数 CLONE_PARENT_SETTID 与 CLONE_CHILD_CLEARTID。这两个参数的说明如下:
CLONE_CHILD_CLEARTID (since Linux 2.5.49)
Clear (zero) the child thread ID at the location ctid in child memory when the child exits, and do a wakeup on the futex at that address. The address involved may be changed by the set_tid_address(2) system call. This is used by threading libraries.
CLONE_PARENT_SETTID (since Linux 2.5.49)
Store the child thread ID at the location ptid in the parent's memory. (In Linux 2.5.32-2.5.48 there was a flag CLONE_SETTID that did this.) The store operation completes before clone() returns control to user space.
简单来说, CLONE_PARENT_SETTID 参数要求内核在 clone 操作完成前将父进程空间的某个指定内存位置填上子线程的 ID 值; CLONE_CHILD_CLEARTID 则要求内核在线程结束后将子线程空间的某个指定内存位置处的值清零。当然,针对线程而言都是在同一个内存空间中。那么 glibc 在调用 clone 传入的参数是怎么样的呢? 如下,
if (__glibc_unlikely (ARCH_CLONE (&start_thread, STACK_VARIABLES_ARGS,
clone_flags, pd, &pd->tid, tp, &pd->tid)
== -1))
这里 ARCH_CLONE 是 glibc 对底层做的一层封装,它是直接使用的 ABI 接口,代码是用汇编语言写的,x86_64 平台的代码在 (sysdeps/unix/sysv/linux/x86_64/clone.S) 文件中, 感兴趣可以自己去看。你会发现其实就是就是调用了 linux 提供的 clone 接口。所以也可以直接参考 Linux 手册上对 clone 函数的描述,此宏与 clone 参数是一样的。 我们可以看出此处,函数两次传入的都子线程 pthread 中 tid 值,以让内核在线程开始时设置线程 ID 以及线程结束时清除其 ID 值。这样此线程的栈内存块就可以被随后的线程释放了。
综上,我们就分析完了线程栈的释放过程。
除了本文描述的线程栈,线程资源还应该包括 TLS 等。在本文中,我们并没有分析这些资源是怎么管理的。这方面内容留做以后的工作吧。