探索底层的意义
话说人们在1870年左右开始应用黄色火药,在1900年左右开始大量普及电动地铁,并建成了埃菲尔铁塔(1898)等伟大工程,但是军事技术的发展、革新最多的仅是二战前后的1936到1945的这几年时间,现在的军事技术也大都仅是对二战时的军事技术体系的深化,如自动步枪,喷气引擎,潜艇,坦克和反坦克等等。所以我们认为,高强度的行业竞争,带来其领域技术的深入发展,而因其深入的发展,其中的许多设计理念和产出,往往惠及了很多的民用领域,如复杂的涡轮增压技术是二战战斗机的标配,现在也经过简化,惠及到民用汽车领域。
而现在信息技术领域中白热化的竞争莫过于Intel和AMD之间的蓝红之争,其竞争让CPU的设计和架构经过千锤百炼,是一个现代人类设计和实践的结晶。因此我们探究一下CPU底层的实现,其中的思路和理念,特别是现在多核心CPU的设计,也会对我们的高性能系统,以及分布式系统有的设计和使用有很多借鉴和帮助。
另外其实人们也发现往往一些带有分形的东西,其不仅广泛存在,而且也代表着很多我们未知的合理结构,如人们所说的黄金分割,宇宙及黑洞等,其也都和分形有关联,分形可以简单理解为不断深入的底层构成,和其上层构成有结构上的相似。因此我们探究底层的设计,也对我们上层系统的设计有一定的参考和指导作用。
CPU的缓存结构简介
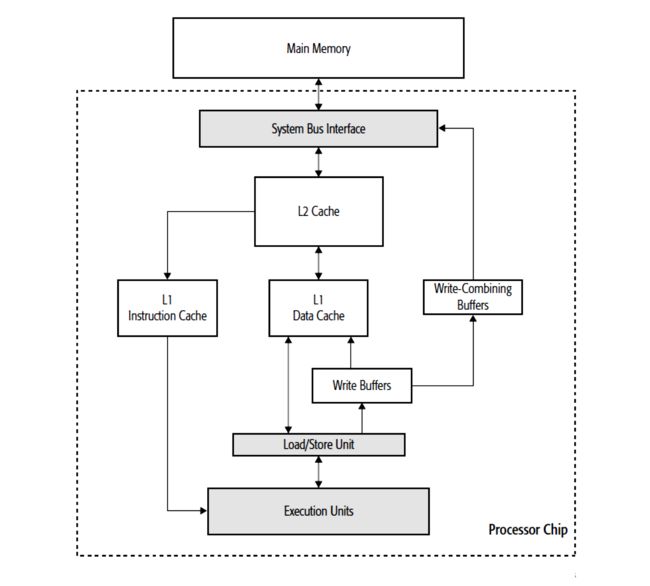
如下图所示是Intel的Skylake的CPU架构,我们可以看到缓存被分为L1、L2、L3这3层,CPU在运行中首先使用自己的寄存器,然后使用速度更快的L1缓存,其中:L1D缓存数据;L1I缓存指令;L1缓存和次快的L2同步数据;L2缓存和L3缓存同步数据(这里L2和L3按照内核数量做了等分,分给各个内核使用),我们可以简单地认为L3和内存同步数据。

为什么会有这么多级的缓存呢?因为每级缓存的速度差异很大,越快的缓存容量越小,因此CPU把缓存分成多级,每一级作为上一级的缓存。(其实在多核的情况下访问缓存会有一些同步问题,我们在下文讨论)
CPU的缓存性能参考
而我们可以认为目前CPU的缓存性能差异如表所示(参考了卡耐基梅隆大学在2014年的教案等)。

在上表中要注意以下内容:
1. L1、L2、L3的最小读写单位是64bit(8字节)。
2. L2的周期已包含L1(miss)的周期,L3的周期已包含L2(miss)的周期。
3. 内存访问应该还有TLB(虚拟地址页表缓存)的miss的情况,会增加少量周期。
4. 其实CPU的寄存器的整体大小为2KB左右,在64位下除了RAX、RBX、RCX、RDX、RSI、RDI、RSP、RBP、R8-R15这16个通用寄存器,如Intel还大概有:MMX:80bit X 8,ZMM(YMM,XMM):512bit X 32等寄存器,还有控制:64bit X 16,调试:64bit X 16,以及其他零散分类下及系统自用的若干。
因为这些缓存和内存在性能上的差异,所以对CPU的密集运算则是越少访问内存越好,比如在发生一次CAS操作时,如果这个内存访问能命中L2缓存,则还是比较高效的;但是如果L2 miss 连同 L3 miss ,则会变成一次读内存的重操作,影响并发的性能(约100ns的耗时),同理,对于正常的锁的操作,缓存miss时会耗时较多(约200ns的耗时)。
当前CPU的架构图
下面是Intel的Skylake 的架构图,与Sandy Bridge 的架构图,和AMD的ZEN 的架构图。
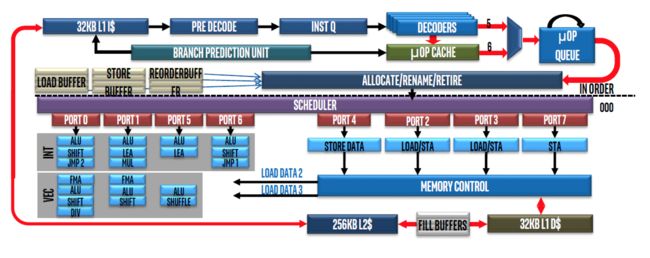
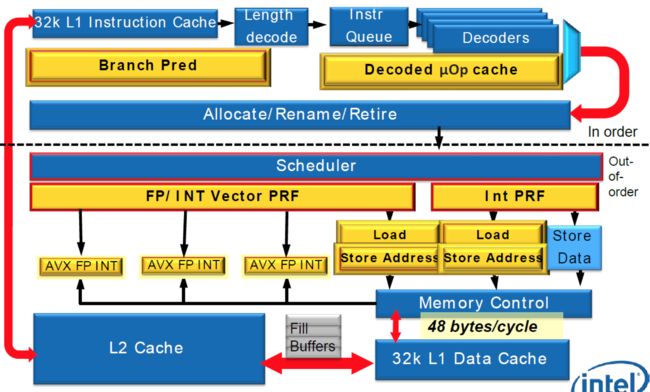
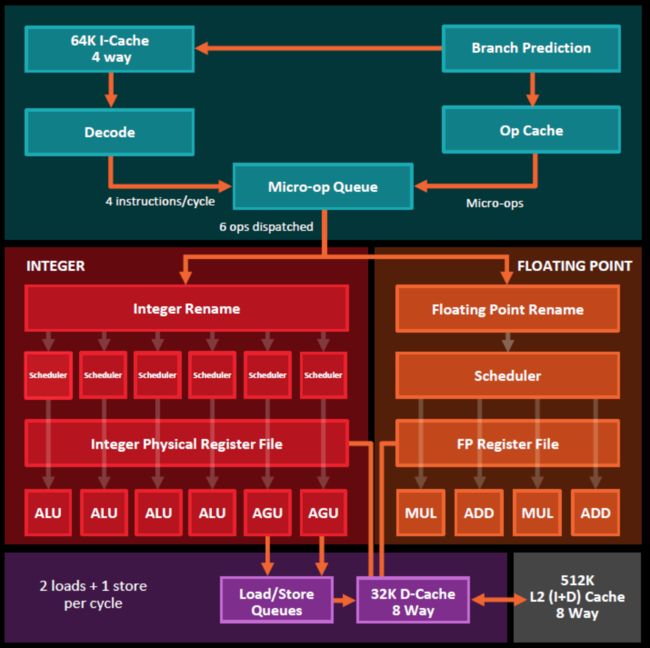
Intel和AMD的CPU的架构图虽然看着差异挺大,但它们的大结构其实是一样的,大概都分为3个模块。
1. 前端执行(front end):对应Intel图的上面及对应AMD图上面;这个是L1指令cache处理指令解码(DECODE),分支预测,执行队列,调度器,等这些指令功能。
2. 计算:对应INTEL图的左下及对应AMD图的中间;这个就是整数计算单元和浮点计算单元。
3. 缓存/内存:对应INTEL图的右下及对应AMD图的下面;这个就是内存控制器(内存读写控制器及队列,以及TLB(内存页表的虚拟地址转换缓存))及L1数据缓存和L2缓存。
从这些图上我们可以看出,L1命令缓存AMD的Zen是64KB,而Intel是32KB;L2缓存AMD的Zen是512KB,Intel是256KB,这个和CPU型号也有关系,但还是说明同一代下AMD的CPU在一些配置上更优一些。
这里也说下,网上流传说,在AMD的Zen之前Intel的CPU的强大的浮点功能(以及除法器),是Intel在跑分上胜利的其中一个重要因素,AMD认为都有显卡了,显卡浮点计算的能力非常强大,因此CPU不需要太强的浮点功能了……。
再有我们在看AMD的PPT时会发现,除了L1数据缓存到寄存器堆(register
file)还有个AGU到load/store queues模块的箭头,这里可能感觉比较奇怪,其实这个AGU的组件AMD和Intel都有,Intel的没有画出(之前的架构PPT里有,现在应该属于Load Store Data这,但没有画出),这个全称是Address Generation Unit,用来加速计算实际的物理地址,以及计算数组中的地址等。(另外,其实大家知道应用程序中的内存地址对CPU和操作系统来讲都是比较麻烦的虚拟地址)。下图是AMD的缓存/内存单元单元的一个展开图(图中L1数据缓存上的To Ex是到整数计算单元,To Fp是到浮点计算单元)。如图

CPU缓存的使用
上面介绍了CPU整体的架构图,以及缓存在CPU架构图中的位置,这里先介绍下CPU在单核环境下的多级缓存的架构。
现在CPU都流行多核芯的架构,而我们先看其中的一个核心对缓存操作的流程,我们可以整体认为:当核心(Core)访问(读或写)L1缓存时没有命中(miss)则访问L2缓存和L3缓存,在L3缓存也没有命中时才操作内存。多级缓存在独占(exclusive)模式下,L1缓存中通过LRU策略逐出的数据会到L2,在L2中逐出的会到L3,在L3中逐出的有写入/修改的数据则同步到内存。
缓存的操作的最小单元我们可以叫缓存单元,英文是cache line,每个缓存单元缓存64bit(8Byte)的数据,访问缓存时通过内存单元的物理地址。另外我们常看到8WAY,16WAY这种来描述缓存,其实缓存的在使用时是个类似二维数组的形式,这里的列就是WAY,如8WAY,就是8列。访问时通过物理地址的高位和中位从列(WAY)和行(SET)中命中一个缓存单元(cache line,也可以翻译成缓存行),可参考下图示意。
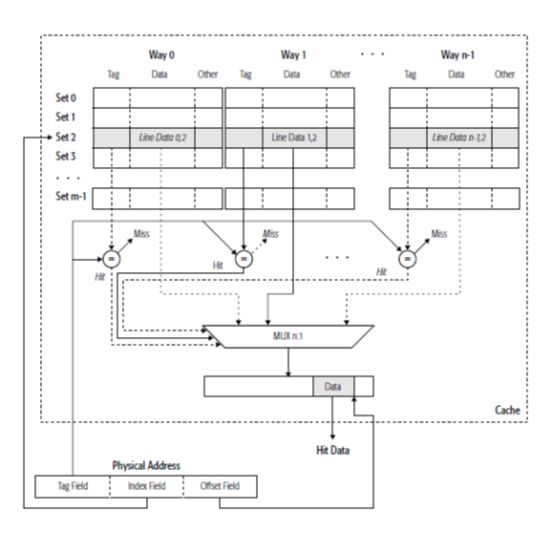
缓存单元因其一次必须操作连续的8Byte的数据,但是我们不希望类似下面这样的情况,如两个相邻的整型(4Byte)数据会同时被多个CPU核心进行频繁修改,而其都在一个缓存单元内,其每次修改都会触发我们后面讲的核心的缓存到内存的同步问题。
我们先看看具体读写命中和未命中的情况:
1. 缓存没有命中的情况:
a). 对于单核心的读,读操作会先检查缓存,在缓存中没有数据时会载入数据到缓存(cache line fill)中。
b). 对于单核心的写,其同读操作,会先检查缓存,在缓存中没有数据时会载入数据到缓存中,然后执行写操作,这里写操作只是简单的写了载入过来的缓存,并不同步到内存(这里需要注意,按照Intel的开发文档,老的Pentium默认的情况是在缓存miss后写操作直接写内存,而不是载入数据到缓存后写缓存)。
2. 缓存命中的情况:
a). 如果读命中(cache hit),则直接使用数据;
b). 如果这里是写操命(write hit)时则也是直接操作缓存,而不主动同步到内存。
我们也看看CPU的缓存的使用流程:
1. CPU的前端解析L1命令缓存中的指令进行预测和乱序执行等
2. 通过这些指令,计算单元具体处理从L1数据缓存到寄存器中的数据的计算
3. 将计算的结果更新到L1数据缓存,若要同步缓存中的数据到内存,则通过硬件实现的写缓存逻辑(write buffers)可靠地异步刷新数据到系统总线及内存(可理解为通过一个消息队列写)。
这里可以看参考下图所示。
这里则是整个单核心的的流程,我们注意到,CPU通过缓存提高性能的一个关键要点是在写的情况下只写缓存,不同步缓存数据到内存。
当前版本的多核共享缓存的MESI协议
而当上文所说在多核心时访问缓存的时候,就会存在数据不同步的问题:
这里有一个在多核环境下的典型场景:某个核心Core1把数据A从0改成1,Core1把数据A存在自己的L1缓存中,这时刚好Core2的L1缓存也缓存了数据A,但其值仍然为0,若这时Core2对数据A进行操作,就是操作了过期的数据A,如表1-3所示。

为了解决这一问题,人们提出了MESI协议,它是一种缓存一致性协议(cache cohere protocol),把缓存单元(cache line)的状态分为:修改过(M,Modified)、独占(E,Exclusive)、共享(S,Shared)、无效(I,Invalid),并通过这些状态来控制数据的写和同步。
MESI协议是处理器设计时内部支持的,通过标志位及版本号来标记缓存单元(cache line),如在Intel在2017年的手册中MESI的状态表中描述的,每个缓存单元(64bit)各自维护两个flag的标记位来记录MESI的协议等的状态信息,而其关系如表下所示,表中的“去系统总线”的意思是开始异步写内存数据。


MESI协议的状态转换
我们把MESI协议的变换关系总结为表:

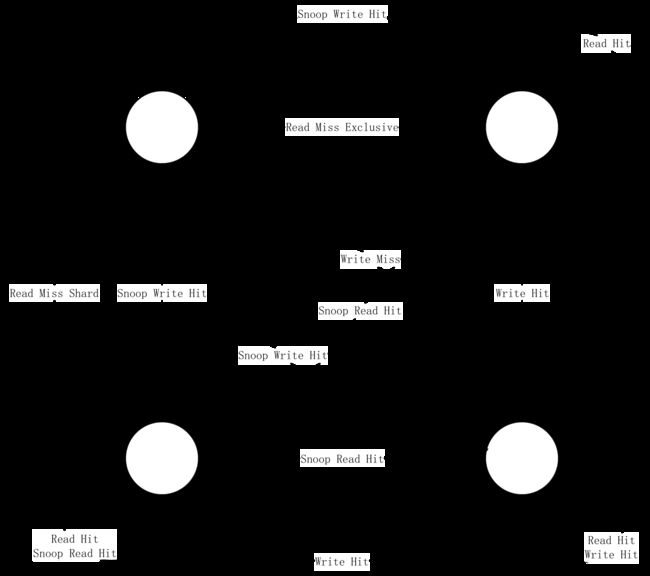
为了更清晰描述,我们在下面画出整体的状态图,描述M E S I 之间的转换关系,主要关注状态的变更。
我们可以认为MESI协议的文字描述如下:
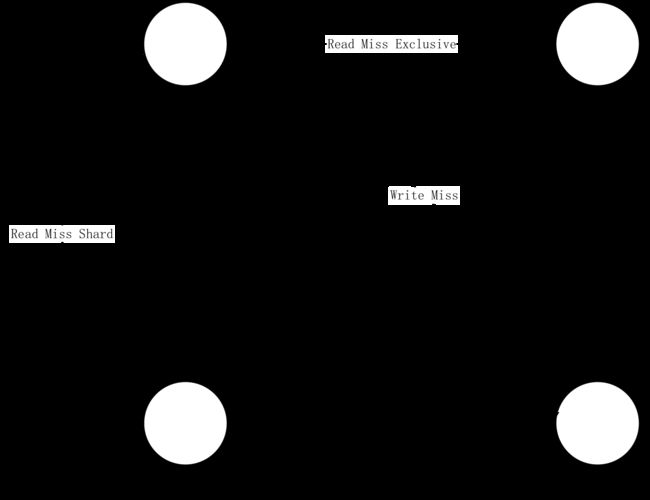
状态从Invalid开始,Read Miss 变成 Exclusive ,Write Miss 变成Modified,当其它核心有数据时Read Miss 变成 Shared。
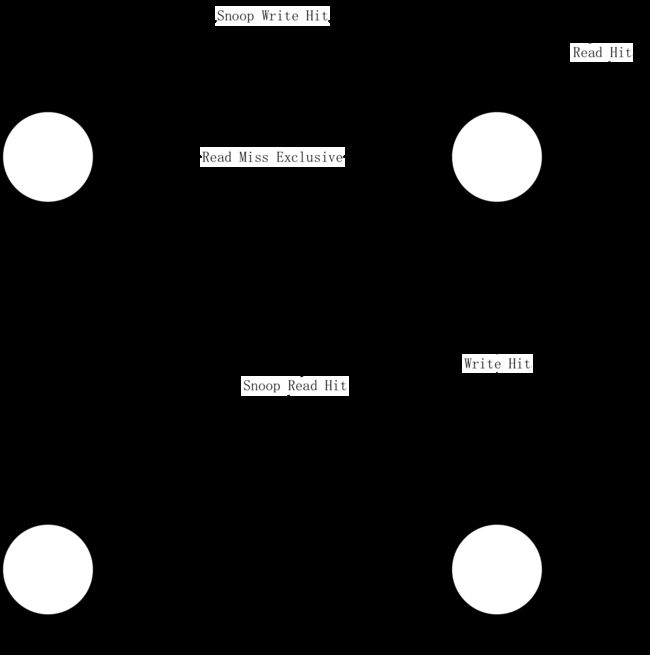
在Exclusive下的读缓存,不会改变状态,写缓存会使自身状态变为Modified,当侦测到其它核心上的当前缓存的地址的读操作,状态会变成Shared,侦测到其它核心上的当前缓存的地址的写操作,状态会变成Invalid。
在Modified下的读缓存,不会改变状态,当侦测到其它核心上的当前缓存的地址的读操作,状态会变成Shared,侦测到其它核心上的当前缓存的地址的写操作,状态会变成Invalid。
在Shared下的读缓存,不会改变状态,写缓存会使自身状态变为Modified,当侦测到其它核心上的当前缓存的地址的读操作,不会改变状态,侦测到其它核心上的当前缓存的地址的写操作,状态会变成Invalid。



MESI协议的举例
看了上面的流程图后,我们再从一个例子来看看MESI协议的实际操作,以Modified这个状态为例,现在多核心CPU的实现是:当一个核心对一个缓存单元的数据进行修改,使状态变为Modified,这时当其他核心也要操作此缓存单元对应的数据地址时,当前核心会向打算使用此数据的核心发送信号,通知其改变缓存单元的状态,并且会触发一次异步的内存回写,同时把修改过的数据直接传送给要操作此数据的核心。这时如果对方是读操作,则自己的状态变为Shared,对方的状态是Shared;如果对方是写操作,则自己的状态变为Invalid,对方的状态是Modified。如下两表。


而如果当前核心的一个缓存单元的状态是S,则在侦测到其他核心写缓存单元对应的数据时,会使此缓存单元的状态变为I;如果当前核心要再次操作之前缓存单元映射的内存地址的数据,则会再次执行另一次缓存载入的操作。如下两表。


MESI协议的其它讨论
但是AMD的实现细节和INTEL略有不同,如下图所示是AMD的MOESI的一个状态变更图(2013的文档),它和Intel一样,也是通过侦测其他核心对内存的操作倾向来更新缓存单元的状态,并通知其他核心。这里AMD多加了个Owner的状态,该状态是Modified的升级,唯一不同的是允许在其他核心中有Shared状态,而Modified是独占状态(不允许其它核心有Shared的状态)。

另外看一些之前的文档表示Intel根据MESI拓展出了MESIF协议,增加了一个Share的中间状态F(Forward),表示在此状态时数据可以再被传给其他核心,但现在Intel文档中只有MESI了,应该是已经不再使用了。
CPU对内存的分类
其实处理器还对内存进行了策略分类,上面介绍的是在默认的内存类型下的情况(Write Back),如上所述的MESI协议结合这个内存类型后,基本可以解决CPU使用的绝大部分场景。
但是CPU在某些使用场景下,对缓存和内存的一致性有不同程度的强需求,因此,CPU厂商针对CPU的使用场景设计了不同的内存类型,比如从不使用缓存,到只有读使用缓存,再到读写都使用缓存(Write Back)等各种类型。
这些类型对我们参看分布式系统中遇到的问题,应该还是有很多借鉴意义的,而且有这些内存类型的缓存才是完整的一个缓存系统,所有也希望大家能了解一下这些,下面按Intel的文档列出分类:
1. UC:Strong Uncacheable不可缓存,不可预测读(speculative read),分类位UC的内存读写都不会被缓存,这里主要对应有内存映射的IO设备的内存
a). AMD对应的名称:Uncacheable (UC)
2. UC-:Uncacheable,不可缓存,不可预测读,同UC ,不过类型被可变为WC
a). AMD名称:近似Cache Disable (CD)
3. WC:Write Combining,不可缓存,可预测读,同UC-,但就是可以缓存多个写请求后批量提交。
a). 在AMD对应的名称:同名,同时对应AMD的Uncacheable (UC)
b). 在AMD还有一个WC+ Write Combining plus的类型,这个对应AMD的CacheDisable (CD)
4. WT :Write-through 读操作可缓存,可预测读,可缓存多个写请求后批量提交。但是写缓存miss时或缓存单元状态位无效时不刷新写缓存,直接写内存;若写操作能命中缓存时,在写缓存的同时也写内存(through to)。
a). 在AMD对应的名称:同名
5. WB :Write-back默认模式,读写操作可缓存,可预测读,可缓存多个写请求后批量提交。写操作写缓存后不主动提交到内存,当回写操作发生时(write back)才把数据写回内存。回写操作发生的条件是缓存满后新分配内存,写旧的缓存单元到内存,或MESI在同步数据时。
这个模式适用于绝大多数的系统和应用程序。
a). 在AMD对应的名称:同名
6. WP :Write protected读操作可缓存,可预测读。但是写操作直接写内存(propagated to),同时使所有核心的缓存单元变成失效状态。
a). 在AMD对应的名称:同名
对于这些类型,我们可以参考下面表格来对比他们的相同和不同。


这里AMD文档上的一些技术细节和Intel不完全一样,不过比较这两个的区别现在不是本文重点,就不详细罗列了。
处理器的MESI协议加上这些内存类型,就可以按照人们流行的2/8原则解决缓存问题了:80%的情况由默认内存类型解决,虽说这个20%也不简单,而20%的情况由定义的另外80%的内存类型解决。
简单引申到系统的缓存架构及讨论
上面主要描述了CPU的缓存架构,CPU需要通过定义内存类型,以及一致性协议来解决其遇到的多核心下的性能和一致性等问题。
其实解决多个核心间的协同工作,这一点也和我们在系统缓存架构上要面对的一些问题相似,如缓存架构的高并发,高可用,可伸缩等这些。
我们认为,CPU的寄存器和CPU周期同步其实也可以理解为是运算单元一部分,而L1缓存,则可认为是分布式节点中的本地内存,L2和L3缓存则可以认为是共用的Redis这样的通用缓存,内存则可以认为是数据库与Elasticsearch这些真正的数据源。如表.

参照CPU的设计思路,其实系统上最理想的状态是:我们也大量使用分布式节点的内存做缓存,或更多依赖本地的内存进行一些计算,但是这里也有一些问题和挑战:
第一个就是持久性问题,如果使用缓存的话,如何解决数据的持久性问题,这个一般需要直接访问持久化层,如数据库,或消息队列,它们返回成功就认为成功。但在一些高性能要求的环境下,也可以通过主从强一致协议来完成,就是写事务由主开始,主发送事务给从,所有的从都返回收到数据给主,然后主返回成功,而在这个过程中都是内存操作,所有的主从通过异步写数据来保证同步,如下图。

再一个就是同CPU多核间的脏数据问题,这个可以仍然把缓存分成不同大小的缓存块,然后也参考MESI协议给每个缓存的数据体包装一层,标记一个状态位,以及版本号,思路还是多利用Client的内存进行计算,使用外部的内存进行同步。

而缓存的高并发需求,也可以看作纯网络I/O的问题。我们曾经做过测试,MySQL可以在命中内存索引的情况下达到10万每秒的QPS,而Redis大致也是同样的表现。
其它的一些提升性能的办法如在Scaling Memcache at
Facebook的论文中提到:对所有缓存的依赖进行分析,然后把所有没有依赖关系的缓存访问变成并行执行,把有依赖关系的保留串行执行。比如要获取一个商品的信息,同时获取商品的类目、城市、门店、优惠卷等信息,对这些缓存信息可以进行并行访问,而由于商品的类型不同,可能具体的字段也不同,所以只能串行获得商品的类型,这样可递归生成一个缓存的查询树,根据这个查询树来访问缓存。如图。
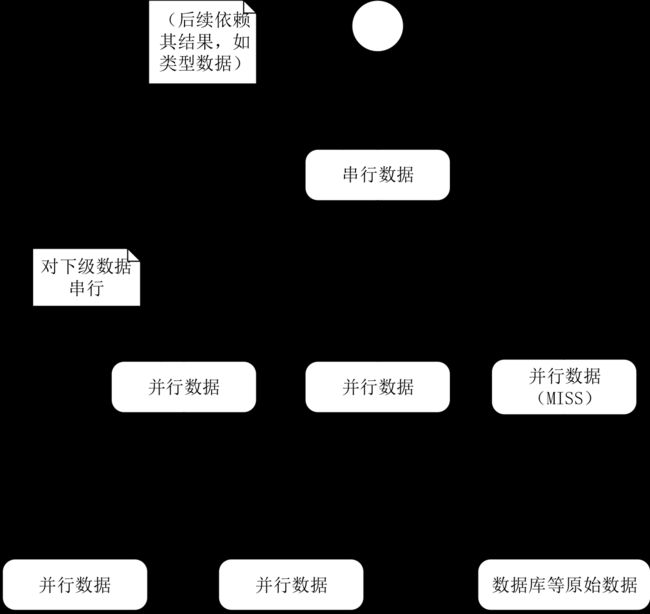
缓存做可伸缩方案时需要修改其分片策略,比如Hash从mod 5变为mod 10时需要一个对应的策略,有些类似于Redis的Hash扩容,不过变成了在分布式环境下扩容,步骤如下。
(1)先分配mod10的主片和从片的空间。
(2)标记当前的数据版本号,开始双写,同时写旧的主片和新的主片。
(3)从标记的数据版本号向前异步地迁移数据。
(4)在数据迁移完成,切换读到新的片,随后关闭旧片的写入。
(5)迁移完成,可以删除旧片。
在扩容时同样可以参照REIDS集群,预置缓存槽,然后分配缓存槽给对应的实例。但是一致性Hash认为存在一些问题,比如会出现热点,又如大量的访问只在其中一部分Hash段上出现。现在,Redis的集群用配置缓存槽可以解决这些问题。
另外,Facebook的一个模型是通过MySQL的数据复制同步两个大的数据中心,并同时维护两个本地的缓存池的
对于更新缓存数据,Facebook也提出一个很好的缓存模式,比如上面提到的MySQL等主流数据工具的事务成功都不是实际的数据持久化成功,而是在写日志成功时就认为是事务成功。所以,我们也可以根据MySQL的事务日志来更新缓存的信息,这样可以更好地解决缓存失效的问题。
这里我们抛砖引玉一的讨论了一下缓存系统的架构设计,也希望介绍的CPU的缓存的架构的这些内容能对大家在设计和使用缓存中有所帮助,后续我们也希望有机会做出我们新的缓存中间件。