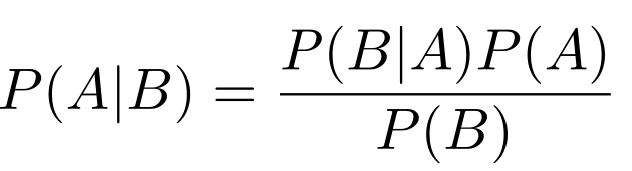
「朴素贝叶斯」
具体理论就不详细讲解了,网上一搜一大把。其核心思想就是: 朴素贝叶斯 = 条件独立假设 + 贝叶斯方法。运行速度快,在满足分布独立这一假设条件下分类效果好,但对于训练集中没有出现过的词语要平滑处理,数值型变量特征默认符合正态分布。
「Python实现」
导入停用词
导入停用词库,同时使用strip()方法剔除不需要的空白符,包括('\n', '\r', '\t', ' ')
def make_word_set(words_file):
words_set = set()
with codecs.open(words_file,'r','utf-8') as fp:
for line in fp:
word = line.strip()
if len(word) > 0 and word not in words_set:
words_set.add(word)
return words_set
文本处理,样本生成
每个新闻文本txt文件在各自所属类别的文件夹中,结构如下:
"folder_path"
|
|-- C000008 -- 1.txt / 2.txt / ... / 19.txt
|-- C000010
|-- C000013
|-- ...
|-- C000024
这里使用os.listdir()读取指定目录下的所有文件夹名(即分类类别),遍历各自文件夹(类别)内的文本文件,对每一个txt文件进行文本切词,同时利用zip()函数使每个新闻文本与所属类别一一对应,一共有90条数据。
为了随机抽取训练与测试数据集,用random.shuffle()打乱顺序,并选取20%的数据用于测试,同时把特征数据与类别数据各自分开。
最后对训练数据集中的词语进行词频统计。这里有使用sorted()函数进行排序,方法为sorted(iterable, cmp = None, key = None, reverse = False),其中参数含义如下:
- iterable:是可迭代类型(我这里的可迭代类型为字典)
- cmp:用于比较的函数,比较什么由key决定(这里没用到)
- key:用列表元素的某个属性或函数进行作为关键字(这里使用字典中的“值”大小作为关键字排序)
- reverse:排序规则,True为降序(False为升序)
def text_processing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path)
data_list = []
class_list = []
# 遍历文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path,folder)
files = os.listdir(new_folder_path)
j = 1
for file in files:
if j > 100: # 防止内存爆掉
break
with codecs.open(os.path.join(new_folder_path, file), 'r', 'utf-8') as fp:
raw = fp.read()
word_cut = jieba.cut(raw, cut_all = False)
word_list = list(word_cut)
data_list.append(word_list) # 训练集
class_list.append(folder) # 类别
j += 1
# 划分训练集和测试集
data_class_list = list(zip(data_list, class_list))
random.shuffle(data_class_list) # 打乱顺序
index = int(len(data_class_list) * test_size) + 1 # 抽取测试数据集的占比
train_list = data_class_list[index:]
test_list = data_class_list[:index]
train_data_list,train_class_list = zip(*train_list) # 特征与标签
test_data_list,test_class_list = zip(*test_list)
# 统计词频
all_words_dict = {}
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict:
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
# 降序排序(key函数)
all_words_tuple_list = sorted(all_words_dict.items(),key = lambda f:f[1], reverse = True)
all_words_list = list(zip(*all_words_tuple_list))[0]
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
特征选择
这里我们仅选取词频坐高的1000个特征词(维度),并剔除数字与停用词。
def words_dict(all_words_list,deleteN,stopwords_set=set()):
feature_words = []
n = 1
for t in range(deleteN,len(all_words_list),1):
if n > 1000: # 最多取1000个维度
break
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
用选取的特征词构建0-1矩阵
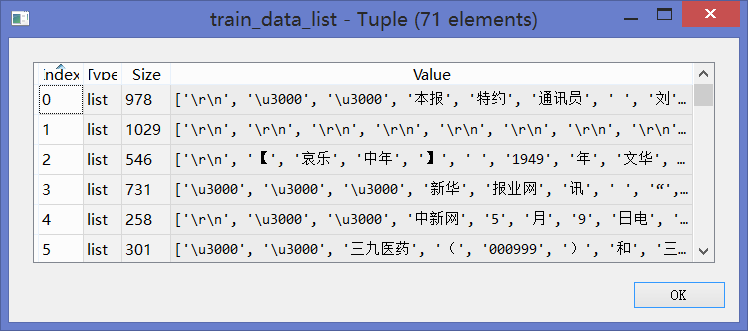
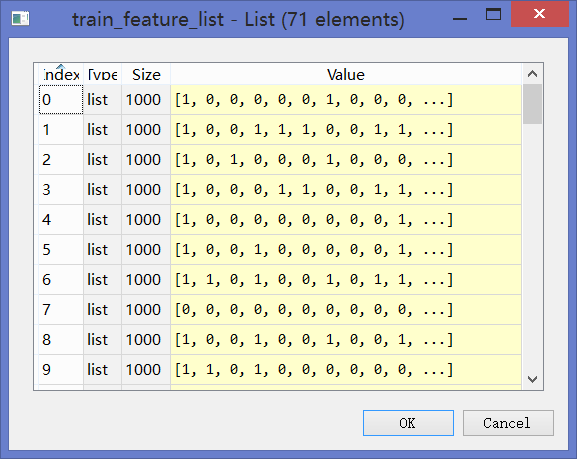
对训练数据集train_data_list中每篇切完词之后的文档构建特征向量(由上述1000个特征词组成),若出现则取值为1,否则为0。于是90篇文章构建出了[90,1000]维度的0-1矩阵(其中71行为训练数据,19行为测试数据)。
训练集如下:
0-1矩阵如下:
def text_features(train_data_list, test_data_list, feature_words):
def text_features(text,feature_words):
# text = train_data_list[0]
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
# 0,1的矩阵(1000列-维度)
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list,test_feature_list
朴素贝叶斯分类器
这里使用开源sklearn库中的朴素贝叶斯分类器,输入参数分别为训练集的0-1特征矩阵(train_feature_list)与训练集分类(train_class_list),然后对测试数据的输出与真实结果进行比较,得到准确度为0.68
def text_classifier(train_feature_list,test_feature_list,train_class_list,test_class_list):
# sklearn多项式分类器
classifier = MultinomialNB().fit(train_feature_list,train_class_list) # 特征向量与类别
test_accuracy = classifier.score(test_feature_list,test_class_list)
return test_accuracy
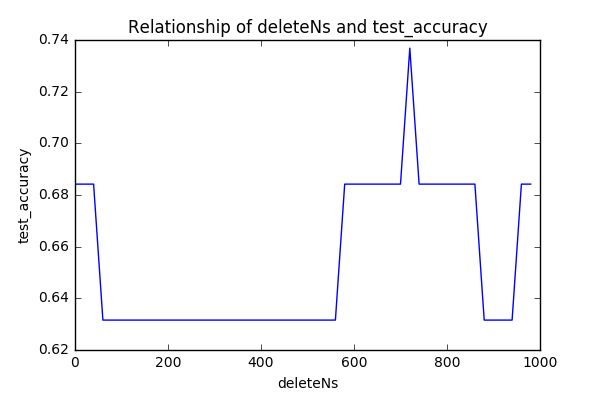
这里我们仅选取词频最高的1000个作为特征向量,不妨尝试下选取其他的关键字作为特征向量,发现准确率都在0.63以上,分类效果还算可以,见下图:
if __name__ == '__main__':
# 文本预处理(分词、划分训练与测试集、排序)
folder_path = '...'
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = text_processing(folder_path, test_size = 0.2)
# stopwords_set
stopwords_file = '...'
stopwords_set = make_word_set(stopwords_file)
# 特征提取与分类
deleteNs = range(0,1000,20)
test_accuracy_list = []
for deleteN in deleteNs:
# 选取1000个特征
feature_words = words_dict(all_words_list,deleteN,stopwords_set)
# 计算特征向量
train_feature_list, test_feature_list = text_features(train_data_list,test_data_list,feature_words)
# sklearn分类器计算准确度
test_accuracy = text_classifier(train_feature_list,test_feature_list,train_class_list,test_class_list)
# 不同特征向量下的准确度
test_accuracy_list.append(test_accuracy)
print(test_accuracy_list)
# 结果评价
plt.figure()
plt.plot(deleteNs,test_accuracy_list)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteNs')
plt.ylabel('test_accuracy')
plt.savefig('result.png',dpi = 100)
plt.show()
参考资料
用朴素贝叶斯进行文本分类
朴素贝叶斯分类器的应用