Logstash的入门与运行机制
Logstash介绍
- 数据收集处理引擎
- ETL工具
目录结构
Logstash Directory Layout
架构简介
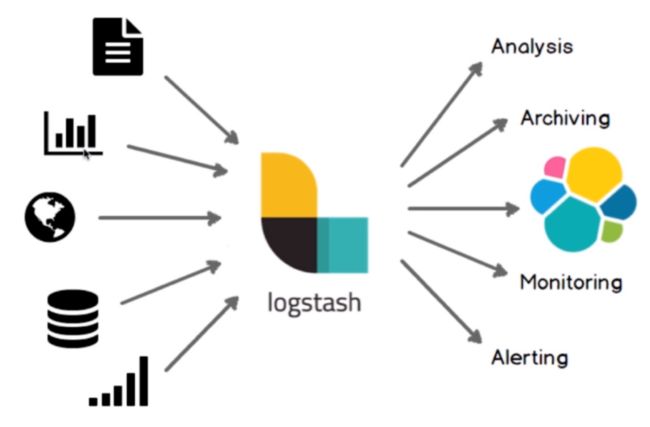



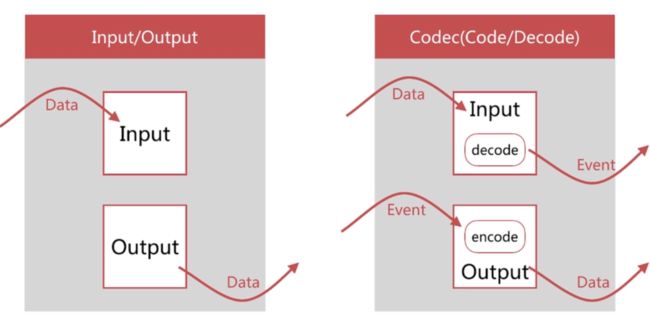




事件的声明周期

- 数据输入到Input 中(可以有多个Input)
- Input中的Codec 将输入数据转换为 Event
- Event 存储到 Queue 队列中
- 每一个 Batcher->Filter->Output 都占有1个工作线程
- Batcher 从 Queue 队列中获取 Event,当 Batcher 中的Event数量达到阈值或者达到等待时长后,Batcher会将Event发送到Filter中处理
- Filter处理完Event后,将Event传到Output中,Output中Codec将Event转换为输出数据输出
- Output输出后通知Queue ACK for persistence,Queue将标记已完成的Event(在持久化队列Persistent Queue中将用到ACK)
Queue 的分类
- In Memory
- 无法处理进程Crash、机器宕机等情况,会导致数据丢失
- Persistent Queues In Disk
- 可处理进程 Crash 等情况,保证数据不丢失
- 保证数据至少消费一次
- 充当缓冲区,可以替代 Kafka 等消息队列的作用
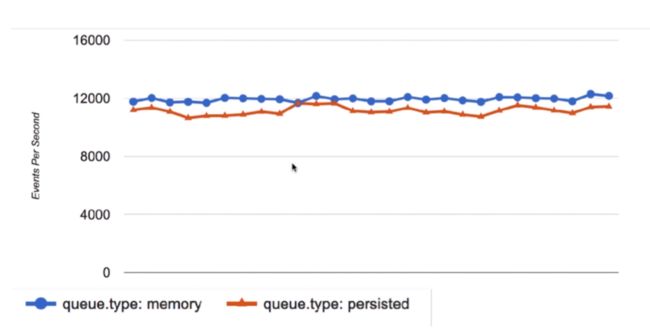
性能对比
Persistent Queues
基本配置
- queue.type:persisted
- 队列类型,默认是 memory
- queue.max_bytes:4gb
- 队列存储最大数据量
工作流程

红1. 数据从Input输入,转换为Event后提交到PQ(Persistent Queue)中
红2. PQ将数据备份到磁盘Disk中
红3. Disk备份成功
红4. PQ返回EventResponse给Input,告诉Input数据已经收到(需要Input支持EventResponse机制,支持这种机制Input可以感知Logstash的处理能力,即背压机制,FileBeat支持该机制,FileBeat如果没有收到logstash的EventResponse,则会减少输入,缓解Logstash的压力)
蓝1. Event被Fileter和Output处理
蓝2. Output处理完发送ACK通知PQ处理完毕该Event
蓝3. PQ从磁盘中删除该Event记录
线程简介

- pipeline.workers | -w(命令行参数)
- pipeline workder thread 线程数,即filter_output的处理线程数,默认是cpu核数
- pipeline.batch.size | -b(命令行参数)
- Batcher 一次批量获取的待处理文档数,默认125,可以根据输出进行调整,越大会占用越多的 heap 空间,可以通过 jvm.options 调整 heap 大小,避免频繁gc
- pipeline.batch.delay | -u(命令行参数)
- Batcher 等待的时长,默认50ms,单位为ms
配置简介
- logstash 设置相关的配置文件(在conf文件夹中,setting files)
- logstash.yml logstash相关的配置,比如node.name、path.data、pipeline.workers、queue.type等,这其中的配置可以被命令行参数中的相关参数覆盖
- jvm.options 修改jvm的相关参数,比如修改heap size等
- pipeline配置文件
- 定义数据处理流程的文件,以 .conf 结尾
配置文件配置项 logstash.yml
- node.name
- 节点名,便于识别
- path.data
- 持久化存储数据的文件夹,默认是logstash home目录下的data
- path.config
- 设定pipeline配置文件的目录
- path.log
- 设定pipeline日志文件的目录
命令行配置项 Running Logstash from the Command Line
-
--node.name NAME指定此Logstash实例的名称。如果没有给出值,则默认为当前主机名。 -
f, --path.config CONFIG_PATH指定pipeline的配置路径,可以是文件或者文件夹 -
--path.settings SETTINGS_DIRlogstash的配置文件夹路径,其中要包含 logstash.yml -
-e, --config.string CONFIG_STRING使用给定的字符串作为 pipeline内容,多用于测试使用 -
-w, --pipeline.workers COUNT指定pipeline工作线程数,默认为CPU核数 -
-b, --pipeline.batch.size SIZE指定batcher收集事件的最大数 -
--path.data PATH这应该指向一个可写目录。 Logstash将在需要存储数据时使用此目录。插件也可以访问此路径。默认值是Logstash home下的数据目录。 -
--config.debug日志显示调试信息 -
-t, --config.test_and_exit检查pipeline的配置语法是否正确并退出 -
-r, --config.reload.automatic监视pipelline配置改动并在配置更改时重新加载配置。
logstash 配置方式建议
- 线上环境推荐采用配置文件的方式来设定logstash的相关配置,这样可以减少犯错的机会,而且文件便于进行版本化管理
- 命令行形式多用来进行快速的配置测试、验证、检查等
logstash 多实例运行方式
- bin/logstash --path.settings instance1
- bin/logstash --path.settings instance2
- 不同 instance 中修改 logstash.yml,自定义 path.data,确保其不相同即可
pipeline 配置 Configuring Logstash
整体结构
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}
值类型
布尔类型
布尔值必须为true或false。请注意,true和false关键字不包含在引号中。
例如:
ssl_enable => true
数值类型
数字必须是有效的数值(浮点或整数)。
例如:
port => 33
字符串类型
字符串必须是一个字符序列。请注意,字符串值用单引号或双引号括起来。
默认情况下,不启用转义序列。如果您希望在带引号的字符串中使用转义序列,则需要在logstash.yml中设置config.support_escapes:true。如果为true,则引用的字符串(double和single)将具有转义字符转换功能:
| Text | Result |
|---|---|
\r |
carriage return (ASCII 13) |
\n |
new line (ASCII 10) |
\t |
tab (ASCII 9) |
\\ |
backslash (ASCII 92) |
\" |
double quote (ASCII 34) |
\' |
single quote (ASCII 39) |
例如:
name => "Hello world"
name => 'It\'s a beautiful day'
数组类型 Array/Lists
users => [ {id => 1, name => bob}, {id => 2, name => jane} ]
path => [ "/var/log/messages", "/var/log/*.log" ]
uris => [ "http://elastic.co", "http://example.net" ]
哈希类型 Hash
match => {
"field1" => "value1"
"field2" => "value2"
...
}
# or as a single line. No commas between entries:
match => { "field1" => "value1" "field2" => "value2" }
注释
注释与perl,ruby和python中的注释相同。注释以#字符开头,不需要位于一行的开头。
例如:
# this is a comment
input { # comments can appear at the end of a line, too
# ...
}
配置中访问Event的数据与字段 Accessing Event Data and Fields in the Configuration
字段直接引用

在字符串中以sprintf方式引用

条件表达式
- 比较:==、!=、<、>、<=、>=
- 正则是否匹配:=、!
- 包含(字符串或者数组):in、notin
- 布尔操作符:and、or、nand、xor、!
- 分组操作符:()
if [foo] in [foobar] {
mutate { add_tag => "field in field" }
}
if [foo] in "foo" {
mutate { add_tag => "field in string" }
}
if "hello" in [greeting] {
mutate { add_tag => "string in field" }
}
if [foo] in ["hello", "world", "foo"] {
mutate { add_tag => "field in list" }
}
if [missing] in [alsomissing] {
mutate { add_tag => "shouldnotexist" }
}
if !("foo" in ["hello", "world"]) {
mutate { add_tag => "shouldexist" }
}
插件详解
Input plugins
input 插件指定数据输入源,一个pipeline可以有多个input插件,我们主要讲解下面的几个input插件:
- stdin
- file
- kafka
stdin
最简单的输入,从标准输入读取数据,通用配置为:
- codec 类型为 codec
- type 类型为 string,自定义该事件的类型,可用于后续判断
- tags 类型为 array,自定义该事件的 tag,可用于后续判断
- add_field 类型为 hash,为该事件添加字段

file
从文件读取数据,如常见的日志文件。文件读取通常要解决几个问题:
- 文件内容如何只被读取一次?即重启LS时,从上次读取的位置继续
- sincedb
- 如何即时读取到文件的新内容?
- 定时检查文件是否有更新
- 如何发现新文件并进行读取?
- 可以,定时检查新文件
- 如果文件发生了归档(rotation)操作,是否影响当前的内容读取?
- 不影响,被归档的文件内容可以继续被读取

常用配置:
- path类型为数组,指明读取的文件路径,基于
glob 匹配语法- path => ["/var/log/*/log","/var/log/message"]
- exclue类型为数组排除不想监听的文件规则,基于
glob 匹配语法- exclude => "*.gz"
- sincedb_path 类型为字符串,记录 sincedb 文件路径
- start_postion 类型为字符串,值为one of ["beginning", "end"],是否从头读取文件
- stat_interval 类型为数值,单位秒,定时检查文件是否有更新,默认1秒
- discover_interval 类型为数值,单位秒,定时检查是否有新文件待读取,默认15秒
- ignore_older 类型为数值,单位秒,扫描文件列表时,如果该文件上次更改时间超过设定的时长,则不做处理,但依然会监控是否有新内容,默认关闭
- close_older 类型为数值,单位秒,如果监听的文件在超过该设定时间内没有新内容,会被关闭文件句柄,释放资源,但依然会监控是否有新内容,默认 3600秒,即1个小时

glob 匹配语法
glob匹配最初是unix系统命令行中用来匹配文件路径的,后面很多语言有了glob的实现。
主要包含如下几种匹配符:
-
*匹配任意字符,但不匹配以.开头的隐藏文件,匹配这类文件时要使用.*
来匹配 -
**递归匹配子目录 -
?匹配单一字符 -
||匹配多个字符,比如[a-z]、[^a-z] -
{}匹配多个单词,比如{foo,bar,hello} -
\转义符号

kafka

Codec plugins
Codec Plugin 作用于 input 和 output plugin,负责将数据在原始与 Logstash Event 之间转换,常见的 codec 有:
- plain 读取原始内容
- dots 将内容简化为点进行输出
- rubydebug 将 Logstash Events 按照 ruby 格式输出,方便调试
- line 处理带有换行符的内容
- json 处理 json 格式的内容
- multiline 处理多行数据的内容
plain
# plain 将 内容以原本形式处理,不做加工
bin/logstash -e "input{stdin{codec=>plain}}output{stdout{codec=>rubydebug}}"
rubydebug
# rubydebug 将 Logstash Events 按照ruby格式输出,方便调试
bin/logstash -e "input{stdin{codec=>line}}output{stdout{codec=>rubydebug}}"
dots
# dots 将内容简化为点进行输出,常用于压测时,不想查看详细输出,只要查看进度,每一个点代表一个事件
bin/logstash -e "input{stdin{codec=>line}}output{stdout{codec=>dots}}"
json
# json 处理json格式的内容
bin/logstash -e "input{stdin{codec=>json}}output{stdout{codec=>rubydebug}}"
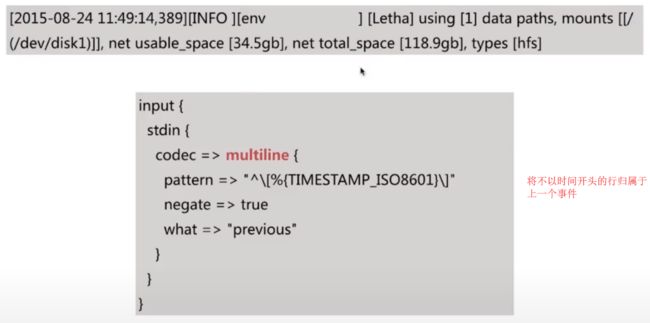
multiline
当一个Event的message由多行组成时,需要使用该codec,常见的情况是堆栈日志信息的处理,如下所示:
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book. java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
主要设置参数:
- pattern 设置行匹配的正则表达式,可以使用 grok
- what previous | next,如果匹配成功,那么匹配行是归属上一个事件还是下一个事件
- negate true or false 是否对 pattern 的结果取反


Filter plugins
Filter 是 Logstash 功能强大的主要原因,它可以对 Logstash Event 进行丰富的处理,比如解析数据、删除字段、类型转换等等,常见的有如下几个:
- date 日期解析
- grok 正则匹配解析
- mutate 对字段作处理,比如重命名、删除、替换等
- json 按照 json 解析字段内容到指定字段中
- geoip 增加地理位置数据
- ruby 利用 ruby 代码来动态修改 Logstash Event
date
将日期字符串解析为日期类型,然后替换 @timestamp 字段或者指定的其他字段
主要设置参数:
- match
- 类型为数组,用于指定日期匹配的格式,可以一次指定多种日期格式
- match => ["logdate","MMM dd yyyy HH:mm:ss","MMM d yyyy HH:mm:ss","ISO8601"]
- target
- 类型为字符串,用于指定赋值的字段名,默认是
@timestamp
- 类型为字符串,用于指定赋值的字段名,默认是
- timezone
- 类型为字符串,用于指定时区
- overwrite
- 覆盖字段值
- tag_on_failure
- 如果没有成功匹配,则将值附加到tag字段,默认是 _grokparsefailure,可以基于此做判断
grok
对下面的日志进行解析:


语法
- 基本格式:
%{SYNTAX:SEMANTIC}-
SYNTAX为grok pattern的名称,SEMANTIC为赋值字段名称
-
-
%{NUMBER:duration}可以匹配数值类型,但是 grok 匹配出的内容都是字符串类型,可以通过在最后指定为 int 或者 float 来强制转换类型。%{NUMBER:duration:float} - 熟悉常见的一些 Pattern 利于编写匹配规则
- https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
自定义匹配规则
当logstash中的grok插件没有需要的匹配模式时,可以使用以下方式解决
1. 使用Oniguruma语法定义捕获规则并赋值
例如,日志中有个 queue_id 为10或11个字符的十六进制值,可以像这样轻松捕获并将值赋给了queue_id:
(?[0-9A-F]{10,11})
2. pattern_definitions
pattern_definitions 参数,以键值对的方式定义pattern名称和内容

3. pattern_dir
pattern_dir 参数,将pattern定义在文件中,以文件形式读取 pattern
dissect
- 使用分隔符将非结构化事件数据提取到字段中
- 基于分割符原理解析数据,解决 grok 解析时消耗过多cpu资源的问题
- dissect 的应用有一定的局限性
- 主要适用于每行格式相似且分隔符明确简单的场景


语法
dissect语法比较简单,有一系列字段(field)和分隔符(delimiter)组成
- %{字段}
- %{}与%{}之间是分隔符
- %{+字段}
+表示在原有字段值后追加 - %{+字段/1} %{+字段/3} %{+字段/2}
/表示在字段值后按照升序顺序拼接 - %{?key1}=%{&key1}
%{?key1}代表忽略匹配值,但是赋予字段名key1,用于后续匹配用,%{&key1}代表将匹配值赋予key1的匹配值。例如匹配:a=1&b=2,输出{"a":"1","b":"2"},使用%{?key1}=%{&key1}&%(?key2}=%{&key2} - dissect 可以自动处理空的匹配值
- dissect 分割后的字段值都是字符串,可以使用 convert_datatype属性进行类型转换



mutate
使用最频繁的操作,可以对字段进行各种操作,比如重命名、删除、替换、更新等,主要操作如下:
- convert 类型转换
- gsub 字符串替换
- split/join/merge 字符串切割、数组合并为字符串、数组合并为数组
- rename 字段重命名
- update/replace 字段内容更新或替换
- remove_field 删除字段
convert
实现字段类型的转换,类型为 hash,仅支持转换为 integer、float、string 和 boolean
filter {
mutate {
convert => { "age" => "integer" }
}
}
gsub
对字段内容进行替换,类型为数组,每3项为一个替换配置
[
被转换的字段,被替代的内容,替代的内容,
被转换的字段,被替代的内容,替代的内容,
被转换的字段,被替代的内容,替代的内容
...
]
filter {
mutate {
gsub => [
"path","/","_",
"urlparams","[\\?#-]","."
]
}
}
split
将字符串切割为数组
filter {
mutate {
split => { "jobs" => "," }
}
}
join
将数组拼接为字符串
filter {
mutate {
join => { "params" => "," }
}
}
merge
将两个数组合并为1个数组,字符串会被转为1个元素的数组进行操作
filter {
mutate {
merge => { "dest_arr" => "source_arr" }
}
}
rename
将字段重命名
filter {
mutate {
rename => { "HOSTORIP" => "clientip" }
}
}
update/replace
更新字段内容,区别在于 update 只在字段存在时生效,而 replace 在字段不存在时会执行新增字段的操作

remove
删除字段
filter {
mutate {
remove_fiefd => [ "message" ]
}
}
json
将字段内容为json 格式的数据进行解析

geoip
常用的插件,根据 ip 地址提供对应的地域信息,比如经纬度、城市名等,方便进行地理数据分析
filter {
geoip {
source => "ip"
}
}
ruby
最灵活的插件,可以以 ruby 语言来随心所欲的修改 Logstash Event 对象
filter {
ruby {
code => ' size=event.get("description").size;
event. set("description_size", size)'
}
}
Output plugins
负责将 Logstash Event 输出,常见的插件如下:
- stdout
- file
- elasticsearch
stdout
输出到标准输出,多用于调试
output {
stdout {
codec => rubydebug
}
}
file
输出到文件,实现将分散在多地的文件统一到一处的需求,比如将所有web机器的web日志收集到1个文件中,从而方便查阅信息

elasticsearch
输出到 elasticsearch,是最常用的插件,基于http协议实现

实例分析
调试的配置建议
调试阶段建议大家使用如下配置:
- http 做 input,方便输入测试数据,并且可以结合 reload 特性(stdin 无法
- stdout 做 output,codec使用rubydebug,即时查看解析结果
- 测试错误输入情况下的输出,以便对错误情况进行处理

处理的建议
@metadata 特殊字段,其内容不会输出在 output 中
- 适合用来存储做条件判断、临时存储的字段
- 相比 remove_field 有一定的性能提升

实例分析之Apache Logs
- 收集Apache的日志
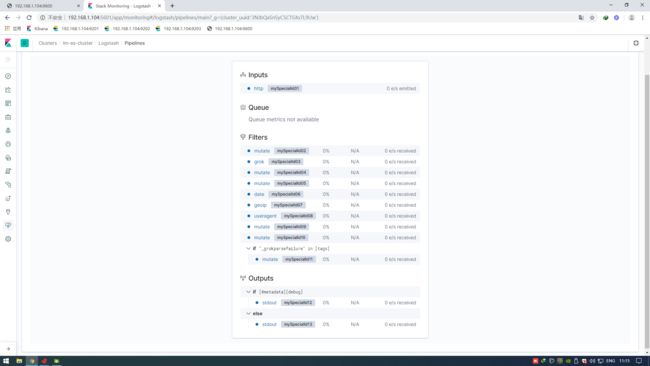
- 编写pipeline文件,注意配置文件中不支持中文注释,每个插件都指定了1个唯一ID,配合x-pack可视化监控
input{
http{
id=>"mySpecialId01"
port=>7474
}
}
filter{
mutate{
id=>"mySpecialId02"
add_field=>{
"[@metadata][debug]"=>true
}
}
grok{
id=>"mySpecialId03"
match=>{
"message"=>'%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:[@metadata][timestamp]}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}'
}
}
mutate{
id=>"mySpecialId04"
copy=>{
"@timestamp"=>"@read_timestamp"
}
}
mutate{
id=>"mySpecialId05"
convert=>{
"bytes"=>"integer"
}
}
date{
id=>"mySpecialId06"
match=>["[@metadata][timestamp]","dd/MMM/yyyy:HH:mm:ss Z"]
}
geoip{
id=>"mySpecialId07"
source=>"clientip"
fields=>["location","country_name","city_name","region_name"]
}
useragent{
id=>"mySpecialId08"
source=>"agent"
target=>"useragent"
}
mutate{
id=>"mySpecialId09"
remove_field=>["headers","message","agent"]
}
mutate{
id=>"mySpecialId10"
add_field=>{
"[@metadata][index]"=>"apache_logs_%{+YYYY.MM}"
}
}
if "_grokparsefailure" in [tags] {
mutate{
id=>"mySpecialId11"
replace=>{
"[@metadata][index]"=>"apache_logs_failure_%{+YYYY.MM}"
}
}
}
}
output{
if [@metadata][debug] {
stdout{
id=>"mySpecialId12"
codec=>rubydebug{metadata=>true}
}
} else {
stdout{
id=>"mySpecialId13"
codec=>dots
}
#elasticsearch{
# index=>"%{[@metadata][index]}"
# document_type=>"_doc"
#}
}
}
- 启动logstash
bin/logstash -f demo_data/apache_logs -r
- POSTMAN发送POST请求
# 请求地址
http://192.168.1.104:7474
# 请求body
36.7.100.223 - - [01/Apr/2018:10:37:19 +0800] "GET / HTTP/1.1" 200 88668 "-" "Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20188181 Firefox/6.8.2"
监控运维建议
logstash提供了丰富的api来查看 logstash 的当前状态
- http://localhost:9600
- http://localhost:9600/_node
- http://localhost:9600/_node/stats
- http://localhost:9600/_node/hot_threads
Monitoring Logstash
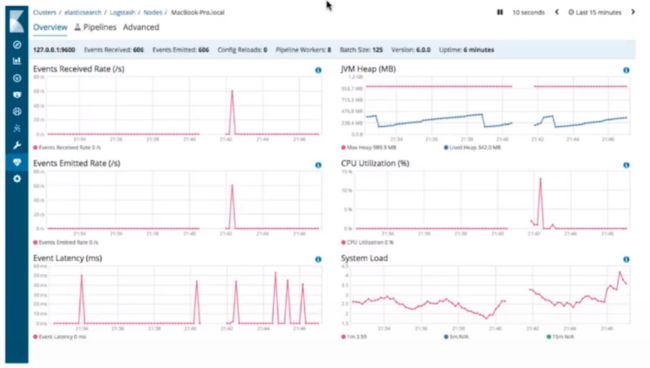
X-Pack monitoring
logstash7.0中,已不需要手动命令安装x-pack
logstash 7.0中开启xpack配置如下:
# 开启xpack监听
xpack.monitoring.enabled: true
# 监听数据传送到es中,填写es的集群地址
xpack.monitoring.elasticsearch.hosts: ["http://192.168.1.104:9201","http://192.168.1.104:9202","http://192.168.1.104:9203"]
使用API方式查看logstash状态并不直观,推荐使用的x-pack方式监控logstash状态。
使用x-pack查看pipeline时,会提示为每个插件指定唯一ID,我们需要为input filter output的每个插件指定1个唯一ID即可。