原文:End-to-End Deep Learning for Self-Driving Cars
翻译:KK4SBB
在最近的一款汽车应用产品中,我们用卷积神经网络(CNNs)将车前部摄像头捕捉到的原始像素图映射为汽车的方向操控命令。这种强大的端到端技术意味着,只需要人们提供少量的训练数据,系统就能自动学会驾驶技术,无论有没有车道标志线,无论是在普通公路还是高速公路。这套系统还可以工作在视线不清晰的区域,比如停车场或者崎岖的道路上。

图1:行驶中的NVIDIA自动驾驶汽车
我们设计的这套端到端学习系统使用了NVIDIA DevBox,用Torch 7进行训练。一台 NVIDIA DRIVE PX 自动驾驶汽车计算机用于判断汽车行驶的方向,工作时它每秒需要处理30帧的数据,同样使用Torch 7处理。这套系统经过训练,自动学会了方向操纵指令的表达,比如检测有效道路的特征,输入的训练信号仅仅只是人工操控方向盘的角度。我们并没有直接训练这个系统来识别道路边界等特征。相反的,不同于直接人工将问题拆解,比如拆解成车道标记检测、线路规划、车辆控制等子任务,我们的端到端系统同时能优化所有的操纵过程。
我们相信应用端到端的学习方法能取得更好的效果,系统也将变得更小巧。效果更好是因为内部组件自动地对系统全局性能做了优化,而不只是优化人们选择的条件标准,比如车道检查。这类可解释的标准虽然易于人的理解,但并不能保证系统处于全局最优状态。更小巧的系统是因为整个系统学习用最少的处理步骤来解决问题。
这篇文章是基于NVIDIA的论文《End to End Learning for Self-Driving Cars》。具体细节可以参考论文原文。
卷积神经网络处理视觉数据
卷积神经网络模型[1]颠覆了计算机模式识别领域[2]。在CNNs被广泛应用前,大多数的识别任务都是先经过人工特征提取步骤,然后用分类器判断。CNNs的重大突破在于它能自动地从训练样本中学习特征。由于卷积运算能够捕捉图像的二维属性,CNN方法在图像识别任务上尤其显得强大。用卷积核扫描整张图片之后,需要学习的参数比原来大大减少。
尽管CNNs模型已经被商业化使用了二十多年[3],但直到近些年才被大规模地应用,这主要是因为两项重要的突破。首先,大规模的人工标注数据集很容易获取,比如ImageNet大规模视觉识别挑战(ILSVRC)[4],这些数据可以作为训练集和验证集。其次,CNN学习算法现在能够在大规模并行图形处理单元(GPUs)上运行,极大地提高了学习效率和预测能力。
我们这里所讲述的CNNs模型不局限于基本的模式识别。我们开发了一套系统,可以学习自动驾驶汽车的整个工作流程。这个项目的基础工作十年前在国防高级研究项目机构(Defense Advanced Research Projects Agency,DARPA )的自动化车辆项目中就已经完成,这个项目被称为DAVE[5],此项目中一辆微缩的遥控车行驶通过摆放了障碍物的小路。DAVE使用在了类似环境下采集的若干个小时的人工驾驶数据进行训练,但环境并不完全相同。训练数据包括两台摄像机采集的视频数据和人操控方向的命令。
在许多方面,DAVE的灵感都来自于Pomerleau开创性的工作[6],Pomerleau在1989年用神经网络搭建了一套自动驾驶系统(Autonomous Land Vehicle in a Neural Network,ALVINN)。ALVINN是DAVE的先驱产品,它首次证实了端到端训练的神经网络模型终将在某一天能够操控汽车行驶在公路上。DAVE展示了端到端的学习潜能,而且它还用来证明DARPA Learning Applied to Ground Robots 项目的启动,但是DAVE的性能不足够可靠,在非公路环境下不能完全替代多模块方式的驾驶。(在复杂环境下,DAVE在碰撞之间的平均距离约有20米。)
大约在一年之前我们开始重新着力于提升原始版DAVE的性能,构建一套能够在公路上驾驶的强健系统。这项工作的初始动机是为了避免识别特定的人工设计特征标志,比如车道标记、隔离护栏和其它车辆,也避免基于这些观察到的特征指定一套“如果……那么……否则……”的规则系统。我们很高兴能够分享这一新的努力的初步结果,即DAVE-2。
DAVE-2系统
图2展示了DAVE-2系统的训练数据采集模块的块状示意图。数据采集车的挡风玻璃后面固定了三台摄像机,在摄像机采集视频数据的同时,此系统也记录驾驶员操控方向盘的偏转角度。方向控制命令是从汽车的控制网络(Controller Area Network,CAN)总线获取。为了使我们的系统能够独立于汽车的几何尺寸,我们用1/r来表示方向控制命令,其中r是以米为单位的转弯半径。我们使用1/r而不是r的目的是防止在直线行驶时出现奇点(直线行驶的转弯半径无限大)。左转弯的1/r值为负数,右转弯的值为正数。
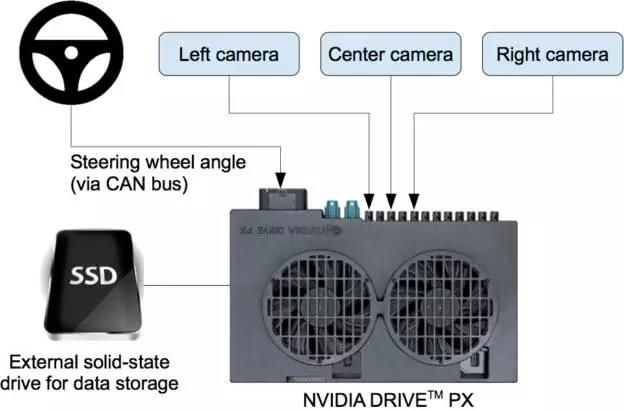
训练数据包括从视频中采样得到的单帧视频,以及对应的方向控制命令(1/r)。只用驾驶员操作的数据训练远远不够;网络模型还需要学习如何纠正错误的操作,否则汽车就会慢慢偏离公路了。于是,训练数据额外补充了大量图像,包括汽车从车道中心的各种偏移和转弯。
两个特定的偏离中心的图像可以从左和右两台相机得到。摄像机之间的其它偏离以及所有的旋转都靠临近摄像机的视角变换来仿真。精确的视角转换需要具备3D场景的知识,而我们却不具备这些知识,因此我们假设所有低于地平线的点都在地平面上,所有地平线以上的点都在无限远处,以此来近似地估计视角变换。在平坦的地区这种方法没问题,但是对于更完整的渲染,会造成地面上物体的扭曲,比如汽车、树木和建筑等。幸运的是这些扭曲对网络模型训练并无大碍。方向控制会根据变换后的图像迅速得到修正,使得汽车能在两秒之内回到正确的位置和方向。
图3是我们的训练系统。图像输入到CNN网络计算方向控制命令。预测的方向控制命令与理想的控制命令相比较,然后调整CNN模型的权值使得预测值尽可能接近理想值。权值调整是由机器学习库Torch 7的后向传播算法完成。

图3:训练神经网络模型
训练完成后,模型可以用中心的单个摄像机数据生成方向控制命令。图4显示了这个过程。
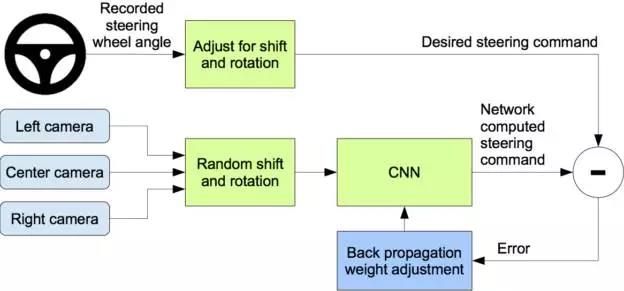
图4:训练得到的模型可以用正前方的单个摄像机的数据生成方向控制命令。
数据采集
训练数据是在各种路段和不同灯光和天气条件下采集得到的。我们在新泽西州中部采集街道路面数据,在伊利诺伊、密歇根、宾夕法尼亚和纽约州采集高速公路的数据。其它道路类别包括两车道道路(有车道标志或者没有标志),路边有车停放的居民区道路,隧道和不平整道路。采集数据时的天气状况有晴天、多云、雾天、雪天和雨天,白天和晚上都有。在某些情况下,太阳接近地平线,导致有路面反射的光线和挡风玻璃的散射。
我们采集数据的车辆是2016款 Lincoln MKZ,或者2013款Ford Focus,后者摄像头的安放位置与前者相似。我们的系统不依赖与任何的汽车制造商或是型号。我们要求驾驶员尽可能地集中注意力。截止2016年3月28日,共采集了72小时的行驶数据。
网络结构
我们训练网络的权重值,使得网络模型输出的方向控制命令与人工驾驶或者调整后的控制命令的均方误差最小。图5是网络的结构图,一共包括九层,包括一个归一化层,五个卷积层和三个全连接层。输入图像被映射到YUV平面,然后传入网络。
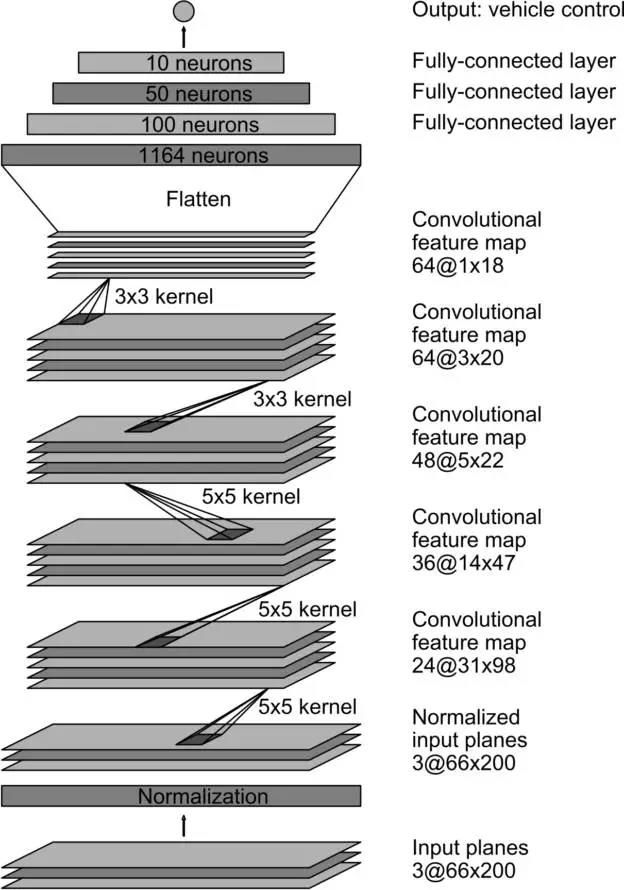
图5:CNN结构。这个网络有大约2700万个连接和25万个参数。
网络的第一层对输入图像做归一化。归一化层是硬编码的,在学习过程中不会变化。在网络模型中进行归一化可以使得归一化过程根据网络结构调整,而且能用GPU加速处理过程。
卷积层是用来提取特征的,它是根据一些列参数实验的结果凭经验选择的。然后我们对前三个卷积层使用了strided卷积,其中stride是2x2,卷积核是5x5,后两层选用了unstrided卷积,卷积核是3x3。
在五层卷积之后又接了三个全连接层,最后输出一个控制数字,即转弯半径的倒数。全连接层的设计意图是作为方向控制器,但是我们发现用端到端的方式训练系统,网络模型的特征提取器和控制器这两部分很难明确地区分开来。
训练细节
数据选择
训练神经网络的第一步就是选择使用视频的哪些帧。我们采集的数据标记了道路类型、天气条件、驾驶员行为(保持车道行驶、更换车道、转弯等等)等标签。用CNN训练保持车道的行驶,我们就只挑选驾驶员保持同一车道行驶的数据,抛弃剩余部分。然后我们以10FPS对视频降采样,因为用高采样率得到的图像相似度非常高,并不能带来很多有用的信息。为了消除直线行驶的偏置,很大一部分训练图像包含了有弧度的道路。
数据补充
选定最终的图像集之后,我们人工添加了一些偏移和旋转来补充数据,教会网络如何修复较差的姿势和视角。调整的幅度按照正态分布随机选取。分布的均值为零,标准差是驾驶员操作数据的标准差的两倍。人工补充的数据随着幅度的增加确实会引入一些不理想的因素(正如我们之前提到的)。
仿真
在上路测试训练得到的CNN之前,我们首先仿真测试网络的性能。图6是简化的仿真系统,图7是交互式仿真器的界面截图。
图6:驾驶仿真器的示意图。
仿真器采用预先用数据采集车的前置摄像机录制的视频数据,然后根据图像用CNN模型预测操控命令。这些录制视频的时间轴与驾驶员操控命令的时间轴保持一致。
由于驾驶员不总是将车辆保持在车道的中心,我们必须人工校准车道的中心,因为它与模拟器所采用的视频的每一帧都关联。我们把这个姿态称为“对照数据”。
模拟器对原始图像做了变形来模仿车辆偏离对照姿态。请注意,这种变形也包括了驾驶员行驶路径与对照数据之间的任何差异。图像变形的方法在前几节已经介绍过了。
模拟器读取保存的测试视频,以及与拍摄视频同步记录的方向控制命令。该模拟器发送所选择的测试视频的第一帧,针对任何偏离对照数据的情况做修正,然后输入到训练好的CNN模型,模型输出一条操控指令。模型输出的命令与存储的驾驶员操控命令一起被送入车辆的动态模型,更新仿真车辆的位置和方向。
图7:模拟器交互模式的截图。右侧是操纵性能的文字描述评价。左侧绿色区域是由于视角变换导致的不可见区域。地平线下方明亮的矩形区域就是传入CNN模型的图像。
接着,模拟器调整测试视频的下一帧图像,使得所呈现的图像如同是CNN模型输出的操纵命令所控制的结果。新的图像又被传回CNN模型,重复处理过程。
模拟器记录车辆偏离距离(车辆偏离车道中心的距离),偏航角度和仿真车辆的行驶距离。当偏离中心的距离超过一米时,就会触发虚拟人的干预,仿真车辆的位置和方向就会重置成原视频对应帧的对照数据。
评测
我们分两步来评测我们的网络模型:首先是仿真测试,接着是上路测试。
在仿真阶段,我们使用了在新泽西州蒙茅斯县录制的视频数据,总共大约持续三个小时,行驶了100英里。测试数据在各种灯光和天气条件下采集,包括了高速公路、普通公路和居民区道路。
我们通过计算虚拟人干预车辆行驶的次数来估计网络模型能够自动驾驶汽车的时间段占比。我们假设在现实情况下发生一次人工干预需要六秒:这个时间包括驾驶员接管操纵车辆、纠正车辆位置、重新进入自动驾驶模式。我们是这样计算自动驾驶比例的,把人工干预的次数乘以六秒,除以总的模拟时间,然后与1相减:
因此,如果触发了100次干预耗时600秒,自动驾驶的比例为
上路测试
当网络模型训练得到较好的性能之后,我们把它加载到测试车辆的DRIVE PX上,进行上路测试。我们用车辆自动驾驶的时间比例来衡量性能。这个时间不包括变换车道和转弯。以我们位于霍姆德尔的办公室到大西洋高地的一趟普通行程为例,大约有98%的时间保持自动驾驶。我们也在花园州际公路(一条有坡度的多车道高速公路)上完成了10英里的自动驾驶。
视频:https://youtu.be/NJU9ULQUwng(自备云梯)
CNN模型内部状态可视化
图8和图9分别展示了两张不同输入图片在前两层网络的激活状态,分别是在土路上和森林里。在土路的例子中,特征图片清晰地勾画出路的边界,而在森林的例子中夹杂了大量噪音,CNN模型从图中找不到有用的信息
这表明CNN自动学会了识别有用的道路特征,只提供人工操控方向的角度作为训练信号。我们从未直接训练模型来识别道路边界。
图8:CNN模型眼中的土路。上方:由摄像机输入CNN模型的图像。左下:第一层特征映射的激活状态。右下:第二层特征映射的激活状态。
图9:没有路的图片示例。前两层特征映射几乎都是噪声,CNN模型无法从图片中识别出有用的特征。
总结
我们的经验表明,神经网络能学习完整的保持车道驾驶的任务,而不需要人工将任务分解为道路和车道检测、语义抽象、道路规划和控制。从不到一百小时的少量训练数据就足以训练在各种条件下操控车辆,比如在高速公路、普通公路和居民区道路,以及晴天、多云和雨天等天气状况。CNN模型可以从非常稀疏的训练信号(只有方向控制命令)中学到有意义的道路特征。
例如,系统不需要标注数据就学会了识别道路边界。
还需要做大量工作来提升网络模型的健壮性,寻找验证系统健壮性的方法,以及提升网络内部状态可视化的程度。
参考文献
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backprop- agation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989. URL:http://yann.lecun.org/exdb/publis/pdf/lecun-89e.pdf.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012. URL: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
L. D. Jackel, D. Sharman, Stenard C. E., Strom B. I., , and D Zuckert. Optical character recognition for self-service banking. AT&T Technical Journal, 74(1):16–24, 1995.
Large scale visual recognition challenge (ILSVRC). URL: http://www.image-net.org/challenges/LSVRC/.
Net-Scale Technologies, Inc. Autonomous off-road vehicle control using end-to-end learning, July 2004. Final technical report. URL: http://net-scale.com/doc/net-scale-dave-report.pdf.
Dean A. Pomerleau. ALVINN, an autonomous land vehicle in a neural network. Technical report, Carnegie Mellon University, 1989. URL: http://repository.cmu.edu/cgi/viewcontent. cgi?article=2874&context=compsci.
Danwei Wang and Feng Qi. Trajectory planning for a four-wheel-steering vehicle. In Proceedings of the 2001 IEEE International Conference on Robotics & Automation, May 21–26 2001. URL:http://www.ntu.edu.sg/home/edwwang/confpapers/wdwicar01.pdf.