接下来这篇是查询优化,用户80%的操作基本都在查询,我们有什么理由不去优化他呢??所以这篇博客将会讲解大量的查询优化(索引以及库表结构优化等高级用法后面文章再讲),先讲单表查优化,再讲多表查优化。
本系列:demo下载
(一)MySQL优化笔记(一)--库与表基本操作以及数据增删改
(二)MySQL优化笔记(二)--查找优化(1)(非索引设计)
(三)MySQL优化笔记(二)--查找优化(2)(外连接、多表联合查询以及查询注意点)
(四) MySQL优化笔记(三)--索引的使用、原理和设计优化
(五) MySQL优化笔记(四)--表的设计与优化(单表、多表)
(六)MySQL优化笔记(五)--数据库存储引擎
(七)MySQL优化笔记(六)--存储过程和存储函数
(八)MySQL优化笔记(七)--视图应用详解
(九) MySQL优化笔记(八)--锁机制超详细解析(锁分类、事务并发、引擎并发控制)
文章结构:(1)明确搜索优化的整体思路以及查询优化的因素;(2)优化查询前的几个工具说明;(3)单表查询步步优化;
文章目录:
(1)明确搜索优化的整体思路以及查询优化的因素
- 搜索优化的整体思路
- 查询优化的因素思路
- 是否向数据库请求了不需要的数据
- mysql是否扫描额外的纪录
- 查询方式
- 一个复杂查询 or 多个简单查询
- 切分查询
- 分解关联查询 - 查询的流程(站在后端开发者角度)。
(2)优化查询前的几个工具说明
- 查看MySQL整体状态
- 开启慢查询日志
- 在配置文件my.cnf或my.ini中在[mysqld]一行下面加入两个配置参数
- 查看日志启动状态
- 设置慢日志开启
- 查询long_query_time 的值
- 为了方便测试,可以将修改慢查询时间为3秒
- 以后就往我们设置的日志路径去访问日志即可 - explain查询分析
- profiling查询分析
(3)单表查询步步优化:(暂不讨论索引,在下篇文章再详解索引)
- 明确需要的字段,要多少就写多少字段
- 使用分页语句:limit start , count 或者条件 where子句
- 如果是有序的查询,可使用ORDER BY
- 开启查询缓存
- 建立索引(下篇博客再详讲)
数据库文件依然是: 数据库文件,这篇主要看商品表
一、明确搜索优化的整体思路以及查询优化的因素:
(1)搜索优化的整体思路:
索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等。对于一个整体项目而言只有这些齐头并进,才能实现mysql高性能。
(2)查询优化的因素思路:
[一]是否向数据库请求了不需要的数据。
也就是说不要轻易使用select * from ,能明确多少数据就查多少个
[二]mysql是否扫描额外的纪录
查询是否扫描了过多的数据。最简单的衡量查询开销三个指标如下:响应时间;扫描的行数;返回的行数。
没有哪个指标能够完美地衡量查询的开销,但它们大致反映了mysql在内部执行查询时需要多少数据,并可以推算出查询运行的时间。
这三个指标都会记录到mysql的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法。
响应时间:是两个部分之和:服务时间和排队时间。服务时间是指数据库处理这个查询真正花了多长时间。 排队时间是指服务器因为等待某些资源而没有真正执行查询的时间。---可能是等io操作完成,也可能是等待行锁,等等。
扫描的行数和返回的行数:分析查询时,查看该查询扫描的行数是非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。
扫描的行数和访问类型: 在expain语句中的type列反应了访问类型。访问类型有很多种,从全表扫描(ALL)到索引扫描(index)到范围扫描()到唯一索引查询到常数引用等。这里列的这些,速度由慢到快,扫描的行数也是从大到小。
如果发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
使用索引覆盖扫描。
改变库表结构。例如使用单独的汇总表。
重写这个复杂的查询。让mysql优化器能够以更优化的方式执行这个查询。
[三]查询方式:
1. 一个复杂查询 or 多个简单查询
设计查询的时候一个需要考虑的重要问题是,是否需要将一个复杂的查询分成多个简单的查询。
2.切分查询
有时候对于一个大查询我们需要“分而治之”,将大查询切分为小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
3.分解关联查询
分解关联查询
select * from tag
join tag_post on tag_post.tag_id = tag.id
join post on tag_post.post_id = post.id
where tag.tag = 'mysql'
可以分解成下面这些查询来代替:
> select * from tag where tag = 'mysql'
> select * from tag_post where tag_id = 1234
> select * from post where post_id in (123, 456, 567, 9098, 8904)
让缓存的效率更高。
将查询分解后,执行单个查询可以减少锁的竞争。
在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展。
查询本身效率也可能会有所提升。
可以减少冗余记录的查询,
更进一步,这样做相当于在应用中实现了哈希关联,而不是使用mysql的嵌套循环关联。
(3)查询的流程(站在后端开发者角度):摘自此博主此文章
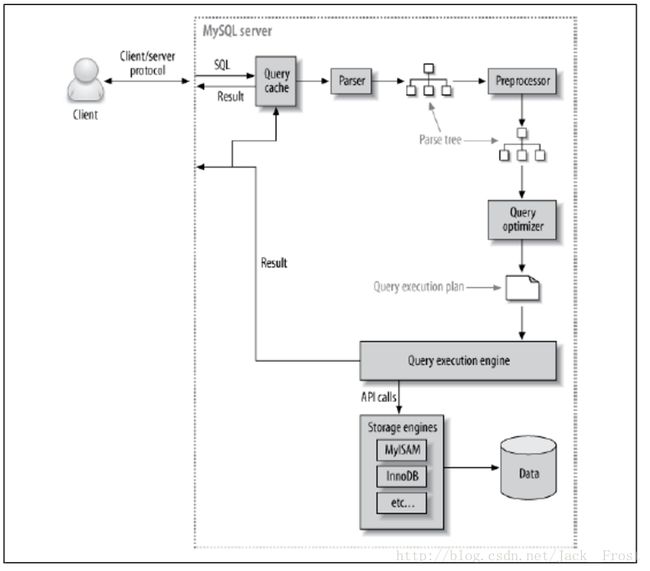
这里写图片描述
1.客户端发送一条查询给服务器
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果,否则进入下一阶段。
3.服务器进行SQL解析,预处理,再由优化器生成对应的执行计划,
4.mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5.将结果返回给客户端。
二、优化查询前的几个工具说明:
(1)查看MySQL整体状态:
1. Mysql> show status; ——显示状态信息(扩展show status like ‘XXX’)
2. Mysql>show variables ——显示系统变量(扩展show variables like ‘XXX’)
3. Mysql>show innodb status ——显示InnoDB存储引擎的状态
4. Mysql>show processlist ——查看当前SQL执行,包括执行状态、是否锁表等
5. Shell> mysqladmin variables -u username -p password——显示系统变量
6. Shell> mysqladmin extended-status -u username -p password——显示状态信息
7. Shell> mysqld –verbose –help [|more #逐行显示] 查看状态变量及帮助:
(2)开启慢查询日志:
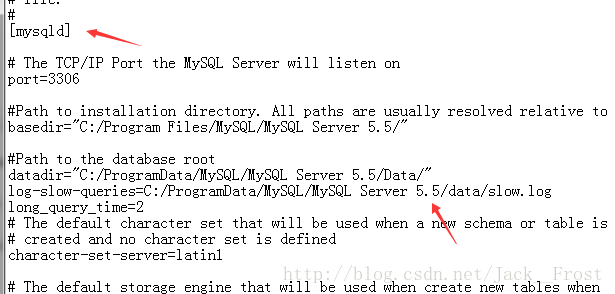
这里写图片描述
1. 在配置文件my.cnf或my.ini中在[mysqld]一行下面加入两个配置参数
log-slow-queries={自己想存放的日志路径}/slow-query.log
long_query_time=2
注:log-slow-queries参数为慢查询日志存放的位置,一般这个目录要有mysql的运行帐号的可写权限,一般都将这个目录设置为mysql的数据存放目录;
long_query_time=2中的2表示查询超过两秒才记录;
在my.cnf或者my.ini中添加log-queries-not-using-indexes参数,表示记录下没有使用索引的查询。
log-slow-queries=/data/mysqldata/slow-query.log
long_query_time=10
log-queries-not-using-indexes
2. 查看日志启动状态:show variables like "slow%";

这里写图片描述
3. 设置慢日志开启: set global slow_query_log = ON;
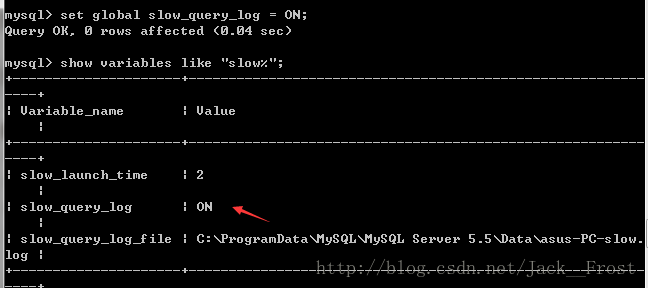
这里写图片描述
4. 查询long_query_time 的值 :
show variables like "long%";
5. 为了方便测试,可以将修改慢查询时间为3秒。(小点容易比较,毕竟mysql处理那么快)

这里写图片描述
6.以后就往我们设置的日志路径去访问日志即可:
more slow.log
(3)explain查询分析:
使用 EXPLAIN 关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。通过explain命令可以得到:
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
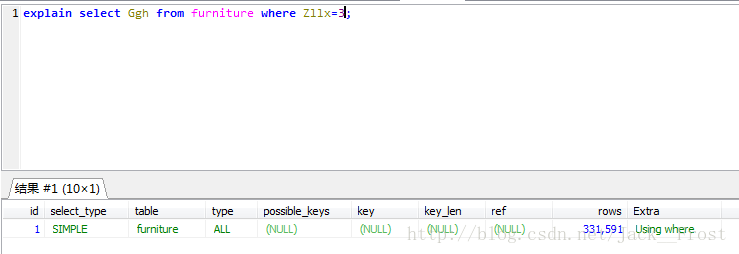
这里写图片描述
EXPLAIN查询出来的字段解析:
?Table:显示这一行的数据是关于哪张表的
?possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
?key:实际使用的索引。如果为NULL,则没有使用索引。MYSQL很少会选择优化不足的索引,此时可以在SELECT语句中使用USE INDEX(index)来强制使用一个索引或者用IGNORE INDEX(index)来强制忽略索引
?key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
?ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
?rows:MySQL认为必须检索的用来返回请求数据的行数
?type:这是最重要的字段之一,显示查询使用了何种类型。从最好到最差的连接类型为system、const、eq_reg、ref、range、index和ALL
nsystem、const:可以将查询的变量转为常量. 如id=1; id为 主键或唯一键.
neq_ref:访问索引,返回某单一行的数据.(通常在联接时出现,查询使用的索引为主键或惟一键)
nref:访问索引,返回某个值的数据.(可以返回多行) 通常使用=时发生
nrange:这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西,并且该字段上建有索引时发生的情况(注:不一定好于index)
nindex:以索引的顺序进行全表扫描,优点是不用排序,缺点是还要全表扫描
nALL:全表扫描,应该尽量避免
?Extra:关于MYSQL如何解析查询的额外信息,主要有以下几种
nusing index:只用到索引,可以避免访问表.
nusing where:使用到where来过虑数据. 不是所有的where clause都要显示using where. 如以=方式访问索引.
nusing tmporary:用到临时表
nusing filesort:用到额外的排序. (当使用order by v1,而没用到索引时,就会使用额外的排序)
nrange checked for eache record(index map:N):没有好的索引.
(4)profiling查询分析:
通过慢日志查询可以知道哪些SQL语句执行效率低下,通过explain我们可以得知SQL语句的具体执行情况,索引使用等,还可以结合show命令查看执行状态。
如果觉得explain的信息不够详细,可以同通过profiling命令得到更准确的SQL执行消耗系统资源的信息。
profiling默认是关闭的。可以通过以下语句查看: select @@profiling;
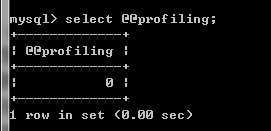
这里写图片描述
打开profiling查询分析:set profiling = 1;

这里写图片描述
然后我们随便写几条select语句,再查看:show profiles\G;
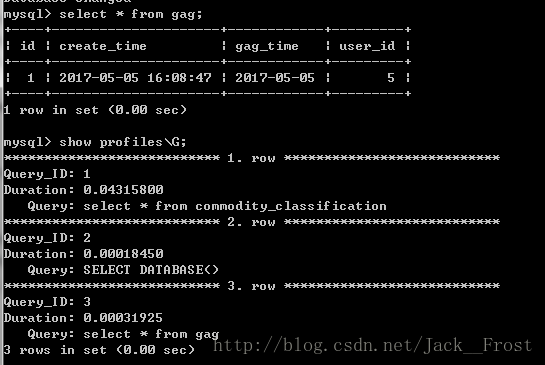
这里写图片描述
mysql> show profiles\G; 可以得到被执行的SQL语句的时间和ID
mysql>show profile for query 1; 得到对应SQL语句执行的详细信息
Show Profile命令格式:
SHOW PROFILE [type [, type] … ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type参数:
|ALL
| BLOCK IO
| CONTEXT SWITCHES
| CPU
| IPC
| MEMORY
| PAGE FAULTS
| SOURCE
| SWAPS
以上的16rows是针对非常简单的select语句的资源信息,对于较复杂的SQL语句,会有更多的行和字段,比如converting HEAP to MyISAM 、Copying to tmp table等等,由于以上的SQL语句不存在复杂的表操作,所以未显示这些字段。通过profiling资源耗费信息,我们可以采取针对性的优化措施。
测试完毕以后 ,关闭参数:mysql> set profiling=0
三、单表查询步步优化:(暂不讨论索引,在下篇文章再详解索引)
(我们继续看上面所用的商品表)
//最傻的查询方式
select * from commodity_list
(1)明确需要的字段,要多少就写多少字段:
select d.Good_ID ,
d.Classify_ID,
d.Good_Name,
d.Monthsale_Num,
d.Store_Name,
d.Comment_Num,
d.Good_Brand,
d.Ishas_License,
ifnull(d.Good_Hot,0),
d.Good_Price,
d.Store_Add,
d.Store_Age,
d.Seller_Credit,
d.Classify_Description
from
Commodity_list d;
(2)使用分页语句:limit start , count 或者条件 where子句
有什么可限制的条件尽量加上,查一条就limit一条。做到不多拿不乱拿。
明确子句的执行顺序先:
SELECT select_list
FROM table_name
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
[ ORDER BY order_expression [ ASC | DESC ] ]
[limit m,n]
例子:
select
d.Good_ID ,
d.Classify_ID,
d.Good_Name,
d.Monthsale_Num,
d.Store_Name,
d.Comment_Num,
d.Good_Brand,
d.Ishas_License,
ifnull(d.Good_Hot,0),
d.Good_Price,
d.Store_Add,
d.Store_Age,
d.Seller_Credit,
d.Classify_Description
from
Commodity_list d
where Classify_ID=23
limit 1,10000
;
补充:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
对limit分页性能优化分析:
偏移量越大,查询越费时。
原因:
- 每条数据的实际存储长度不一样(所以必须要依次遍历,不能直接跳过前面的一部分)
- 哪怕是每条数据存储长度一样,如果之前有过delete操作,那索引上的排列就有gap
- 所以数据不是定长存储,不能像数组那样用index来访问,只能依次遍历,就导致偏移量越大查询越费时
**对limit的使用再优化 **:
利用自增主键,避免offset的使用(演示在积分表score,商品表设计得不太好),约是上面方法的1/3时间。
select *
from
score
WHERE id>0 LIMIT 10000
;
select *
from
score
WHERE id>10000 LIMIT 10000
;
select *
from
score
WHERE id>20000 LIMIT 10000
;
......
(3)如果是有序的查询,可使用ORDER BY
select *
from
score
WHERE id>0
ORDER BY score ASC
LIMIT 10000
;
(4)开启查询缓存:部分摘自此博主此博客
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
命中缓存条件:
1)缓存存在一个hash表中,通过查询SQL,查询数据库,客户端协议等作为key.在判断是否命中前,MySQL不会解析SQL,而是直接使用SQL去查询缓存,SQL任何字符上的不同,如空格,注释,都会导致缓存不命中.
2)如果查询中有不确定数据,例如CURRENT_DATE()和NOW()函数,那么查询完毕后则不会被缓存.所以,包含不确定数据的查询是肯定不会找到可用缓存的
工作流程:
1)服务器接收SQL,以SQL和一些其他条件为key查找缓存表(额外性能消耗)
2)如果找到了缓存,则直接返回缓存(性能提升)
3)如果没有找到缓存,则执行SQL查询,包括原来的SQL解析,优化等.
4)执行完SQL查询结果以后,将SQL查询结果存入缓存表(额外性能消耗)
缓存使用的时机:(并不是每个情况使用缓存都是好的)
衡量打开缓存是否对系统有性能提升是一个整体的概念。
1)通过缓存命中率判断, 缓存命中率 = 缓存命中次数 (Qcache_hits) / 查询次数 (Com_select)、
2)通过缓存写入率, 写入率 = 缓存写入次数 (Qcache_inserts) / 查询次数 (Qcache_inserts)
3)通过 命中-写入率 判断, 比率 = 命中次数 (Qcache_hits) / 写入次数 (Qcache_inserts), 高性能MySQL中称之为比较能反映性能提升的指数,一般来说达到3:1则算是查询缓存有效,而最好能够达到10:1
缓存参数配置:
1)query_cache_type: 是否打开缓存:
可选项:OFF: 关闭;ON: 总是打开;DEMAND: 只有明确写了SQL_CACHE的查询才会吸入缓存
2)query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关)
3)query_cache_min_res_unit: 分配内存块时的最小单位大小
4)query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果
5)query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
6)缓存的一些整体参数:
Qcache_free_blocks: 缓存池中空闲块的个数
Qcache_free_memory: 缓存中空闲内存量
Qcache_hits: 缓存命中次数
Qcache_inserts: 缓存写入次数
Qcache_lowmen_prunes: 因内存不足删除缓存次数
Qcache_not_cached: 查询未被缓存次数,例如查询结果超出缓存块大小,查询中包含可变函数等
Qcache_queries_in_cache: 当前缓存中缓存的SQL数量
Qcache_total_blocks: 缓存总block数